机器学习和深度学习准确率比较(读懂数据科学和机器学习)

作者 | luminousmen,机器人专家,擅长Python、大数据、机器学习等
译者 | Arvin,责编 | 王晓曼
头图 | CSDN下载自视觉中国
出品 | CSDN(ID:CSDNnews)
以下为译文:
许多人对数据科学和机器学习感到困惑。下面我们一起看下该如何学习:
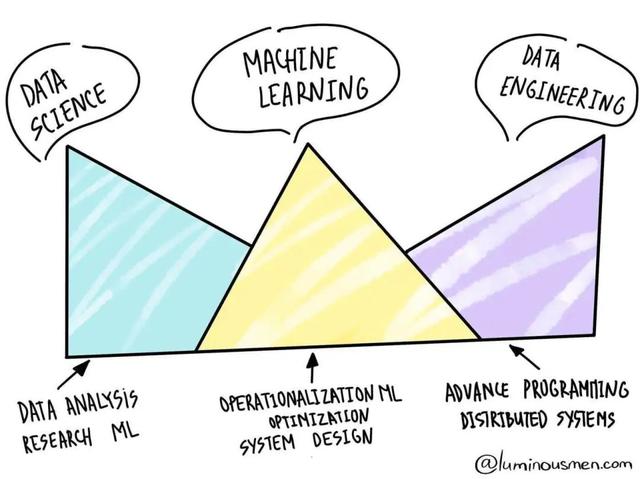
数据科学在技术的大规模传播期间,人类产生了大量的数据,数量大到无法处理和可视化。这些数据有关我们的通话和行动轨迹,互联网行为,购物偏好,气候过程以及许多其他方面。如果数据得到正确处理,企业可以从中受益匪浅。
这就是数据科学的全部意义:借助统计方法,认识特定领域并进行相应的工程设计,在数据中找到内在模式,并从中提取知识。但是,尽管这被称为科学,但这项活动纯粹是出于实际利益的考虑——结果的实际适用性是必须的。

在这里,尽管有必要理解和解释这种现象,但是最重要的是从数据中提取的知识对商业的实际适用性。是的,您不必是数学博士,并理解将薯条放置在靠近啤酒的位置能够增加利润,但是您需要向企业证明这样切实有效。
1、为什么数据科学吸引了如此多的关注?
主要原因是数据中包含的隐性效率。每个公司都会收集数据。对数据进行分析使公司有机会制造更好的产品,吸引更多的目标客户、留住客户、改善业务流程等等。所有这些都可以通过大量闲置数据来了解鲜为人知的流程优化手段及个性化方法。
数据科学的方法使我们能够没有偏差或偏见(实践上主要是偏见)地从可用数据中得出客观结论,并从发现的模式中获得新发现。但是您应该了解,数据并不总是有用的,并且拥有的数据量并不重要。

术语定义和数据科学实践可能因公司而异。对于一家公司,数据科学团队可能是一位BI分析师,他在Excel中绘制图表并进行一些业务报告,对于另一家公司,它可能是一个端到端的开发部门,负责与客户的沟通、数据分析、基础架构、构建生产就绪系统等。
但是总的来说,很明显,数据科学家对特定领域有一定的了解,通常具备数学或统计背景,了解如何处理数据、在何处处理数据以及如何看待数据等,而且他们通常没有任何开发或工程经验。在执行不同任务时,它们将由数据工程师或机器学习工程师提供帮助(这完全取决于技能)。
机器学习如果它是用Python编写的,那么它就是机器学习。如果它是用PowerPoint创作的,那么它就是人工智能。
在过去的任何时候,计算机都是通过编程来获得新的功能--人们为机器创建算法,从而得到预期的结果。对于任何需要自动化的可理解和确定性的任务,这都是一种确定性和可理解的方法。
但是有时,一项任务虽然可以理解,但其中包含一些不确定性的要素,我们必须和这种无法消除的未知因素共存。
为了有效处理此类问题,需要使用其他方法。正如人们所说的,必要性是发明之母(但没人知道发明之父是什么)。机器学习已成为这种新方法。

在机器学习中,人们仅向计算机提供一些介绍性信息,但是算法的结果不是由人确定的。一个人定义了机器学习的方式,但是机器是从提供给它的数据中自己学习的。机器本身会给出答案。这类似于你和我的学习方式。
2、机器学习什么?
机器从相关任务过去的经验(关于数据的)上进行学习,并体现在给定任务的特定指标的性能提升。这个过程也可以称为适应(在此过程中可能具有更多上下文)——机器根据新的信息调整自己的行为。
这种似乎没有人类干预的适应,时不时地给人一种机器正在学习的印象。机器学习本质上是一种数据分析方法,它使用迭代数据的算法来自动构建分析模型。
机器学习允许计算机查找隐藏的知识,而不需要明确地编写查找的程序,这是一个关键的想法。实际上,我们将数据提供给算法,并且程序执行的结果将成为处理新数据的逻辑。

一个机器学习项目包含以下三个方面:
首先,机器学习从数据开始,目标是从数据中提取知识或理解。
其次,机器学习涉及一定程度的自动化。与其试图手动地从数据中收集知识,不如使用计算机将一个过程或算法应用到数据中,以便计算机帮助获得必要的知识。
第三,机器学习不是一个完全自动化的过程。正如任何从业人员所说的那样,机器学习要求您做出许多明智的决定,才能使整个过程成功。

让我们将整个数据科学/ 机器学习项目划分为多个步骤,并仔细研究数据科学和机器学习相交的部分。

根据项目的目标和使用的方法,数据科学过程可能略有不同,但是它通常会包含以下内容。
1、寻找并确定目标
首先了解业务问题非常重要。数据科学家应提出适当的问题,理解并定义要解决的问题的目标。有时这并不总是那么容易,因为企业本身想要很多,但没有什么具体的目标。
2、收集和存储数据
然后,他负责从多个来源(例如SAP服务器,API数据库和在线存储)收集和抓取数据。有时所有数据都已经收集在方便的数据仓库中,但是有时您需要付出一些努力才能获得数据。

大多数情况下,数据工程团队在这个阶段帮助构建可靠的数据管道。
3、数据处理和清理
无论采用哪种机器学习算法,都无法从包含过多噪声或与实际情况不一致的数据中学习任何东西:无用的输入输出。为了使整个项目成功,我们需要清理获取的数据。
在采集数据后,需要处理数据。此阶段包括数据清理和数据转换。数据清理是最耗时的过程,因为它涉及处理许多复杂的场景。例如:
-
冲突的数据类型
-
拼写错误的属性
-
缺失值
-
重复值
4、数据分析然后,了解数据可以实际完成的工作对于业务和数据科学家而言都非常重要,因此需要对数据进行研究分析。通过探索性数据分析,能够确定并优化用于下一步的变量选择。

5、数据建模
现在,流程进行到核心的数据科学处理环节,包括数据建模等。数据科学家选择一个或多个潜在模型和算法,并选择模型性能的指标。然后开始将统计和机器学习方法应用于数据,以确定最能满足业务需求和手头任务的模型(这可以是简单的启发式)。
接着,从可用数据中训练模型,并对其进行测试以选择最有效的模型。这是一个迭代的过程,尽管如此,它还是非常有创造性的。

这一步经常被过分强调。很少有数据科学家会重视把模型性能提高1%。通常,将“足够好”的模型发布到用户面前更重要。生产中的“足够好”模型的效果要比Jupyter笔记本中的性能模型提高5-10%好100倍。
6、展示最终结果
最棘手的部分尚未完成,包括可视化和交流。您需要再次与客户和利益相关者见面,以简单有效地交付业务成果。
在这个阶段,项目可能会结束--也许业务已达到其目标,或者POC尚未揭示该业务的投资回报,因此不需要进一步的工作。
7、生产化最后,最重要的阶段开始了--您需要将数据科学团队的成果展现在用户面前-部署和优化模型并将其集成到其他业务流程中。
根据数据类型(点击流,批处理),目标平台(AWS,Azure,内部部署等),要求(SLA,水平可伸缩性等)以及最终技术栈等等的差异,这个阶段可能会有很大不同。

从本质上讲,机器学习活动后续的正常开发周期包括--优化模型,检查所有边缘情况,创建模型构件的生命周期,在生产环境中部署前预测试模型等,这是最佳实践(您可能不得不选择性能较低的模型)。归根结底,机器学习就是软件。
8、监控
在成功部署系统之后,有必要引入监控系统--这里并不是指仅启用日志记录--我指的更多的是报表和工具栏,以获取分析,计算和生成选定指标以及可能相关的信息数据,建立A/B测试系统等。
当然,我仅涉及实际项目中发生的一小部分,但我认为它应该让您了解构成常规数据科学/机器学习项目的基本活动。

结论
像所有其他领域一样,数据管理也将朝着全栈方向发展。全栈工程师不仅专注于自己的主要领域,并且知道如何制作其他相关部分。

因此,数据科学家会朝着工程学的方向发展–加强他们对基础架构,代码设计和工具的了解。数据工程师正在走向数据科学--试图了解统计,算法和处理数据的方法。最终,他们都会成为机器学习工程师。
如上所述,软件工程、开发和部署技能在生产级机器学习项目中更为重要。生产中 “足够好” 的模型优于Jupyter笔记中性能更高的模型。
我认为数据科学家需要作为主要顾问,他们可以为多个项目工作,而开发工作可以由机器学习和数据工程师直接完成。数据科学的未来就是数据工程。
原文:https://luminousmen.com/post/data-science-and-machine-learning
本文为CDSN翻译,转载请注明来源出处。


☞“国产”AI框架争相开源,“领头羊”百度飞桨将扔重磅炸弹?
☞第一个"国产"Apache 顶级项目 Kylin,了解一下!| 原力计划
☞天才程序员之陨落:在业余项目创业 Cloudflare,公司上市前患病失去自理能力
☞Go远超Python,机器学习人才极度稀缺,全球16,655位程序员告诉你这些真相
☞对不起,我把APP也给爬了
☞超级账本Hyperledger Fabric中的Protobuf到底是什么?
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






