推荐算法详细讲解python(深度解析开源推荐算法框架)
随着移动app的普及,个性化推荐和广告成为很多app不可或缺的一部分。他们在改善用户体验和提升app的收益方面带来了巨大的提升。深度学习在搜广推领域的应用也已经非常深入,并且给各种场景的效果带来了巨大的提升。针对推荐流程的各个阶段,业界已经有很多的模型,这些模型大部分也有开源的实现,但是这些实现通常散落在github的各个角落,其数据处理和特征构造的方式各有差异。如果我们想要在一个新的场景里面应用这些模型,通常需要做比较多的改动:
- 输入的改造,开源的实现的输入格式和特征构造通常和线上不一致,适配一个算法通常需要1-2周左右的时间,还难免因为对代码的不熟悉引入bug,如果要尝试5个算法的话,就需要5倍的改造时间。如果算法资源有限,这时候是不是就要忍痛割爱,放弃一些可能有效果的尝试了?
- 开源的实现很多只是在公开数据集上取得了比较好的效果,在公开数据集上的最优参数也不一定适合实际的场景,因此参数调优也需要较大的工作量;有时候效果不好,并不是因为方法不行,而是选的参数不太好。如果没有系统化的调参方法,很多算法也就是简单试一下,没有deep explore,哪来对算法的深入理解呢? 为什么看似简单的改进,你没有能够发现呢? 为什么你也尝试了类似的方向,但是没有搞出来效果呢? 效果通常都是用算力和数不尽的尝试堆出来的;
- 开源的实现用的是Tensorflow 1.4,而线上用的tensorflow 2.3,好多函数的参数都变掉了(此处心里是不是想骂google一百遍,当初信誓旦旦说好的api不再变呢); 很多开源的实现由于没有在实际场景中验证过,所以其可靠性也是存疑的,可能就会少了个dropout,少了一个bn,效果相差甚远;
- 费了九牛二虎之力把模型效果调好了,发现上线也会有很多问题,比如训练速度太慢、内存占用太大、推理qps跟不上、离线效果好在线效果跪等等。遇到这么多问题,你还有精力去做你的下一个idea吗?你还能斗志昂扬,坚持不懈的去探索新方向吗?
这些问题搞得我们心有余而力不足、天天加班到深夜、不知何时是个头:想要验证一个简单的idea都要使出九牛二虎之力。所谓天下武功,唯快不破,对于搜广推领域的算法同学来说,尤其如此:通过快速迭代才能验证更多的想法,发现更多的问题,找出最优的特征和模型结构。速度慢了的话,可能你的模型还没调好,业务目标就变了,前端的布局也改了,你的业务方可能都不相信你了,你也就没机会上线了。
说到这里,我们的诉求就比较明确了,我们就是想少写代码,甚至不写代码就能验证我们的想法。针对这些问题和诉求,我们推出一个全新的、一步到位的推荐建模框架,致力于帮助大家解决在推荐建模、特征构造、参数调优、部署等方面的问题,让大家少写代码,少干重复的没有意义的脏活累活(这些EasyRec都承包了),少趟一些坑少踩一些雷(这些EasyRec都替你趟了),让大家能够快速上线验证新的idea,提升推荐模型的迭代效率。
优势

和其他建模框架相比,EasyRec在以下几个方面具备显著的优势:
- 支持多平台和多数据源训练
- 支持的平台包括: MaxCompute(原ODPS), DataScience(基于Kubernete), DLC(deep learning container), Alink, 本地;
- 支持的数据源包括: OSS, HDFS, HIVE, MaxCompute Table, Kafka, Datahub;
- 用户通常只需要定义自己的模型,在本地测试通过后,就可以在多种分布式平台上进行训练;
- 支持多种tensorflow版本(>=1.12, <=2.4, PAI-TF),能够无缝的对接用户的环境,不需要对代码做迁移和改动;
- 支持主流的特征工程的实现,特别是显示交叉特征,能够显著得提升效果;
- 支持HPO自动调参,显著降低了用户的调参工作量,并在多个场景中提升了模型效果;
- 实现了主流的深度模型,覆盖召回、排序、粗排、重排、多目标、多兴趣等;
- 支持EarlyStop, BestExport, 特征重要性,特征选择、模型蒸馏等高级功能。
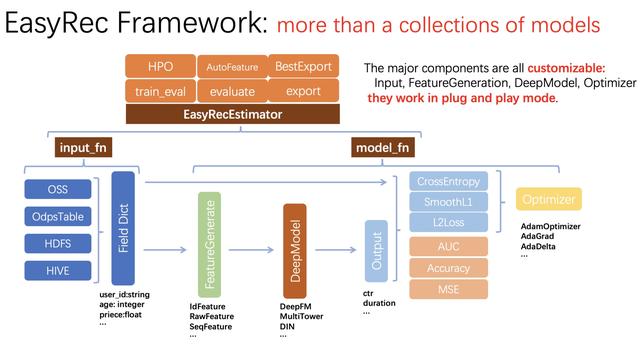
EasyRec建模框架整体上是基于Estimator的数据并行训练方式,通过Parameter Server的结构支持多机多卡的训练。EasyRec的主要模块包括输入、特征构造、深度模型、Loss和Metric,每个模块都可以自定义。针对用户在用TF进行训练可能遇到的多种问题,如worker退出失败、使用num_epoch evaluator无法退出、auc计算不准确等,EasyRec做了深度优化。针对AdamOptimizer训练速度慢,异步训练慢机,hash冲突,大样本空间负采样等问题,EasyRec结合PAI TF(PAI优化过的tensorflow)和AliGraph也做了深度优化。
模型EasyRec内置了业界先进的深度学习模型, 覆盖了推荐全链路的需求,包括召回、粗排、排序、重排、多目标、冷启动等。

同时EasyRec也支持用户自定义模型。如下所示,在EasyRec里面实现自定义模型,只需要定义模型结构、Loss、Metric三个部分,数据处理和特征工程是可以直接复用框架提供的能力的,因此能够显著节省用户的建模时间和成本,能够将精力focus在模型结构的探索上。针对常见的模型类型如RankModel、MultiTaskModel等,Loss和Metric部分也可以直接复用父类的定义。

EasyRec自动调参接入了PAI automl自动调参的能力,实现了对多种参数的自动调优。EasyRec里面定义的任意参数都是可以搜索的,常见的参数包括hash_bucket_size, embedding_dim, learning_rate,dropout, batch_norm, 特征选择等。当你对某些参数拿不准时,就可以启动自动调参来帮助你寻找最优的设置;通过自动寻优得到的参数通常会比拍脑袋设置的参数要好,有时候还会带来意外的惊喜。
特征工程通常是提升推荐效果的关键,做高阶的特征组合通常有助于提升模型效果,但是高阶组合的空间非常大,无脑组合会导致特征爆炸,拖累训练和推理的速度。因此,EasyRec引入了自动特征工程(AutoFeature)的能力,自动寻找有提升的高阶特征,进一步提升模型的效果。

搜索结果(top5):

EasyRec模型可以一键部署到PAI EAS环境,也可以通过tf serving部署。为了提升inference性能,EasyRec引入了PAI Blade的能力做placement优化,op fusion,子图去重等功能,通过上述优化qps提升30%以上,rt下降50%。未来还将引入FP16的功能,进一步提升inference性能,降低memory的消耗。为了支持超大规模的Embedding,EasyRec对大模型做了拆分和op替换,将Embedding存储到redis等分布式缓存里面,突破了内存的限制。从Redis获取embedding会比内存慢,通过对高频id进行cache等来降低对redis的访问来提升embedding lookup的速度。

特征工程是搜广推流程里面的关键部分,也通常是造成线上线下效果不一致的原因。为了能够在快速迭代中保持离线在线的一致性,通常采用的方法是线上线下采用同一套代码。离线训练数据的构造流程:首先构造user feature(包含实时和离线两部分), item feature和context_feature,然后join上训练样本(包含label),最后经过特征工程的jar包生成输入EasyRec的训练样本。上线的流程:将user feature(离线部分)和item feature导入Redis、Hologres等分布式存储,推荐引擎根据user_id和item_id去查询对应的特征,调用特征工程的库进行加工之后,送入EasyRec模型预测。在线部分的实时特征通常是使用blink、alink等支持流式计算的平台来生成的,而离线部分的实时特征构造有两种方式:离线模拟和在线落特征。这两种方式各有优缺点:由于日志丢失等问题,离线模拟通常会和线上有少量的不一致;在线落特征如果要增加新的特征通常要等待比较长的时间才能攒够样本。我们的解决方案是在线将用户行为的序列落下来,然后离线通过相同的jar包来加工出各种统计特征,如1h/2h/../24h的点击次数。
在线特征工程对计算效率要求比较高,而计算量也比离线要大:离线计算的样本通常是1个user配对m个曝光的item(召回模型的话,会增加一些随机采样的负样本), 而线上计算的样本是1个user配对n个item(n>>m)。在线计算如果采用naive的计算方式,将一次请求展开成n个样本分别进行计算,效率通常是跟不上的。不难发现其中user feature的部分做了比较多的重复计算,对user feature做计算效率的优化,能够显著提升线上的qps。 我们结合淘系内部使用的Feature Generation模块做了深度优化,包括内存分配、字符串解析、重复计算消除、多线程并行计算等,在保证一致性的前提下,显著提高了计算的效率。

增量训练通常能够带来效果的显著提升,原因在于增量训练见过了更多的样本,对embeding部分训练的更加充分。EasyRec支持从上一天的checkpoint restore,然后在新的一天的数据上继续训练。为了快速适应新闻、节假日、大促等场景的样本分布发生快速变化的场景,我们提供了对实时训练的支持。EasyRec通过Blink来构造实时样本和特征,并调用Feature Generation对特征进行加工,然后通过Kafka、DataHub读取实时的样本流进行训练。实时训练的稳定性比较重要,我们在训练过程中对正负样本比、特征的分布、模型的auc等做实时的监控,当样本和特征的分布变化超过阈值时,报警并停止更新模型。保存checkpoint时,EasyRec会同步记录当前训练的offsets(多个worker一起训练时,会有多个offset),当系统发生故障重启时,会从保存的offsets恢复训练。

EasyRec在多个用户场景(20 )中得到了验证,场景中包括商品推荐、信息流广告、社交媒体、直播、视频推荐等。以下是部分客户在他们场景中使用EasyRec取得的提升:
- 某APP广告推送: AUC提升1个点,线上ctr提升4%,资源消耗降低一半;
- 某大型直播APP: 基于EasyRec MultiTower模型AUC提升2%;
- 某大型社交媒体: 基于EasyRec MultiTower模型AUC提升6%,线上效果提升50%;
- 某大型电商平台:基于Easyrec DSSM模型,线上UV价值提升11%, UVCTR提升4%;
- 某短视频APP:基于EasyRec DBMTL模型,线上时长提升30%, 多模态特征进一步提升10%。
最后,EasyRec已经通过github开源(https://github.com/alibaba/EasyRec),在此欢迎各位同路人共建,包括:丰富各个场景的特征构造,引入更多在实际场景中验证过的模型,提升模型离线在线推理的性能,等等。在这个日益内卷的行业(可以想象tensorflow为什么越做越差,跟内卷应该关系非常大,api的修改比较随意、存在过度设计扩展困难的问题、bug层出不穷,天下苦TF久矣),我们希望能够通过这样一个开源的工作,形成大家的合力,照亮我们共同的路。在这里,我们也像前辈xgboost致敬,希望这个工作能够像xgboost一样发扬光大,影响深远。
作者:程孟力 - 机器学习PAI团队
原文链接:https://developer.aliyun.com/article/842271?utm_content=g_1000314855
本文为阿里云原创内容,未经允许不得转载。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






