云原生通用策略:面向流批一体与云原生的
简介:Flink Remote Shuffle 正式开源!作为支持 Flink 流批一体与云原生的重要组成部分,Flink Remote Shuffle 今天正式开源了:https://github.com/flink-extended/flink-remote-shuffle
Flink Remote Shuffle 是一种批场景下利用外部服务完成任务间数据交换的 Shuffle 实现,本文后续将详细介绍 Flink Remote Shuffle 研发的背景,以及 Flink Remote Shuffle 的设计与使用。
一、为什么需要 Flink Remote Shuffle ?
1.1 背景
Flink Remote Shuffle 的提出与实现,源自我们观察到的用户对流批一体与云原生日益增加的需求。
由于实时处理可以大幅提升用户体验以及增加产品在市场的竞争力,越来越多的用户业务场景中同时包含了实时和离线处理需求。如果流处理和批处理采用不同的框架来完成,将带来用户在框架学习、代码开发与线上运维的诸多不便。同时,对于许多应用场景,由于实时处理受限于延迟数据(例如用户可能隔很久才会填写评论)或业务逻辑升级等原因,必须采用离线任务进行数据订正,采用两种不同的框架编写两份代码逻辑很容易产生计算结果不一致的问题。
针对这些问题,Flink 提出了流批一体的数据模型,即用一套 API 来完成实时数据与离线数据的处理。为了支持这一目标,Flink 设计与实现了流批统一的 DataStream API [1] Table / SQL API [2] Connector [3][4] ,并在执行层支持流批一体的调度 [5] 与面向批处理进行优化的 Batch 执行模式 [6]。而为了支持 Batch 模式,还需要 Flink 能够实现高效与稳定的 Blocking Shuffle。Flink 内置的 Blocking Shuffle 在上游结束后继续依赖上游所在的 TaskManager 来为下游提供数据读取服务,这将导致 TaskManager 不能立即释放从而降低资源利用率,并导致 Shuffle 服务的稳定性受 Task 执行稳定性的影响。
另一方面,由于云原生可以更好的支持离线在线混部来提高集群资源利用率,提供统一的运维操作接口减少运维成本,并支持通过资源动态编排来实现作业的自动伸缩,越来越多的用户开始使用 K8s 来管理它们的集群资源。Flink 积极拥抱云原生,除提供了对 K8s 的原生支持外 [7][8] ,Flink 提供了根据资源量进行动态伸缩的 Adaptive Scheduler [9], 并逐步推动 State 的存储计算分离 [10]。为了使 Batch 模式也能更好的支持云原生,Shuffle 过程做为本地磁盘的最大使用者,如何实现 Blocking Shuffle 的存储计算分离,减少对本地磁盘的占用,使得计算资源与存储资源不再相互耦合,也是必须要解决的问题。
因此,为了更好的支持流批一体与云原生,通过使用独立的 Shuffle 服务来实现任务间的数据传输是必由之路。
1.2 Flink Remote Shuffle 的优势
Flink Remote Shuffle 正是基于上述思路来设计与实现的。它支持了许多重要特性,包括:
- 存储计算分离:存储计算分离使计算资源与存储资源可以独立伸缩,计算资源可以在计算完成后立即释放,Shuffle 稳定性不再受计算稳定性影响。
- 支持多种部署模式:支持 Kubernetes、YARN 以及 Standalone 环境下部署。
- 采用了类似 Flink Credit-Based 流量控制机制,实现了零拷贝数据传输,最大限度的使用受管理的内存 (managed memory) 以避免 OOM,提高了系统稳定性与性能。
- 实现了包括负载均衡、磁盘 IO 优化、数据压缩、连接复用、小包合并等诸多优化,实现了优秀的性能与稳定性表现。
- 支持 Shuffle 数据正确性校验,能够容忍 Shuffle 进程乃至物理节点重启。
- 结合 FLIP-187: Flink Adaptive Batch Job Scheduler [11] 可支持动态执行优化,如动态决定算子并发度。
1.3 生产实践
从 2020 双十一开始,阿里内部许多核心任务开始选择基于Flink的流批一体处理链路,这也是业界首次完成流批一体大规模的生产实践的落地。通过流批一体处理技术,解决了如天猫营销引擎等场景下流批处理口径一致性的问题,将数据报表开发效率提升了 4 到 10 倍,并且通过流作业与批作业混部实现资源白天与夜晚的削峰填谷,资源成本节省了 1 倍。
而做为流批一体技术的重要一环,Flink Remote Shuffle 自上线已来,最大的集群规模已达千台以上,在历次大促中平稳的支持了天猫营销引擎、天猫国际等多个业务方,作业规模超过 PB 级别,充分证明了系统的稳定性与性能。
二、Flink Remote Shuffle 的设计与实现
2.1 Flink Remote Shuffle 整体架构
Flink Remote Shuffle 是基于 Flink 统一插件化 Shuffle 接口来实现的。Flink 作为流批一体的数据处理平台,在不同场景可以适配多种不同的 Shuffle 策略,如基于网络的在线 Pipeline Shuffle,基于 TaskManager 的 Blocking Shuffle 和基于远程服务的 Remote Shuffle。
这些 Shuffle 策略在传输方式、存储介质等方面存在较大差异,但是它们在数据集的生命周期、元数据管理与通知下游任务、数据分发策略等方面存在了许多共性的需求。为了为不同类型的 Shuffle 提供统一支持,简化包括 Flink Remote Shuffle 在内的新的 Shuffle 策略的实现,Flink 中引入了插件化的 Shuffle 架构 [12] 。
如下图所示,一个 Shuffle 插件主要由两部分组成,即在 JobMaster 端负责资源申请与释放的 ShuffleMaster 与在 TaskManager 端负责数据实际读写的 InputGate 与 ResultPartition。调度器通过 ShuffleMaster 申请资源后交由 PartitionTracker 进行管理,并在上游和下游任务启动时携带 Shuffle 资源的描述符来描述数据输出和读取的位置。
基于 Flink 统一插件化 Shuffle 接口,Flink Remote Shuffle 通过一个单独的集群提供数据 shuffle 服务。该集群采用经典的 master-slave 结构,其中 ShuffleManager 作为整个集群的 master 结点,负责对 worker 结点进行管理,以及对 Shuffle 数据集进行分配与管理。ShuffleWorker 作为集群的 slave 结点,负责数据集实际的读写与清理。
当上游 Task 启动时,Flink 的调度器将通过 RemoteShuffleMaster 插件向 ShuffleManager 申请资源,ShuffleManager 将根据数据集的类型与各个 Worker 的负载选择合适的 Worker 提供服务。当调度器拿到相应的 Shuffle 资源描述符时,会在启动上游 Task 时携带该描述符。上游 Task 根据描述符中记录的 ShuffleWorker 地址将数据发送给相应的 ShuffleWorker 进行持久化存储。相对的,当下游 Task 启动后,将根据看描述符中记录的地址从相应的 ShuffleWorker 进行读取,从而完成整个数据传输的过程。
作为一个长时间运行的服务,系统的错误容忍与自愈能力是非常关键的。Flink Remote Shuffle 通过心跳等机制对 ShuffleWorker 与 ShuffleMaster 进行监听,并在心跳超时、IO 失败等异常出现时候对数据集进行删除与状态同步,从而维护整个集群状态的最终一致性。更多关于异常情况的处理,可以参考 Flink Remote Shuffle 相关文档 [13] 。
2.2 数据 Shuffle 协议与优化
数据远程 Shuffle 可划分为读写两个阶段。在数据写阶段,上游计算任务的输出数据被写到远程的 ShuffleWorker;在数据读阶段,下游计算任务从远程的 ShuffleWorker 读取上游计算任务的输出并进行处理。数据 Shuffle 协议定义了这一过程中的数据类型、粒度、约束以及流程等。总体而言,数据的写出 - 读取流程如下:
数据写出
数据读取
在整个数据读写的过程中,实现了多种优化手段,包括数据压缩,流量控制,减少数据拷贝,使用受管理内存等:
- Credit-based 流量控制:流量控制是生产者 - 消费者模型需要考虑的一个重要问题,目的是避免消费速度慢导致数据无限堆积。Flink Remote Shuffle 采用了和 Flink 类似的 Credit-based 流量控制机制,即只有在数据接收端有足够缓冲区来接收数据时,数据发送端才会发送这些数据。而数据接收端在不断处理数据的过程中,也会将释放的缓冲区反馈给发送端继续发送新的数据,这样不断往复实现流式的数据发送,类似于 TCP 的滑动窗口机制。Credit-based 流量控制机制可以很好的避免下游在接收缓冲区不足时无效的落盘,也可以在 TCP 连接复用场景下避免因为一条逻辑链路拥塞影响其他逻辑链路。对这一机制感兴趣可以参考 Flink 的博客 [14]。
- 数据压缩:数据压缩是一个简单而有效的优化手段,其效果已经被广泛应用和证明,是一个必选项。Flink Remote Shuffle 也实现了数据压缩。具体而言,数据会在生产者写出到远端 ShuffleWorker 前进行压缩,并在消费者从远端 ShuffleWorker 读取后进行解压。这样可以达到同时减少网络与文件 IO 的目的,同时减少网络带宽与磁盘存储空间的占用,提升了 IO 效率。
- 减少数据拷贝:在进行网络与文件 IO 时,Flink 最大限度的使用直接内存 (Direct Memory),这样便减少了 Java 堆内存的拷贝,提升了效率,同时也有利于减少直接内存的动态申请,有利于提升稳定性。
- 使用受管理内存:对于 Shuffle 数据传输以及文件 IO 所使用的大块内存,Flink Remote Shuffle 均使用预申请的受管理内存,即预先申请内存建立内存池,后续内存申请释放均在内存池中进行,这样减少了内存动态申请释放的开销 (系统调用以及 GC),更重要的是有利于避免 OOM 问题的产生,极大的增强了系统的稳定性。
- TCP 连接复用:对于同一个 Flink 计算节点到同一个远程 ShuffleWorker 的数据读或写连接会复用相同的物理 TCP 连接,这有利于减少网络连接数量,提升数据读写稳定性。
2.3 存储与文件 IO 优化
对于落盘 Shuffle 而言,尤其是在机械硬盘上,文件 IO 会成为重要的瓶颈,优化文件 IO 会取得很好的加速效果。
除了上面提到的数据压缩,一个被广泛采用的技术方案是进行小文件或者说是小数据块合并,从而增加文件的顺序读写,避免过多的随机读写,最终优化文件 IO 性能。对于非远程的计算节点间的直接 Shuffle,包括 Spark 等系统都实现了将小块数据合并成大块的优化。
对于远程 Shuffle 系统的数据合并方案,根据我们的调研,最早是由 Microsoft & LinkedIn & Quantcast 在一篇论文 Sailfish [15] 中提出的,后来包括 Princeton & Facebook 的 Riffle [16],Facebook 的 Cosco [17],LinkedIn 的 Magnet [18],Alibaba EMR 的 Spark 远程 Shuffle [19] 都实现了类似的优化思路,即将由不同的上游计算任务发送给相同下游计算任务的 Shuffle 数据推送给相同的远端 Shuffle 服务节点进行合并,下游计算任务可以直接从这些远端的 Shuffle 服务节点拉取合并后的数据。
除了这一优化思路外,我们在 Flink 的计算节点间的直接 Shuffle 实现中提出了另一种优化思路,即 Sort-Spill 加 IO 调度,简单而言就是在计算任务的输出数据填满内存缓冲区后对数据进行排序 (Sort),排序后的数据写出 (Spill) 到文件中,并且在写出过程中避免了写出多个文件,而是始终向同一个文件追加数据,在数据读取的过程中,增加对数据读取请求的调度,始终按照文件的偏移顺序读取数据,满足读取请求,在最优的情况下可以实现数据的完全顺序读取。下图展示了基本的存储结构与 IO 调度流程,更具体的细节可参考 Flink 博客 [20] 或者中文版 [21]。
这两种方案各有一些优势和不足:
- 容错方面,数据合并的方案对于数据丢失的容忍度更低,由于同一文件中包含由所有并发计算任务合并产生数据,因此一旦一个文件丢失,则需要重跑所有生产者并发,开销巨大,所以为了避免这一开销,可能需要采用备份等方式避免发生重算,然而备份也意味着更多的文件 IO (降低性能) 以及更多存储空间占用。而 IO 调度的方案,对于数据损坏或丢失,只需要重新生成丢失的数据即可。此外,对于生产者任务的失败处理,数据合并的方式也更为复杂,因为需要清理或者标记失败的数据段,然后读取时跳过这些数据,或者在读取时进行去重,跳过这些数据。而对于 IO 调度的方案,只需要丢弃失败的生产者产生的数据文件即可。
- 性能上,一般情况下,两者都可以实现很好的文件 IO 吞吐,然而特殊情况下,IO 调度方案也有一些不足,比如 IO 调度依赖消费者计算任务的数据请求,如果下游消费者无法同时被拉起,则会影响数据的顺序读取,降低文件 IO 性能。此外,如果需要对数据本身进行排序,数据合并的方式将更有利,因为需要排序的数据在同一个文件中。类似的,如果需要写数据到分布式文件系统等外部系统,数据合并的方式也更为有利,因为这些外部系统不太容易实现 IO 调度优化。
- 在文件数量上,数据合并的方式文件数量和消费者任务的数量相等,IO 调度的方案文件数量和生产者任务的数量相等。
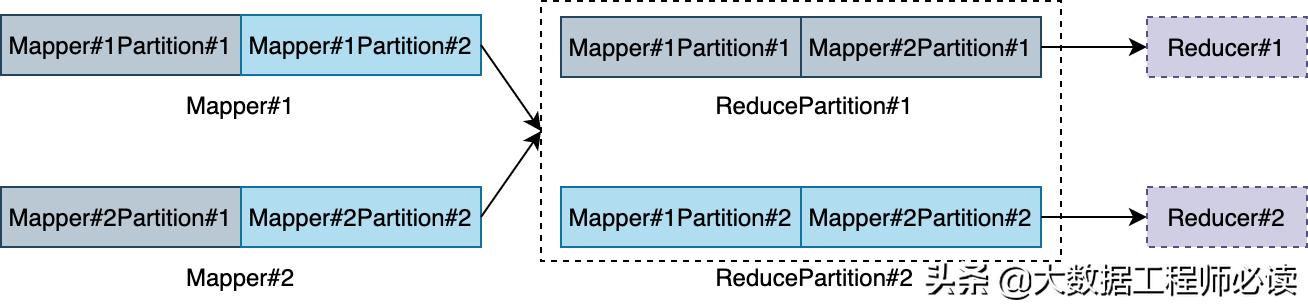
Flink Remote Shuffle 的抽象不排斥任何一种优化策略。事实上,Flink Remote Shuffle 可被看作是一个可以感知 Map-Reduce 语义的中间数据存储服务,其基本数据存储单元是数据分区 (DataPartition),数据分区有两种基本的类型,分别是 MapPartition 和 ReducePartition。其中 MapPartition 包含的数据由一个上游计算任务产生并可能会被多个下游计算任务消费,下面的示意图展示了 MapPartition 的产生与消费:
而 ReducePartition 由多个上游计算任务的输出合并产生并被单个下游计算任务消费。下面的示意图展示了 ReducePartition 的产生与消费:
三、部署使用与评估
3.1 多环境部署与运维
支持在多种环境部署,满足差异化的部署需求是一个重要能力。具体而言,Flink Remote Shuffle 支持 Kubernetes、YARN 以及 Standalone 三种部署模式,可以满足绝大部分用户的部署环境需求。在每种部署模式下,都有一些便捷化脚本和模板可供用户使用。更加详细的信息可以参考文档:Kubernetes 模式部署 [22] 、YARN 模式部署 [23] 以及 Standalone 模式部署 [24] 。其中,Kubernetes 模式与 YARN 模式部署实现了主节点 (ShuffleManager) 高可用,Standalone 模式部署的主节点高可用将在未来版本支持。
除此之外,Flink Remote Shuffle 的 Metric 系统还提供了若干重要的监控指标可供用户监控整个系统的运行状态,包括活跃节点数量、作业总量、每个节点上可用缓冲区数量、数据分区数量、网络连接数量、网络吞吐、JVM 指标等信息,未来会不断增加更多的监控指标以方便用户的运维操作。用户可以直接访问各个进程 (ShuffleManager & ShuffleWorker) 的 Metric 服务查询相应的指标数据,具体可参考用户文档 [25]。未来将会提供 Metric 指标汇报能力,允许用户将指标主动汇报到外部系统如 Prometheus 等。
基本来说,Flink Remote Shuffle 的部署与运维比较简单,未来会持续提升部署与运维方面的体验,简化信息采集与问题定位、提高自动化程度、降低运维成本。
3.2 多版本兼容性
由于远程 Shuffle 系统分为客户端和服务端两个部分,服务端作为一个独立的集群单独运行,而客户端作为 Flink 作业访问远端 Shuffle 服务的代理运行在 Flink 集群,在部署模式上,可能存在有很多用户通过不同 Flink 集群访问同一套 Shuffle 服务的情况,因此多版本兼容性是用户比较关心的一个问题。而 Shuffle 服务本身的版本会随着新的 Feature 或者优化而不断升级,如果出现客户端与服务端的不兼容,最简单的办法是让不同用户的客户端也一起跟着升级,但这往往需要用户的配合,不总是可以做到。
能够绝对保证版本间兼容是最好的,为了最大限度的实现这一点,Flink Remote Shuffle 也做了很多工作,包括:
- 版本信息与保留字段:在所有的协议消息中加入版本信息与保留字段,这样有利于在后续更改协议字段时保持兼容;
- 增加存储格式版本:存储格式版本保留在存储的数据中,这样新版本的 Shuffle 存储节点可以直接接管老的数据,避免数据重新生成的开销;
- 不同版本不同处理:通过对不同版本做不同的处理,可以使新版本兼容老版本的逻辑,同时服务端还可以借此监控客户端老版本的使用;
- 兼容版本服务发现:客户端的服务发现可以允许多个版本的 Shuffle 服务同时运行,并且总是会寻找使用与自己版本兼容的服务。
通过这些努力,我们期望做到不同版本间的完全兼容,避免出现不必要的 “惊喜”,当然如果期望使用新版本的更多新功能与优化,还是需要升级客户端版本。
3.3 稳定性与性能评估
生产应用表明,Flink Remote Shuffle 具有良好的稳定性与性能表现。这主要得益于诸多的性能与稳定性优化。
能够提高稳定性的设计与优化包括:存算分离使得 Shuffle 稳定性不受计算稳定性影响;Credit-based 流量控制可根据消费者处理能力发送数据,避免消费者被压垮;连接复用,小包合并以及主动网络连接健康检查等优化提升网络稳定性;最大限度的使用被管理的内存极大的避免了 OOM 的可能;数据校验使得系统可容忍进程乃至物理节点重启。
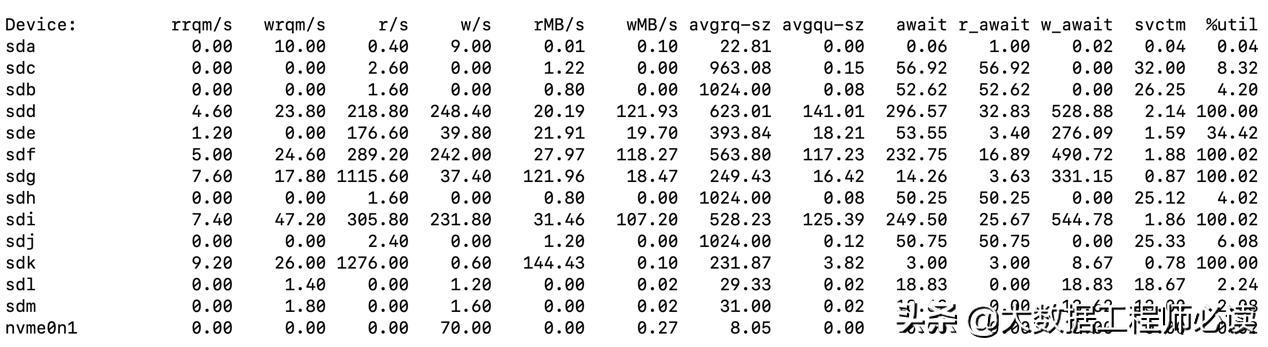
而性能方面,数据压缩、负载均衡以及文件 IO 优化等都很好的提升了数据 Shuffle 性能。在小数据量场景下,由于 Shuffle 数据大多存在操作系统的缓存中,Flink Remote Shuffle 与计算节点间直接 Shuffle 性能接近,相差不大。在大数据量场景下,得益于中心化的决策能力 (ShuffleManager 节点的负载均衡,单个 ShuffleWorker 节点统一管理整个物理机 IO),Flink Remote Shuffle 的性能要更胜一筹,下面截图展示了 Flink Remote Shuffle 在运行作业 (TPC-DS q78) 时的磁盘 IO 信息:
从图中可以看出,我们使用了 sdd、sde、sdf、sdg、sdi 与 sdk 这几块盘,磁盘吞吐还是比较高的,后我们会持续进行优化。
四、未来展望
目前的 Flink Remote Shuffle 版本通过内部的大规模上线使用,已经证明了其在性能与稳定性方面是生产可用的。未来,我们会对 Flink Remote Shuffle 进行持续的迭代改进与增强,已经有若干工作项在我们的计划中,包括性能、易用性等诸多方面,我们也非常希望有更多的感兴趣的小伙与我们一起参与到后续的使用与改进中,共同推进 Flink 流批一体与云原生发展。更多信息交流请钉钉扫描下方二维码或搜索群号 35065720。
参考文献
[1] https://cwiki.apache.org/confluence/display/FLINK/FLIP-134: Batch execution for the DataStream API
[4] https://cwiki.apache.org/confluence/display/FLINK/FLIP-143: Unified Sink API
[5] https://cwiki.apache.org/confluence/display/FLINK/FLIP-119 Pipelined Region Scheduling
[9] https://cwiki.apache.org/confluence/display/FLINK/FLIP-160: Adaptive Scheduler
[10] https://cwiki.apache.org/confluence/display/FLINK/FLIP-158: Generalized incremental checkpoints
[11] https://cwiki.apache.org/confluence/display/FLINK/FLIP-187: Adaptive Batch Job Scheduler
[12] https://cwiki.apache.org/confluence/display/FLINK/FLIP-31: Pluggable Shuffle Service
[13] https://github.com/flink-extended/flink-remote-shuffle/docs/user_guide.md#fault-tolerance
[14] https://flink.apache.org/2019/06/05/flink-network-stack.html
[15] Rao S, Ramakrishnan R, Silberstein A, et al. Sailfish: A framework for large scale data processing[C]//Proceedings of the Third ACM Symposium on Cloud Computing. 2012: 1-14.
[16] Zhang H, Cho B, Seyfe E, et al. Riffle: optimized shuffle service for large-scale data analytics[C]//Proceedings of the Thirteenth EuroSys Conference. 2018: 1-15.
[17] https://databricks.com/session/cosco-an-efficient-facebook-scale-shuffle-service
[18] Shen M, Zhou Y, Singh C. Magnet: push-based shuffle service for large-scale data processing[J]. Proceedings of the VLDB Endowment, 2020, 13(12): 3382-3395.
[19] https://developer.aliyun.com/article/772329
[20] https://flink.apache.org/2021/10/26/sort-shuffle-part2.html
[21] https://mp.weixin.qq.com/s/M5lGOYu0Bwaspa8G0x5NHQ
[22] https://github.com/flink-extended/flink-remote-shuffle/blob/master/docs/deploy_on_kubernetes.md
[23] https://github.com/flink-extended/flink-remote-shuffle/blob/master/docs/deploy_on_yarn.md
[24] https://github.com/flink-extended/flink-remote-shuffle/blob/master/docs/deploy_standalone_mode.md
[25] https://github.com/flink-extended/flink-remote-shuffle/blob/master/docs/user_guide.md
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。,






免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






