专业cpu推荐(自称全球最通用的CPU)
来源:内容由半导体行业观察(ID:icbank)编译自chipsandcheese,谢谢。
Tachyum这个名字经常出现在各种新闻文章中,谈论着它将如何成为比AMD 64核Milan更快的通用CPU,以及与英特尔的Ponte Vecchio不相上下的SIMD加速器。而且,它们可以比英伟达的H100更快地进行人工智能操作——所有操作都在一个芯片中!
读过这篇文章的一些人可能知道一句老话,“If it is too good to be true, it probably is”,这感觉就像Tachyum的情况。他们声称能够做所有这些美妙的事情,几乎没有缺点,我只是认为这是不可能的。让我们从Tachyum的故事开始。
故事的开始
Tachyum于2017年2月8日推出,根据2018年10月发布的微处理器报告,其全新的CPU预计将在2020年底投产。这是一个疯狂的时间周期,Tachyum想要做的,是即使大型高性能半导体公司也没能达成的激进时间表,他们几十年来一直在做芯片设计,比Tachyum拥有更多的资金。
在 Hot Chips 30 (2018) 上,Tachyum 展示了他们正在开发的架构并开始敲响警钟,因为 Tachyum 将他们的 Prodigy 架构与英特尔失败的安腾(Itanium)架构进行比较。
帮大家回忆一下,Itanium是英特尔的第一个商业 64 位 ISA 和架构系列,它与 x86 有很大的不同。Itanium也称为 IA-64,不是像 x86 那样的乱序超标量(out-of-order superscalar) CPU。相反,它是一个 VLIW(Very Long Instruction Word:超长指令字)CPU,它是一种有序设计,它依赖于编译器来决定执行哪些指令以充分利用架构。这意味着 Itanium 非常依赖编译器,这最终成为 Itanium 在高性能市场上失败的一个重要原因,这也是 Tachyum 也会遇到的问题。
然而,VLIW架构在数字信号处理器的计算领域已经起飞。DSP用于各种任务,如图像处理、音频娱乐、广播等。然而,您在高性能计算中看不到DSP,因为尽管它们非常擅长某些任务,但它们相当专业,因此它们执行通用任务的能力相当差。
回到Tachyum,早在2018年,他们就表示将在2020年底前交付生产系统。然而,在2020年10月,Tachyum宣布他们将把Prodigy推迟到2021年发布,但他们将在2021年底前开始量产。2021年6月1日,Tachyum宣布他们已经过渡到台积电的N5制程,用于Prodigy通用处理器。虽然这一举措使Tachyum能够扩大其通用处理器的范围和能力,但它将Tachyum的时间设定为2022年。现在是2022年,Tachyum还没有发货任何生产系统,而Tachyum最接近发货的产品是FPGA模拟系统。Tachyum声称,他们将在今年第四季度对产品进行送样,这意味着他们的系统最早将在2023年中期获得普遍可用性。
现在,是时候看看 Prodigy 架构,看看它带来了什么。
神童(Prodigy)架构
在这里,我们必须附带一个巨大的免责声明:我们只能评估 Tachyum 对他们的 Prodigy 架构的评价,因为该架构从 2018 年到 2022 年发生了变化。因此,我们将介绍 2018 年之间没有变化的内容先看 Prodigy 和 2022 Prodigy,再看看两者之间有什么变化。
什么最有可能相同?
分支预测器
Tachyum 没有说他们的分支预测器(branch predictor)在 2018 Prodigy 和 2022 Prodigy 之间发生了变化,所以我们假设 2022 分支预测器与 2018 年分支预测器相同。
有了这个假设,Prodigy 使用了一个具有 12 位global history的“skewed-Gshare-like”方向预测器(direction predictor )。Gshare 使用global history来索引(index)到饱和计数器(saturating counters)的共享数组,通常通过对history buffer与分支地址(branch address.)进行异或运算(XOR-ing)。这种预测技术在 2000 年代初到中期非常流行。示例(Examples)包括 Intel 的 Pentium 4,它使用具有 16 位global history的 Gshare 预测器。AMD 的 Athlon 64 采用了具有 8 位global history的 Gshare 预测器。如果 Prodigy 使用更大的history table或更好的hashing来防止破坏性干扰,Prodigy 可能会获得稍微更好的准确性。但在过去十年中,Prodigy 的预测算法在高性能 CPU 中并不是最先进的。

如果我们仔细观察过去十年的发展,Prodigy 的预测器(predictor)显然落后了。AMD 的 Bulldozer 使用local和global history以及选择性能最佳方案的meta predictor。从我们的测试来看,这样的设置仅胜过global和local history ,除非 Gshare 的存储预算非常庞大,Prodigy 的预测器与最近的 Intel 和 AMD CPU 相比显得很古老,后者具有 TAGE 和perceptron predictors。这些最先进的预测器(predictors)在相同的存储预算下提供更高的准确性。
Prodigy 的优势在于,它的分支错误预测penalty 相对较短,只有 7 个周期。这甚至比Neoverse N1这样的慢速 CPU 还要好,后者在检测到错误预测之前有 9-11 个pipeline stages。根据 AMD 的优化手册,像 AMD 的 Zen 3 这样的时钟频率更高的 CPU 具有 13 个周期的典型mispredict penalty 。此外,Zen 3 和 Neoverse N1 使用乱序执行来实现每时钟的高性能。他们可以有数百条指令 in flight,,就浪费的工作而言,做出错误的预测非常昂贵。
同样,Prodigy 的分支目标跟踪( branch target tracking )也过时了。如果您生活在2000年代初期,跟踪( Tracking)1024 个分支目标(branch targets)可能没问题。当你将它与过去十年甚至更早的任何东西进行比较时,这并不好。例如,考虑到 AMD 的 Athlon 64 可以跟踪 2048 个分支目标,而 Intel 的 Netburst 最多可以跟踪 4096 个分支目标。现在将其与一些较新的架构进行比较:
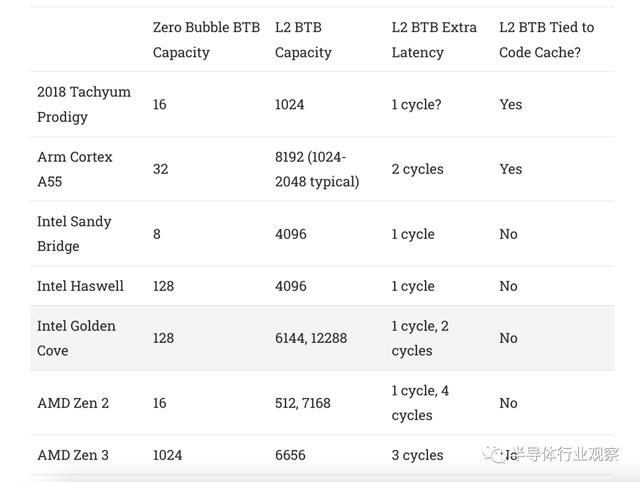
Prodigy figures are from Tachyum’s Hot Chips 2018 slides
Prodigy绕着分支跑的速度也不怎么样(Prodigy’s speed around taken branches is also unimpressive)。它只能追踪(track)16个分支机构,而这些分支没有前端的pipeline stalls。当代高性能CPU可以在每个speed ban追踪更多的分支。
但情况变得更糟。根据 MPR,每个 L1i 缓存行都有两个branch targets的字段(fields)。这意味着branch targets几乎可以通过 L1i 获得。无需索引( index)到单独的branch target buffer。但这种技术也过时了。现代 CPU 将 BTB 解耦,以在 L1i L1i miss中后实现准确的预取。只要分支预测器获得 BTB hit并将其排队等待指令提取单元(fetch unit),它就会不断生成提取目标(fetch targets)。这自然会提供非常准确的指令预取,即使在必须从 L2 及以上提取指令时也能实现高指令吞吐量(前提是分支预测器准确且 BTB 足够大)。Prodigy 无法做到这一点,这意味着 instruction cache misses 将比英特尔和 AMD 的芯片带来更高的惩罚(penalties)。
然而,这里有一线希望,因为 2018 Prodigy 和 2022 Prodigy 都是 VLIW 架构,其中编译器应该能够在采用或不采用分支时向 CPU 提示,而且领先的分支预测器并不像Zen 3 或 Golden Cove 以及 2022 Prodigy等可能由于更大的 L1i 而增加了 BTB 容量的架构那么重要。
前端(Frontend)和 ISA
现在这个有点争议,因为在Prodigy Spec Sheet上说它是一个4宽的无序核心,然而在Tachyum的首席执行官Radoslav Danilak在接受golem.de 的采访中强调,Tachyum开发了一个基于VLIW原则的ISA和架构。那么,我们如何才能将这两个看似矛盾的信息统一起来呢?
Tachyum在Hot Chips 2018的演示中表示,Prodigy可以维持“多达8次risc式的微操作/周期”。微处理器报告称Prodigy是一个“four bundle eight-wide design”,通常设计为每个时钟支持一个bundle。
我对此的解释是,Tachyum可以从L1i中拉出多达4个bundles,这可以在解码时分成2个微操作(micro-ops),也就是每个循环8个微操作。然而,基于MPR的另一种更悲观的解释是,每个循环只能一个bundle,并且该bundle中最多可以有4个微操作。
在获取 bundles之后,它们被放置到一个有12-entry 的队列(queue)中。这个队列可以让前端(frontend)保持获取指令,即使后端停止(stalled)并且不准备接受它们。如果指令从后端停止排队(If instructions are queued up from a backend stall),前端可以通过继续向后端提供那些排队的指令来“隐藏”指令缓存错过(instruction cache miss),同时等待来自较低级缓存的指令字节。我假设Prodigy的队列包含12个bundles,,而不是12个微操作。如果每个bundle被填满到它的最大容量8个微操作,队列总共可以容纳96个微操作。
在 HC2018 中,Tachyum 建议每个bundle平均有 2.6 条指令。因此,队列的有效容量实际上可能低于 32 个微操作。作为比较,Skylake 在获取阶段之后为每个 SMT 线程提供了一个 25-entry的指令缓冲区,在解码器之后为每个 SMT 线程提供了一个 64-entry的微操作队列,这比 Prodigy 的缓冲能力要强得多,这将使 Skylake 的前端在absorbing stalls方面更加强大。
所以在谈及Prodigy的前端时,让我们来谈谈那些Out of Order的声明。

Tachyum的HC 2018演讲的一部分
Tachyum声称,他们可以实现无序执行与有序的功耗和面积,这在一开始看起来似乎是不可行的主张,但深入一点,可能有一种方式是真实的。Tachyum谈到了一种他们称之为“poison bits”的东西来提取ILP。我们不太清楚这是什么意思,但我们怀疑Tachyum正在使用一种类似于这篇论文中概述的iCFP的技术,该技术由 Chips and Cheese discord 成员 Camacho 发现。iCFP 是这样的一种技术,在您有一个切片缓冲(slice buffer)和检查点(checkpoints ),如果您有一个cache miss,您会以类似于我们之前介绍的 Netburst 的方式replay。现在,iCFP 确实限制了它可以使无序执行,但在我看来,将其称为 OoO 执行是公平的。
这是因为iCFP解决了有序设计的致命弱点:当指令消耗cache miss的结果时就会停止。在传统的无序设计中,调度程序保存等待执行的指令。如果一条指令需要加载结果,它会一直驻留在调度器(scheduler)中,直到数据到达并准备执行。但是,调度器的开销很大,因为可能每个周期都要检查其中的每条指令是否准备好执行。iCFP消除了这种能量损耗和区间浪费,它将cache miss相关(poisoned)指令转移到一个单独的“slice”buffer,并在适当的数据到达时replay它们。
“Replay”可能会触发Netburst对ache miss处理的存储。但与Netburst不同的是,Netburst会不断地repaly指令直到数据到达(data arrives),一个合格的iCFP实现应该只能在数据到达时唤醒适当的“slice”buffer。这将大大减少过度replay造成的功耗和执行单元损耗,特别是在延迟时间较长的cache misses情况下。
但天下没有免费的午餐,而且 iCFP 确实需要大buffer来跟踪等待cache misse的指令以及它们的所有依赖项。不过,这可能是一条有希望的道路。研究表明,iCFP 可以在很大程度上匹配具有较低面积要求的小型无序架构:

与往常一样,新的微架构技术是危险的。尽管大多数尝试过的新技术早在其他公司的 CPU 中首次亮相,但英特尔仍在与 Netburst 作斗争。例如,DEC 的 Alpha EV5 使用了基于 PRF 的乱序执行方案。如果 Tachyum 确实在追求 iCFP,那么说这是一种冒险的方法将是轻描淡写的。据我们所知,iCFP 以前没有实施过。值得记住的是,在 Netburst 首次亮相之前的几年里,关于跟踪缓存的研究很有前景。

然而,众所周知,caching traces的想法导致指令缓存容量的低效使用,并最终注定了它的失败。类似的遗漏缺陷(missed deficiency)也可能对 iCFP 造成同样的影响。最后,Tachyum 并没有说太多暗示 iCFP 正在使用中,只是说“poison bits”被用来提取 ILP。没有提到肯定指向 iCFP 的大型指令缓冲区或检查点机制。
如果不使用 iCFP,Prodigy 的每时钟性能前景看起来很暗淡。当cache miss 的结果被消耗时,该架构会停止,就像今天的其他有序 CPU 一样。当在仿真层上(例如 QEMU,由 Tachyum 演示)运行现有的二进制文件时,这可能特别具有破坏性。

通过修改 ChampSim 的tracer收集结果。如果一条指令的源寄存器与加载指令的目标寄存器相同(具有源内存操作数的指令),并且目标寄存器没有被其间的任何其他指令写入,我们认为它取决于负载。
考虑到没有考虑按顺序限制编译的二进制文件,没有 iCFP(nonblocking loads)的有效重新排序能力将远不及具有无序执行的高性能 CPU 的能力。这反过来意味着 Prodigy 将很难隐藏 L1D misses的延迟。
发生了什么变化?
向量执行
2018 Prodigy 拥有一个非常强大的向量执行引擎,其每个时钟有两个 512b 向量 FMA。2022 Prodigy 使每个时钟最多两个 1024b 矢量 FMA,同时,其矩阵吞吐量也从每个时钟两个 1024b FMA 增加一倍达到每个时钟两个 2048b FMA。这使得 Prodigy 成为所有通用 CPU 中单核最大的 FPU 实现,者远远超过目前市场上的任何 AMD、Arm、IBM 或 Intel CPU。然而,这些大型矢量单元是以裸片面积和功耗为代价的。

将 2018 Prodigy 的向量执行设置与 Skylake-X 进行比较。FMA 单元在 2022 Prodigy 上将是 1024 位宽,尽管我们没有关于矢量执行设置如何更改的确切细节
缓存子系统
向内核提供指令和数据是现代 CPU 设计人员面临的最大挑战之一。与 Intel 和 AMD 一样,Tachyum 为 Prodigy 选择了三级缓存层次结构。
2018 Prodigy 的每个内核只有 16KB 的 L1 数据缓存和 16KB 的 L1 指令缓存,说白了,这小得可怜。2018 Prodigy 每个内核也只有 256KB L2,这也非常小,最后一级是 32MB L3,由 64 个内核共享。但是,Prodigy 似乎在 2020 年或 2021 年进行了修订,将 L1 和 L2 分别翻倍至 32KB 和 512KB,同时将核心数量翻倍至 128,同时还将 L3 翻倍至 64MB。在 2022 Prodigy 中,Tachyum 再次将 L1s 和 L2 翻了一番,达到 64KB 和 1MB。但在缓存层次结构的巨大变化中,Tachyum 在 2022 Prodigy 中使用虚拟 L3 而不是物理 L3,就像 IBM 为 Telum 使用 L3 的方式一样。
对于L3缓存,Tachyum选择了一种动态解决方案,让人想起IBM的Telum (z16)的第三级虚拟缓冲区:“L3实际上是L2,不活跃的核心放弃了它们的资源,”Tachyum的首席执行官透露。
像IBM在Telum上实现的那样的虚拟L3缓存的好处是不需要更传统L3需要的物理空间。这是因为一个单独的缓存块可以充当L2或L3,从而不需要单独的L2。它还利用了对核心本地L3片更快的访问——这是英特尔、AMD或Arm的分布式L3设置所没有的。
然而,使用虚拟缓存可能会比较复杂。您必须决定如何在L2和L3之间分配SRAM容量。2022 Prodigy核心也没有太多的L2。每个内核有1MB的L2内存,而Telum只有32MB。与AMD的Milan相比,Prodigy的最后一级缓存容量也不足,后者每核有4 MB的L3。如果大量的行(line)被提前删除,那么一个专用的L4 victim cache(或者L3,如果您愿意,可以将虚拟L3缓存变成“L2.5”)也可以帮助缓解这种压力。但是Prodigy没有这个。这种效率较低的L3可能意味着Prodigy将努力保持那些巨大的矢量单位,除非DRAM设置可以实现一些神奇的效果。
内存设置
至少在理论上,Prodigy在某种程度上可以做到这一点。芯片有一个巨大的内存和IO设置。Tachyum声称,凭借超高速的DDR5,他们每秒可以从DRAM中获取1tb的数据——这是只有高端GPU和其他加速器才能做到的。

2TB内存带宽旁边的星号表示Tachyum所谓的“带宽放大技术”,由于缺乏信息,我们没有关于该技术的信息,也不会将其纳入我们的结论。
然而,即使这样也可能不够。与用于高性能计算的CPU和GPU相比,Prodigy的计算到内存的带宽比率还是非常低。

DRAM 带宽值是近似值。FP64 FLOPs 假设使用了向量 FMA 操作,而不是矩阵
这可能会导致Prodigy的带宽匮乏,难以进行优化。想要利用它的宽向量单位的程序员必须确保大部分数据都能从缓存中提取出来,但是Prodigy每个核的缓存并不多。相比之下,AMD的EPYC 7763在计算L1、L2和L3时有292MB的SRAM,而T16128总共只有144MB的SRAM。这种SRAM的缺乏可能是由于Tachyum将核心计数和向量执行宽度优先于他们的缓存策略。SRAM容量的缺乏反过来又要求使用虚拟L3等技术,尽可能地使仅有的少量缓存发挥作用。
Prodigy 的 I/O 在 2018 年到 2022 年之间也发生了很大变化。

在 2022 Prodigy 中,Tachyum 选择移除 HBM 和以太网接口,但作为回报,他们进行了一致的 PCIe 设置,同时将 DDR5 内存总线增加了一倍。
在1024b DDR5接口上使用DDR5-7200可以获得921.6 GB/s的内存带宽,这是Genoa使用运行在DDR5-4800上的768b内存总线(460.8 GB/s)的估计内存带宽的两倍。这对于服务器CPU来说是非常好的,但是在尝试提供更多的计算时,仍然落后于A64FX的1TB/s的内存带宽,使用4个HBM2E堆栈。同样看起来不太好的是Prodigy的PCIe 5.0 64道,因为这可能会限制它在I/O繁重的工作负载中,比如Netflix在每个服务器上使用18个PCIe ssd阵列来最大化带宽的用例,而2022 Prodigy无法处理其当前的PCIe配置。
节点、功耗、面积和时钟
2018 Prodigy 将使用台积电当时全新的 N7 节点,其功耗和面积分别为 180 瓦和 280 平方毫米,用于运行在 4 GHz 以上的 64 个内核,这对于服务器 CPU 来说非常高。将其推断为 128 核版本将使其成为 360 瓦 CPU,N7 上的芯片面积为 560 平方毫米。
2022 Prodigy 是一个完全不同的产品。使用台积电的 N5 节点,2022 Prodigy 将是一个 950 瓦 128 核的庞然大物,运行频率高达 5.7 GHz,所有这些都将在大约 500 平方毫米的区域内达成的。

首先,在一个500平方毫米的封装中,950W的热密度在整个芯片中接近每平方毫米2瓦,这是英伟达H100整个芯片每平方毫米0.875瓦热密度的两倍多。至少可以说,这将需要一些令人难以置信的强力冷却方式,而且对一些数据中心来说是不可行的。
所以看看低功耗的sku,你会发现TDP数字、核心计数和时钟速度有些奇怪。不知怎的,T864-HS的功率和T832-HS一样,但核心数是T16128-HT和T864-HT sku的两倍。然后看看T16128-HT和T16128-AIE sku,不知怎的,T16128-HT时钟更高,但其TDP只有T16128-AIE 的一半。
根据 Danilak 的说法,这些报告的时钟是升压时钟。
“这些值包括对时钟的人为节流,以便在 TDP 内发挥作用。”Tachyum 首席执行官 Radoslav Danilak接着说。
然而,我对于Prodigy是否能够在1或2个以上的核上完成整数工作负载有些怀疑。试图以5.7GHz的频率驱动这些巨大的矢量执行单元将需要大量的电力,这可能远远超出Tachyum所能承受的。所以我也不得不怀疑,Tachyum将以某种方式将所有的矢量和矩阵执行到一个大约500平方毫米的die area上。
硬件以外
对于任何新的ISA,您都需要构建软件系统来支持您全新的、全能型的ISA。这也是Tachyum出现更多问题的地方。x86 ISA的成功归功于其强大的软件生态系统。Arm正在成为一个具有竞争力的选择,但Arm的软件生态系统花了数年时间才与之接近。然而,Arm仍然存在一些缺陷,比如新的视频编解码器缺乏适当的向量化,或者以二进制形式分发的应用程序需要转换并招致性能损失。但这些初期的问题与Tachyum面临的问题相比根本不算什么,因为它们是从零开始的。
至于任何面向公众的事情,Tachyum没有对任何主要编译器进行更新,表示它们对GCC的优化将在今年第四季度上线,他们也没有对LLVM做出承诺。
更糟糕的是,Tachyum的ISA与硬件实现紧密相连,以尽可能地减少解码和调度成本。每个 bundle包含与Prodigy的执行单元紧密对应的指令组合。这使得ISA缺乏灵活性。例如,实现一个带有三个FMA单元的新核心将是非常尴尬的,因为现有的bundle设计只能容纳两个FMA指令。新的核心当然可以分离 bundle,并安排单独的RISC操作。这就是基于 Poulson 的 Itaniums 所做的。但随后 Tachyum 将失去将 ISA 与硬件紧密联系在一起的好处。

当Tachyum说他们可以运行x86、ARM和RISC-V二进制文件时,他们使用的是QEMU模拟来运行这些程序。这意味着Prodigy的表现将被削弱到无足轻重的地步。这个Geekbench比较很好地总结了这一点,单线程任务平均损失近90%的性能,多线程任务则损失超过80%的性能,而SIMD任务受QEMU影响最大。
结论
回到那句古老的谚语,Prodigy似乎真的太好了,但不真实。Tachyum承诺,Prodigy将能够成为每个人的一切,而这在500平方毫米的封装中是不可能的,Tachyum说Prodigy适合这个封装。我甚至可以说,要么半导体行业的每个人都是胡说八道的白痴,而Tachyum的员工都是纯粹的天才,要么Tachyum的说法是不可能的。
如果我是一个赌徒,我的钱会投向后者。
如果Tachyum将Prodigy定位为专门的超级计算机部件,就像富士通的A64FX一样,那么我可以认为这是一个利基市场。但他们根本没有这么做,他们称这是一个万能处理器,可以做任何事情。AMD新发布的MI300也声称是“数据中心APU”,可以做Prodigy能做的一切,不同之处在于AMD是一个经过验证的公司。与Tachyum不同, AMD已经建立了一个像MI300这样的产品,自从HSA发布以来,MI300将比500平方毫米大得多,这意味着它远没有接近面积限制,虽然AMD的计算堆栈现在是一团糟,但至少他们有一个比Tachyum好得多的堆栈,这是VLIW架构的关键。
更糟糕的是,Tachyum取消了原先计划的HBM控制器,而采用了更多的DDR5控制器,这些控制器必须以目前完全不现实的DDR5-7200速度运行,以接近A64FX的1tb /s内存带宽。然而,如果Tachyum坚持使用2 HBM3控制器,他们可能会有一个48gb的内存池,运行在超过1.6 TB/s的内存带宽上,同时8个通道的DDR5作为一个更大但更慢的内存池,总共大约2TB/s的内存带宽;更不用说,他们只需要提供原2018年64核2TB/s内存配置的计算能力的四分之一,或者是2018年128核的128核Prodigy的一半,内存带宽可能为4TB/s,这是同一个bubble上的2个64核芯片。
Prodigy必须以小于1TB/s的内存带宽提供多达45TFlops的FP64 Vector计算,这是一个超过50:1的FP64 Vector计算与内存带宽比率。作为比较,MI250X拥有类似数量的FP64矢量计算(47.8TFlops)和总SRAM数量(MI250X为156.25MB, Prodigy为144MB),它拥有超过3.5倍的内存带宽来满足庞大的FP64计算,这使得MI250X的FP64矢量计算与内存带宽的比率略低于15:1。专门的HPC CPU A64FX是FP64矢量计算内存带宽比3.4:1。

Golem.de 采访中的 Tachyum 路线图
Tachyum 声称将在“第三季度下半年”流片 Prodigy ,12 月开始提供样品,2023 年上半年开始生产。对于一家以前从未流片过芯片的公司来说,这似乎非常乐观。但是,如果我们确实假设 Prodigy 可以在 2023 年上半年投入生产,那么它将不得不与 NVIDIA 的 Grace-Hopper Superchip 以及之前提到的 AMD 的 MI300 抗衡,而这两种芯片很可能会在较低功率下击败 Prodigy 的性能。
Tachyum 还表示,他们正计划在台积电的 N3 工艺上推出 Prodigy 2,它将支持更多内核、PCIe 6.0 和 CXL。但是 Prodigy 2 直到 2024 年下半年才会出样,这意味着它正在与 AMD、Intel 和 Nvidia 的下一代产品竞争,这很可能会使 Prodigy 2 变得多余。
Tachyum 确实让自己陷入了困境。如果他们能够在 2020 年完成生产芯片的时间表,他们将面临一场非常艰苦的战斗,但他们本可以获胜。但现在是 2022 年,那座山看起来更像是一个 90 度的悬崖面,简直无法逾越。我们喜欢看到失败者突然冒出来并击败卫冕冠军。但 Tachyum 很大概率不会这样。
★ 点击文末【阅读原文】,可查看本文原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3088内容,欢迎关注。
晶圆|集成电路|设备|汽车芯片|存储|台积电|AI|封装

原文链接!
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






