bert模型是啥 被封神的多语言BERT模型是如何开启NER新时代的
全文共3880字,预计学习时长20分钟或更长
在世界数据科学界, BERT模型的公布无疑是自然语言处理领域最激动人心的大事件。
鉴于BERT还未广为人知,特此做出以下解释:BERT是一种以转换器为基础,进行上下文词语预测,从而得出最优结果的语言表征模型。计算语言学协会北美分会将BERT论文评为年度最佳长篇论文。谷歌研究发布了经过预训练的BERT模型,包括多语言、中文和英文BERT。
会话人工智能框架Deeppavlov是基于iPavlov开发的,它包含构建对话系统所需的所有组件。BERT发布之后,其处理多种任务的能力令人惊异。
BERT可以集成到三个常用NLP任务的解决方案中:文本分类、标记和问题回答。本文将将详细阐释如何在DeepPavlov中使用基于BERT的命名实体识别(NER)。
NER介绍
命名实体识别(NER)是NLP中最常见的任务之一,可以将其表述为:
给定一个标记序列(单词和可能的标点符号),为序列中的每个标记提供一个来自预定义标记集的标记。下图标示句是NER在演示中的输出,其中蓝色代表人物标签,绿色代表位置,黄色代表地理位置,灰色代表日期时间。
Deeppavlov ner模型支持19个标签:org(组织)、gpe(国家、城市、州)、loc(位置)、事件(命名为飓风、战斗、战争、体育活动)、日期、基数、金额、人物等。Deeppavlov的NER模型在命令行中处理的语句如下所示。
>> Amtech , which also provides technical temporary employment services to aerospace , defense , computer and high - tech companies in the Southwest and Baltimore - Washington areas , said its final audited results are due in late November . ['B-ORG', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'O', 'B-GPE', 'O', 'B-GPE', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-DATE', 'I-DATE', 'O']
>> Amtech还为西南部和华盛顿巴尔的摩地区的航空航天、国防、计算机和高科技公司提供临时技术就业服务,该公司表示,其最终审计结果将于11月底公布。
BIO标记方案用于区分具有相同标记的相邻实体,其中“B”表示实体的开头,“I”表示“中间”,它用于除第一个实体外的所有组成实体的单词,“O”则表示不是实体。
NER有多种业务应用程序。例如,NER可通过从简历中提取重要信息来帮助人力资源部门简历的评估。此外,NER还可用于识别客户请求中的相关实体——如产品规格、部门或公司分支机构的详细信息,以便对请求进行相应分类并转发给相关部门。
如何在Deeppavlov中使用基于Bert的NER模型
任何预处理的模型都可以通过命令行界面和Python进行推理。在使用模型之前,请确保使用以下命令安装了所有必需的软件包:
python -m deeppavlov install ner_ontonotes_bert_mult python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
其中ner_ontonotes_bert_mult表示配置文件的名称。
可以通过Python代码与模型进行交互。
from deeppavlov import configs, build_model ner_model = build_model(configs.ner.ner_ontonotes_bert_mult, download=True) ner_model(['World Curling Championship will be held in Antananarivo'])
此外,DeepPavlov包含一个基于RuBERT的处理俄语数据的模型。
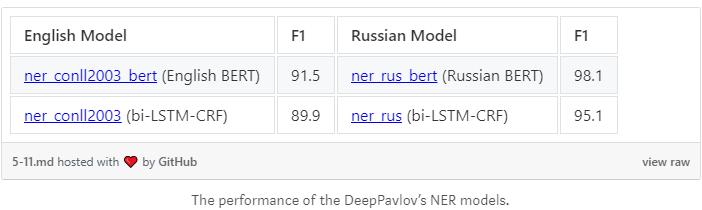
总体而言,比起基于双LSTM-通用报告格式的模型,基于BERT的模型有了实质性的改进。
通过下表可以看到基于英语和俄语的模型的性能。
多语种Zero-Shot转移
多语言BERT模型支持执行从一种语言到另一种语言的零距离传输。
ner_ontonotes_bert_mult模型是在OntoNotes语料库上训练的,该语料库在标记模式中有19种类型。
你可以在不同的语言上测试模型。
from deeppavlov import configs, build_model ner_model = build_model(configs.ner.ner_ontonotes_bert_mult, download=True) ner_model([ 'Meteorologist Lachlan Stone said the snowfall in Queensland was an unusual occurrence ' 'in a state with a sub-tropical to tropical climate.', 'Церемония награждения пройдет 27 октября в развлекательном комплексе Hollywood and ' 'Highland Center в Лос-Анджелесе (штат Калифорния, США).', 'Das Orchester der Philharmonie Poznań widmet sich jetzt bereits zum zweiten ' 'Mal der Musik dieses aus Deutschland vertriebenen Komponisten. Waghalter ' 'stammte aus einer jüdischen Warschauer Familie.'])
在俄语语料库3上对模型性能进行了评价。以下是转移的结果。
多语言模型在第3集俄语语料库上的性能
如何为NER配置BERT
Config/fag文件夹下单独配置文件对deeppavlov nlp 进行定义。配置文件由四个主要部分组成:dataset_reader、dataset_iterator、chainer和train。
所有基于BERT的模型的公共元素都是配置文件chainer部分中的BERT预处理器(对于NER,是bert_ner_preprocessor类)块。未经加工的文本(即,“Alex goes to Atlanta”)应该传递给bert_ner_preprocessor,以便将记号化为子记号,用它们的索引编码子记号,并创建记号和段掩码。token参数本身包含一个句子标志列表([' Alex ', ' goes ', ' to ', ' Atlanta ']), subword_token带有特殊的标志。([' [CLS], ' Alex ', ' goes ', ' to ', ' Atlanta ', ' [SEP]])。subword_tok_id包含令牌id,而subword_mask是一个列表,其中0表示特殊的令牌,1表示句子的令牌([0 1 1 1 1 1 0])。
{ "class_name": "bert_ner_preprocessor", "vocab_file": "{BERT_PATH}/vocab.txt", "do_lower_case": false, "max_seq_length": 512, "max_subword_length": 15, "token_maksing_prob": 0.0, "in": ["x"], "out": ["x_tokens", "x_subword_tokens", "x_subword_tok_ids", "pred_subword_mask"] }
以上是本文想介绍的关于以多语种BERT模型为基础的NER的全部内容。
留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
,







免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






