如何实现环境公平(适应环境变化的公平意识在线元学习)
赵辰:
美国Kitware公司高级研发工程师,博士毕业于美国得克萨斯大学达拉斯分校计算机专业。主要研究方向公平性学习在数据发掘,机器学习,深度学习上的研究和应用。在包括KDD,AAAI,WWW,ICDM等会议与期刊上发表过多篇论文,并受邀担任KDD,AAAI,ICDM,AISTATS等人工智能领域顶级国际会议程序委员和审稿人,并组织和担任KDD workshop的主持。
公平意识在线学习框架已成为持续终身学习设置的强大工具。学习者的目标是顺序地学习新任务,这些新任务随着时间的推移一个接一个地出现,学习者确保新任务在不同的受保护亚种群(如种族和性别)中统计均等。现有方法的一个主要缺点是它们大量使用数据i.i.d的假设,从而为框架提供静态的遗憾分析。然而,在任务从异构分布中采样的不断变化的环境中,低静态遗憾并不意味着良好的性能。为了解决变化环境下的公平感知在线学习问题,本文首先在强适应的损失后悔中加入长期公平约束,构建了一种新的遗憾度量FairSAR。此外,为了在每一轮中确定一个好的模型参数,我们提出了一种新的自适应公平感知在线元学习算法FairSAOML,该算法在偏差控制和模型精度方面都能够适应变化的环境。该问题以双水平凸凹优化的形式表达,分别与模型的精度和公平性相关的原始参数和耦合参数。理论分析给出了损失遗憾和违反累积公平约束的次线性上界。我们在不同的真实数据集上的实验评估表明,本文所提出的FairSAOML明显优于其他相关在线学习方法。
Why Fairness in ML is important?
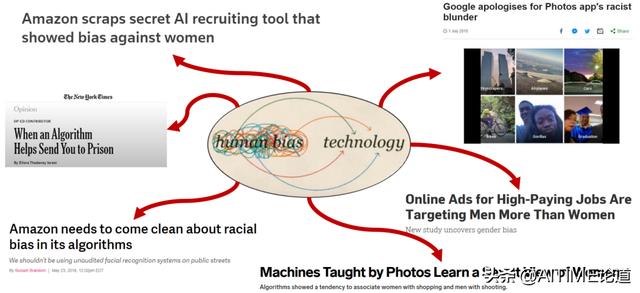
通常我们会看到很多新闻,这些新闻在描述很高科技AI产品时会有一些对于系统的偏见。比如前几年一条新闻,谷歌照片错误的把一些黑人标注成猩猩。
Motivations – Example 1
再比如说,在预测犯罪数量的模型中会更多的偏向于非洲裔和黑人社区。

General Model (通用模型)

这篇文章讲到在进行照片分类的时候,这些照片主要是描述男生和女生在做饭的照片,我们要预测的是这些男生女生各自是否分别在cooking。
Unfair Dependency
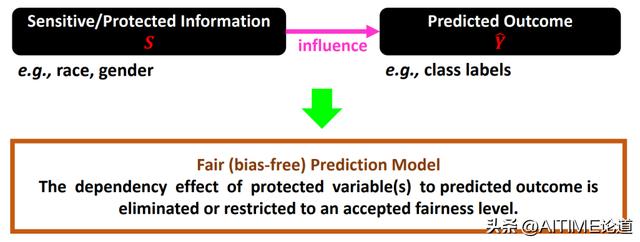
这些例子都说明在数据中有一些敏感性信息,我们将其叫做sensitive feature,这些信息包括其种族、性别等等。这些信息会影响到预测的结果,这些信息也会对模型产生一些偏差。
A General Form of Fairness-Aware Problems
在没有考虑到fairness的时候,我们只是单独的最小化loss。当考虑到fairness的时候,我们通常会用一个函数描述年龄、种族这些敏感信息。
我们在不断最小化loss的时候,同样也按我们的方式在fair domain中进行。

Dependence Score Function g(•)

常见的g(•)包括很多种,其可以粗略的分为Parametric和Non-parametric。我们用Categories of g(•)中的Demographic Parity作为一个例子来描述g(•)可以这样去演绎。
Linear Relaxation of The Selected
最常见的Demographic Parity可以描述为:假如将group分为两个种族——黑人和非黑人,男生和女生等等。这样就可以转化成两个种族之间的差,涉及到的indicator function在优化中是一个非凸的function。

How to Control Bias with Multiple Tasks?
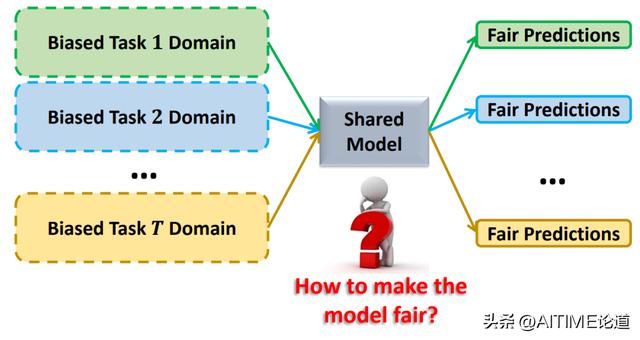
这篇文章也是在说当你有很多任务的时候,如何学习到一个shared model使得所有的task共享模型,以达到统一的fairness。
Motivation (Meta-Learning, a.k.a. Learning to Learn)
对于传统型的元学习模型来说,可能更多的是训练好模型,并泛化到它的task domain上得到结果。

其中,我们考虑到元学习可能是解决motive task的一个比较好的技术。元学习区别于机器学习模型的点在于可以学一个meta-learner并转移学到的知识去testing domain上。
或者也可以将meta-learning理解为learning to learn。
Intuitions of Meta Learning
我们可以看到,machine learning其实是可以被看成训练一个模型参数。当你用一个神经网络训练一个模型的时候,更多的是在乎神经网络模型中的参数是如何训出来的,后续再运用参数到testing domain上。

而meta-learing不再是学一个模型的参数了,而是学习算法。这个算法的目的是帮助我们更好的找到模型的参数是什么。具体到算法来说,这个模型可以是很多含义,甚至被考虑为超参。
An Example Diagram of Meta-Learning
通常来说,meta-learning会把task分为training和testing两个部分。每个task也会被分为support和query。其实可以简单的想象为每个task之中还会分为test和training。

Fairness-Aware Meta-Learning
Meta-learning的工作还有很多,这里主要介绍了最常用的模型。

主要来说,我们研究的是一个Bi-Level optimization problem,其存在一个inner-level和outer-level。每一个level都是用来控制fairness level的,一个是从task角度,另一个是从全局角度。
A Brief Introduction to The Working Paradigm of Online Learning
无论如何,目前的工作都是基于off-line learning,off-line learning可以想成所有task是一起给来训练的,而online learning在生活中则更符合现实。

Task不是一股脑给的,而是随着时间顺序一点一点给的,可以随着时间顺序一点点的适应模型。
Fairness-Aware Online Meta-Learning with Multiple Tasks
综合来说,这种Fairness-Aware Online Meta-Learning有很多task,步骤大致如下图所示:

在时间为t-1时,有这样一个meta-level模型;当时间为t,即新的任务来到时,采用θt对新的task进行测试,测试结果也会被记录下来,包括那些loss都会被记录下来。然后,我们会把新学的task囊括进来之后再去学θt 1这样一个参数。之后,我们再move到新的循环。
如何在这个过程中学到新的meta-level参数,是一个比较重要的关键点。
Two Papers
针对这个问题,我们也针对性的做了一些拓展。
在今年的研究中,我们主要关注domain generalization的问题,即task可能并不是来自同一个domain。
The Learning Protocol
做一个形象的比喻,这可以看着learner和adversary之间的一个对抗游戏。

第一步的时候,learner会用一个算法来选择θt,adversary把loss function和fairness function传回给learner,learner会用这些结合θt算出一个loss和notion并move到下一个循环中。
Static Regret in Fairness-Aware Online Meta-Learning
整个的online meta-learning可以被看成在最小化一个regret。

无论怎样,上述两个已知工作最大的假设就是:所有的task来自同一个domain,我们要考虑的就是task domain在某一时间点发生变化的时候,work该怎样快速适应这个方式。
Adaptive Fairness-Aware Online Meta-Learning for Changing Environments

我们接下来的工作就是研究在domain发生变化的时候,如何快速适应新的domain?
Recall the Learning Protocol
刚刚也说了,如何研究出这样一个算法其实是online-learning中比较重要的一步。

假设我们已经有了这个算法并命名为K,接下来在适应不同domain时就可以将每个task新来时建立的interval统一传入上图中灰色最大的方框meta-level parameter。
每个interval t’只是用了这个时间点t的数据。根据我们之前配置的算法,就能针对每个interval都得到一个meta-level parameter。我们对所有的结果进行加权平均就得到了最后的meta-level parameter。当有θt’时,interval t’ 1也被加入进来。为了能够更好地适应新的domain,我们通常会让权重在新的domain上更大,也使得新学的meta-level parameter更偏向于后面的domain。这样也使得任务更好的去进行适应。
Strongly Adaptive Regret in Fairness-Aware Online Meta-Learning

刚刚我们也说了,当有很多interval的时候,regret也会在变。针对之前work而言有很多的interval,loss regret也就变成了让所有interval里挑出最大的regret进行最小化。对于fairness notion来说,我们对每个interval都计算出一个fairness notion,然后挑出最大的fairness notion进行最小化。
Updating Interval Parameters Leads to High Time Complexity

这个方法其实还是有一定缺陷的,最大的缺陷在于interval会随着时间的增多而增大,并呈线性增长。其时间复杂度也会很大,针对这个问题也引出了我们的work。
Adaptive Geometric Covering (AGC) Intervals
我们的巧妙设计是为了使其时间复杂度没有那么高,而将所有的interval用一个log的方式分为了4个不同set,每个set中的interval长度是一样的。
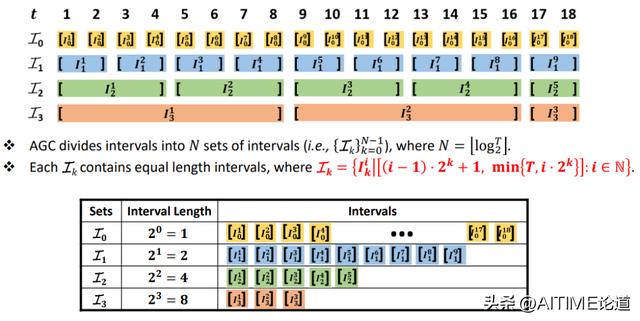
我们粗略的用log对数以2为底,但是其实我们将底换为3或5也是可以的。我们可以算出每个set的固定长度。
Target Set – A Selected Subset of Intervals
每个时间点,我们会取一定的interval set,即target set。其中囊括了所有的interval,但却是以时间点开头的。

The Learning Experts
然后我们构建了一个算法,令每一个interval可以想象成expert的learning process。这个expert process有两部分,分别是active experts和sleeping experts。但是那些expert是active experts或sleeping experts呢?这是在动态变化的。随着t变化,expert中哪些是active expert是变化的。

具体来说,当我们拿到一个target set的时候,target set 这些interval里面对应的expert会被激活。区别于sleeping expert,active experts会主动更新,然后通过learning process更新parameter。我们最终将其进行整合,去学习下一个时间点的meta-level parameter。
Learning with Experts (t=1)
为了区分active experts和sleeping experts,我们在下面举了一些例子。
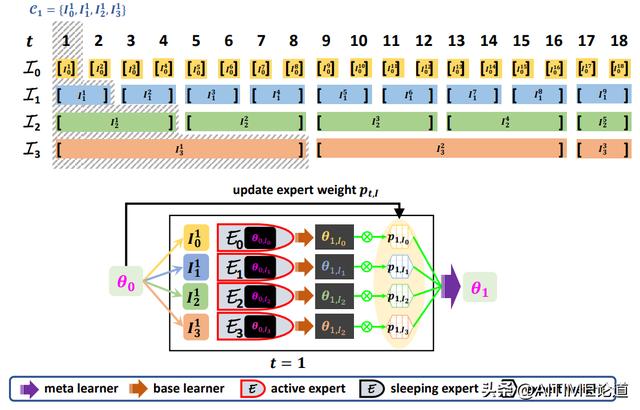
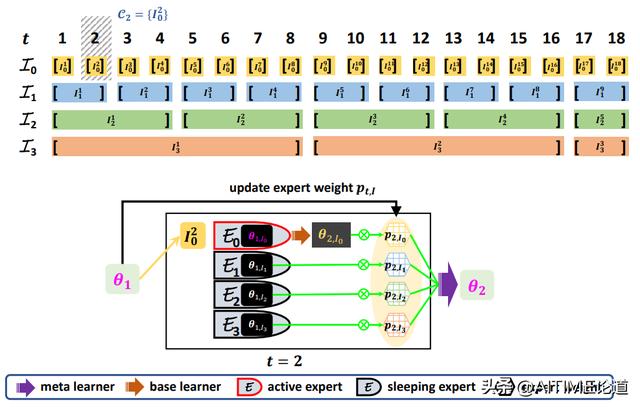

在t=1的时候,active experts选择的是每个set的第一个当作target set。在t=2的时候,我们只有一个被选入了target set,这样也就激活了第一个为active experts,剩下的就是sleeping experts。在t=3的时候,以此类推。
Problem Formulation
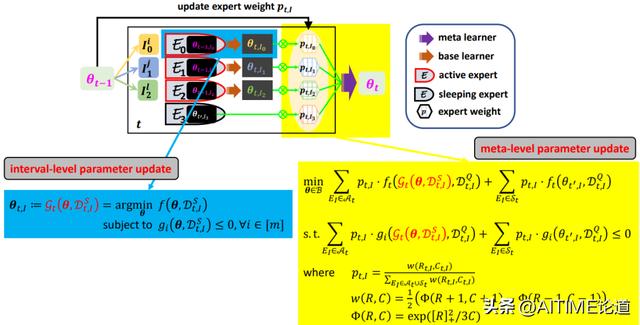
Problem Formulation可以分为两部分,一部分是interval-level parameter updates。这个地方就是简单用了一步到几步的更新步骤,也符合memo在offline上的更新方法。
另外,我们对meta-level parameter updates来说分为active experts和sleeping experts。这里面的weights用p表示,每个expert如何更新就是用新更新的meta-level parameter和task-level parameter之间的差别来更新weight。
Bi-Level Optimization

接下来的整个优化过程可以被看作是一个Bi-Level Optimization双层优化。这样其实也是一种你中有我,我中有你的过程。Interval-level的一个output被当成了meta-level的input,meta-level的output也会被当成interval-level的input,这样不断进行迭代更新。
Algorithm Analysis

对于算法分析,其最主要的目的还是最小化regret。我们列举了一些不同的算法来应对相同问题在不同场景中的regret分析。如上图红框所示,我们的方法被列举在最后面,其实在loss regret上并没有很大的提升。我们指出了constraint violation,在这里也算是一个较大的贡献。
Experiments

为了更好的展现实验结果,我们选择了两个case。第一个case是说fairness level从高到低和从低到高能够使得我们模型更好地适应两种不同的changing environments。
MovieLens就是一个简单的datasets,我们为了将其设计成适应我们的主题。我们把它变成了3个不同的copy,不同的copy是不一样的东西。第二个copy中的explainable features乘以-1,这样也得以和第一个、第三个加以区分。
继续我们的实验,我们考虑了3个evaluation。前两个是fairness machine learning中最常用的evaluation metrics,同时我们还兼顾到模型的预测准确率。
Key Results

从实验结果可以看到,我们针对这3种metrics和datasets。我们考虑到了7个不同的baseline methods。这7个baseline methods可以分为两类。一类是online learning或changing environments,并没有考虑到fairness。这也是很多算法常常会忽略的一部分。还有一类本身就是online上针对fairness learning的,但是它们并没有考虑到changing environments。
通过和这些方法的对比,我们发现我们的方法能够做到很好的适应环境变化,但是在模型准确率方面并没有取得最好的效果。这也可能是因为fairness和accuracy因为domain发生变化而无法兼顾而导致的。

之后,我们主要研究的是为什么我们的模型可以很好的adapt。我们发现weights扮演了一个重要的角色,expert的weights在每个domain上都在发生周期性的变化。对于一些比较长的interval,它的expet weights是在不断增长的,对于模型来说是有一定稳定型的。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






