storm入门demo(Storm源码分析之Trident源码分析)
@(STORM)[storm]
- Storm源码分析之四 Trident源码分析
- 一概述
- 0小结
- 1简介
- 2关键类
- 1Spout的创建
- 2spout的消息流
- 3spout调用的整体流程
- 4spout如何被 加载到拓扑中
- 二Spout
- 一Spout的创建
- 1ItridentSpout
- 2BatchCoordinator
- 3Emmitter
- 4一个示例
- 二spout实际的消息流
- 1MasterBatchCoordinator
- 2TridentSpoutCoordinator
- 3TridentSpoutExecutor
- 三bolt
- 一概述
- 1组件的基本关系
- 2用户视角与源码视角
- 二基础类
- 1Stream
- 1成员变量
- 2projectionValidation
- 3project
- 2Node SpoutNode PartitionNode ProcessorNode
- 详细分析见书
- 3group
- 1成员变量
- 2构造方法
- 3outgoingNodes
- 4incommingNodes
- 4GraphGrouper
- 1成员变量
- 2构造方法
- 3reindex
- 4nodeGroup
- 5outgoingGroups
- 6incomingGroups
- 7merge
- 8mergeFully
- 四在TridentTopoLOGyBuilder中设置Spoutbolt
- 一参考内容
- 一概述
- 二基础类
- 1GlobalStreamId
- 三TridentTopology
- 1生成bolt的名称genBoltIds
- 2添加节点addNode
- 3添加节点addSourceNode
- 四TridentTopologyBuilder
0、小结
TridentTopologyBuilder与TridentTopology调用MBC/TSC/TSE设置spout与2个bolt,而这三个类通过调用用户代码Spout中定义的Coordinator与Emitter完成真正的逻辑。
最后构建好的拓扑会提交至nimbus,nimbus开始调度这个拓扑,开始运行。
1、简介
trident是storm的更高层次抽象,相对storm,它主要提供了3个方面的好处:
(1)提供了更高层次的抽象,将常用的count,sum等封装成了方法,可以直接调用,不需要自己实现。
(2)以批次代替单个元组,每次处理一个批次的数据。
(3)提供了事务支持,可以保证数据均处理且只处理了一次。
本文介绍了在一个Trident拓扑中,spout是如何被产生并被调用的。首先介绍了用户如何创建一个Spout以及其基本原理,然后介绍了Spout的实际数据流,最后解释了在创建topo时如何设置一个Spout。
2、关键类
MaterBatchCorodeinator —————> ITridentSpout.Coordinator#isReady
|
4、spout如何被 加载到拓扑中
(1)在TridentTopologyBuilder的buildTopololg方法中设置了topo的相关信息
(2)在TridentTopology中调用newStream方法,将spout节点加入拓扑。
包括MBC, TSC, TSE等均是在上面2个类中被调用,从而形成一个完整的拓扑。
二、Spout(一)Spout的创建
1、ItridentSpout
在Trident中用户定义的Spout需要实现ItridentSpout接口。我们先看看ItridentSpout的定义
package storm.trident.spout;
import backtype.storm.task.TopologyContext;
import storm.trident.topology.TransactionAttempt;
import backtype.storm.tuple.Fields;
import java.io.Serializable;
import java.util.Map;
import storm.trident.operation.TridentCollector;
public interface ITridentSpout<T> extends Serializable {
public interface BatchCoordinator<X> {
X initializeTransaction(long txid, X prevMetadata, X currMetadata);
void success(long txid);
boolean isReady(long txid)
void close();
}
public interface Emitter<X> {
void emitBatch(TransactionAttempt tx, X coordinatorMeta, TridentCollector collector);
void success(TransactionAttempt tx);
void close();
}
BatchCoordinator<T> getCoordinator(String txStateId, Map conf, TopologyContext context);
Emitter<T> getEmitter(String txStateId, Map conf, TopologyContext context);
Map getComponentConfiguration();
Fields getOutputFields();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
它有2个内部接口,分别是BatchCoordinator和Emitter,分别是用于协调的Spout接口和发送消息的Bolt接口。实现一个Spout的主要工作就在于实现这2个接口,创建实际工作的Coordinator和Emitter。Spout中提供了2个get方法用于分别用于指定使用哪个Coordinator和Emitter类,这些类会由用户定义。稍后我们再分析Coordinator和Emitter的内容。
除此之外,还提供了getComponentConfiguration用于获取配置信息,getOutputFields获取输出field。
我们再看看2个内部接口的代码。
2、BatchCoordinator
public interface BatchCoordinator<X> {
X initializeTransaction(long txid, X prevMetadata, X currMetadata);
void success(long txid);
boolean isReady(long txid);
void close();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(1)initializeTransaction方法返回一个用户定义的事务元数据。X是用户自定义的与事务相关的数据类型,返回的数据会存储到zk中。
其中txid为事务序列号,prevMetadata是前一个事务所对应的元数据。若当前事务为第一个事务,则其为空。currMetadata是当前事务的元数据,如果是当前事务的第一次尝试,则为空,否则为事务上一次尝试所产生的元数据。
(2)isReady方法用于判断事务所对应的数据是否已经准备好,当为true时,表示可以开始一个新事务。其参数是当前的事务号。
BatchCoordinator中实现的方法会被部署到多个节点中运行,其中isReady是在真正的Spout(MasterBatchCoordinator)中执行的,其余方法在TridentSpoutCoordinator中执行。
3、Emmitter
public interface Emitter<X> {
void emitBatch(TransactionAttempt tx, X coordinatorMeta, TridentCollector collector);
void success(TransactionAttempt tx);
void close();
}
- 1
- 2
- 3
- 4
- 5
- 6
消息发送节点会接收协调spout的$batch和$success流。
(1)当收到$batch消息时,节点便调用emitBatch方法来发送消息。
(2)当收到$success消息时,会调用success方法对事务进行后处理
4、一个示例
参考 DiagnosisEventSpout
(1)Spout的代码
package com.packtpub.storm.trident.spout;
import backtype.storm.task.TopologyContext;
import backtype.storm.tuple.Fields;
import storm.trident.spout.ITridentSpout;
import java.util.Map;
@SuppressWarnings("rawtypes")
public class DiagnosisEventSpout implements ITridentSpout<Long> {
private static final long serialVersionUID = 1L;
BatchCoordinator<Long> coordinator = new DefaultCoordinator();
Emitter<Long> emitter = new DiagnosisEventEmitter();
@Override
public BatchCoordinator<Long> getCoordinator(String txStateId, Map conf, TopologyContext context) {
return coordinator;
}
@Override
public Emitter<Long> getEmitter(String txStateId, Map conf, TopologyContext context) {
return emitter;
}
@Override
public Map getComponentConfiguration() {
return null;
}
@Override
public Fields getOutputFields() {
return new Fields("event");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
(2)BatchCoordinator的代码
package com.packtpub.storm.trident.spout;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import storm.trident.spout.ITridentSpout.BatchCoordinator;
import java.io.Serializable;
public class DefaultCoordinator implements BatchCoordinator<Long>, Serializable {
private static final long serialVersionUID = 1L;
private static final Logger LOG = LoggerFactory.getLogger(DefaultCoordinator.class);
@Override
public boolean isReady(long txid) {
return true;
}
@Override
public void close() {
}
@Override
public Long initializeTransaction(long txid, Long prevMetadata, Long currMetadata) {
LOG.info("Initializing Transaction [" txid "]");
return null;
}
@Override
public void success(long txid) {
LOG.info("Successful Transaction [" txid "]");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
(3)Emitter的代码
package com.packtpub.storm.trident.spout;
import com.packtpub.storm.trident.model.DiagnosisEvent;
import storm.trident.operation.TridentCollector;
import storm.trident.spout.ITridentSpout.Emitter;
import storm.trident.topology.TransactionAttempt;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
public class DiagnosisEventEmitter implements Emitter<Long>, Serializable {
private static final long serialVersionUID = 1L;
AtomicInteger successfulTransactions = new AtomicInteger(0);
@Override
public void emitBatch(TransactionAttempt tx, Long coordinatorMeta, TridentCollector collector) {
for (int i = 0; i < 10000; i ) {
List<Object> events = new ArrayList<Object>();
double lat = new Double(-30 (int) (Math.random() * 75));
double lng = new Double(-120 (int) (Math.random() * 70));
long time = System.currentTimeMillis();
String diag = new Integer(320 (int) (Math.random() * 7)).toString();
DiagnosisEvent event = new DiagnosisEvent(lat, lng, time, diag);
events.add(event);
collector.emit(events);
}
}
@Override
public void success(TransactionAttempt tx) {
successfulTransactions.incrementAndGet();
}
@Override
public void close() {
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
(4)最后,在创建topo时指定spout
TridentTopology topology = new TridentTopology();
DiagnosisEventSpout spout = new DiagnosisEventSpout();
Stream inputStream = topology.newStream("event", spout);
- 1
- 2
- 3
- 4
(二)spout实际的消息流
以上的内容说明了如何在用户代码中创建一个Spout,以及其基本原理。但创建Spout后,它是怎么被加载到拓扑真正的Spout中呢?我们继续看trident的实现。
1、MasterBatchCoordinator
总体而言,MasterBatchCoordinator作为一个数据流的真正起点:
* 首先调用open方法完成初始化,包括读取之前的拓扑处理到的事务序列号,最多同时处理的tuple数量,每个事务的尝试次数等。
* 然后nextTuple会改变事务的状态,或者是创建事务并发送$batch流。
* 最后,ack方法会根据流的状态向外发送$commit流,或者是重新调用sync方法,开始创建新的事务。
总而言之,MasterBatchCoordinator作为拓扑数据流的真正起点,通过循环发送协调信息,不断的处理数据流。MasterBatchCoordinator的真正作用在于协调消息的起点,里面所有的map,如_activeTx,_attemptIds等都只是为了保存当前正在处理的情况而已。
(1)MasterBatchCoordinator是一个真正的spout
public class MasterBatchCoordinator extends BaseRichSpout
- 1
- 2
一个Trident拓扑的真正逻辑就是从MasterBatchCoordinator开始的,先调用open方法完成一些初始化,然后是在nextTuple中发送$batch和$commit流。
(2)看一下open方法
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_throttler = new WindowedTimeThrottler((Number)conf.get(Config.TOPOLOGY_TRIDENT_BATCH_EMIT_INTERVAL_MILLIS), 1);
for(String spoutId: _managedSpoutIds) {
//每个MasterBatchSpout可以处理多个ITridentSpout,这里将多个spout的元数据放到_states这个Map中。稍后再看看放进来的是什么内容。
_states.add(TransactionalState.newCoordinatorState(conf, spoutId));
}
//从zk中获取当前的transation事务序号,当拓扑新启动时,需要从zk恢复之前的状态。也就是说zk存储的是下一个需要提交的事务序号,而不是已经提交的事务序号。
_currTransaction = getStoredCurrTransaction();
_collector = collector;
//任何时刻中,一个spout task最多可以同时处理的tuple数量,即已经emite,但未acked的tuple数量。
Number active = (Number) conf.get(Config.TOPOLOGY_MAX_SPOUT_PENDING);
if(active==null) {
_maxTransactionActive = 1;
} else {
_maxTransactionActive = active.intValue();
}
//每一个事务的当前尝试编号,即_currTransaction这个事务序号中,各个事务的尝试次数。
_attemptIds = getStoredCurrAttempts(_currTransaction, _maxTransactionActive);
for(int i=0; i<_spouts.size(); i ) {
//将各个Spout的Coordinator保存在_coordinators这个List中。
String txId = _managedSpoutIds.get(i);
_coordinators.add(_spouts.get(i).getCoordinator(txId, conf, context));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
(3)再看一下nextTuple()方法,它只调用了sync()方法,主要完成了以下功能:
* 如果事务状态是PROCESSED,则将其状态改为COMMITTING,然后发送commit流。接收到
commit流。接收到commit流的节点会调用finishBatch方法,进行事务的提交和后处理
* 如果_activeTx.size()小于_maxTransactionActive,则新建事务,放到_activeTx中,同时向外发送$batch流,等待Coordinator的处理。( 当ack方法被 调用时,这个事务会被从_activeTx中移除)
注意:当前处于acitve状态的应该是序列在[_currTransaction,_currTransaction _maxTransactionActive-1]之间的事务。
private void sync() {
// note that sometimes the tuples active may be less than max_spout_pending, e.g.
// max_spout_pending = 3
// tx 1, 2, 3 active, tx 2 is acked. there won't be a commit for tx 2 (because tx 1 isn't committed yet),
// and there won't be a batch for tx 4 because there's max_spout_pending tx active
//判断当前事务_currTransaction是否为PROCESSED状态,如果是的话,将其状态改为COMMITTING,然后发送$commit流。接收到$commit流的节点会调用finishBatch方法,进行事务的提交和后处理。
TransactionStatus maybeCommit = _activeTx.get(_currTransaction);
if(maybeCommit!=null && maybeCommit.status == AttemptStatus.PROCESSED) {
maybeCommit.status = AttemptStatus.COMMITTING;
_collector.emit(COMMIT_STREAM_ID, new Values(maybeCommit.attempt), maybeCommit.attempt);
}
//用于产生一个新事务。最多存在_maxTransactionActive个事务同时运行,当前active的事务序号区间处于[_currTransaction,_currTransaction _maxTransactionActive-1]之间。注意只有在当前
//事务结束之后,系统才会初始化新的事务,所以系统中实际活跃的事务可能少于_maxTransactionActive。
if(_active) {
if(_activeTx.size() < _maxTransactionActive) {
Long curr = _currTransaction;
//创建_maxTransactionActive个事务。
for(int i=0; i<_maxTransactionActive; i ) {
//如果事务序号不存在_activeTx中,则创建新事务,并发送$batch流。当ack被调用时,这个序号会被remove掉,详见ack方法。
if(!_activeTx.containsKey(curr) && isReady(curr)) {
// by using a monotonically increasing attempt id, downstream tasks
// can be memory efficient by clearing out state for old attempts
// as soon as they see a higher attempt id for a transaction
Integer attemptId = _attemptIds.get(curr);
if(attemptId==null) {
attemptId = 0;
} else {
attemptId ;
}
//_activeTx记录的是事务序号和事务状态的map,而_activeTx则记录事务序号与尝试次数的map。
_attemptIds.put(curr, attemptId);
for(TransactionalState state: _states) {
state.setData(CURRENT_ATTEMPTS, _attemptIds);
}
//TransactionAttempt包含事务序号和尝试编号2个变量,对应于一个具体的事务。
TransactionAttempt attempt = new TransactionAttempt(curr, attemptId);
_activeTx.put(curr, new TransactionStatus(attempt));
_collector.emit(BATCH_STREAM_ID, new Values(attempt), attempt);
_throttler.markEvent();
}
//如果事务序号已经存在_activeTx中,则curr递增,然后再循环检查下一个。
curr = nextTransactionId(curr);
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
完整代码见最后。
(4)继续往下,看看ack方法。
@Override
public void ack(Object msgId) {
//获取某个事务的状态
TransactionAttempt tx = (TransactionAttempt) msgId;
TransactionStatus status = _activeTx.get(tx.getTransactionId());
if(status!=null && tx.equals(status.attempt)) {
//如果当前状态是PROCESSING,则改为PROCESSED
if(status.status==AttemptStatus.PROCESSING) {
status.status = AttemptStatus.PROCESSED;
} else if(status.status==AttemptStatus.COMMITTING) {
//如果当前状态是COMMITTING,则将事务从_activeTx及_attemptIds去掉,并发送$success流。
_activeTx.remove(tx.getTransactionId());
_attemptIds.remove(tx.getTransactionId());
_collector.emit(SUCCESS_STREAM_ID, new Values(tx));
_currTransaction = nextTransactionId(tx.getTransactionId());
for(TransactionalState state: _states) {
state.setData(CURRENT_TX, _currTransaction);
}
}
//由于有些事务状态已经改变,需要重新调用sync()继续后续处理,或者发送新tuple。
sync();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
(5)还有fail方法和declareOutputFileds方法。
@Override
public void fail(Object msgId) {
TransactionAttempt tx = (TransactionAttempt) msgId;
TransactionStatus stored = _activeTx.remove(tx.getTransactionId());
if(stored!=null && tx.equals(stored.attempt)) {
_activeTx.tailMap(tx.getTransactionId()).clear();
sync();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// in partitioned example, in case an emitter task receives a later transaction than it's emitted so far,
// when it sees the earlier txid it should know to emit nothing
declarer.declareStream(BATCH_STREAM_ID, new Fields("tx"));
declarer.declareStream(COMMIT_STREAM_ID, new Fields("tx"));
declarer.declareStream(SUCCESS_STREAM_ID, new Fields("tx"));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2、TridentSpoutCoordinator
TridentSpoutCoordinator接收来自MasterBatchCoordinator的$success流与$batch流,并通过调用用户代码,实现真正的逻辑。此外还向TridentSpoutExecuter发送$batch流,以触发后者开始真正发送业务数据流。
(1)TridentSpoutCoordinator是一个bolt
public class TridentSpoutCoordinator implements IBasicBolt
- 1
- 2
(2)在创建TridentSpoutCoordinator时,需要传递一个ITridentSpout对象,
public TridentSpoutCoordinator(String id, ITridentSpout spout) {
_spout = spout;
_id = id;
}
- 1
- 2
- 3
- 4
- 5
然后使用这个对象来获取到用户定义的Coordinator:
_coord = _spout.getCoordinator(_id, conf, context);
- 1
- 2
(3)_state和_underlyingState保存了zk中的元数据信息
_underlyingState = TransactionalState.newCoordinatorState(conf, _id);
_state = new RotatingTransactionalState(_underlyingState, META_DIR);
- 1
- 2
- 3
(4)在execute方法中,TridentSpoutCoordinator接收$success流与$batch流,先看看$success流:
if(tuple.getSourceStreamId().equals(MasterBatchCoordinator.SUCCESS_STREAM_ID)) {
_state.cleanupBefore(attempt.getTransactionId());
_coord.success(attempt.getTransactionId());
}
- 1
- 2
- 3
- 4
- 5
即接收到$success流时,调用用户定义的Coordinator中的success方法。同时还清理了zk中的数据。
(5)再看看$batch流
else {
long txid = attempt.getTransactionId();
Object prevMeta = _state.getPreviousState(txid);
Object meta = _coord.initializeTransaction(txid, prevMeta, _state.getState(txid));
_state.overrideState(txid, meta);
collector.emit(MasterBatchCoordinator.BATCH_STREAM_ID, new Values(attempt, meta));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
当收到$batch流流时,初始化一个事务并将其发送出去。由于在trident中消息有可能是重放的,因此需要prevMeta。注意,trident是在bolt中初始化一个事务的。
3、TridentSpoutExecutor
TridentSpoutExecutor接收来自TridentSpoutCoordinator的消息流,包括$commit,$success与$batch流,前面2个分别调用emmitter的commit与success方法,$batch则调用emmitter的emitBatch方法,开始向外发送业务数据。
对于分区类型的spout,有可能是OpaquePartitionedTridentSpoutExecutor等分区类型的executor。
(1) TridentSpoutExecutor与是一个bolt
publicclassTridentSpoutExecutorimplementsITridentBatchBolt
- 1
- 2
(2)核心的execute方法
@Override
public void execute(BatchInfo info, Tuple input) {
// there won't be a BatchInfo for the success stream
TransactionAttempt attempt = (TransactionAttempt) input.getValue(0);
if(input.getSourceStreamId().equals(MasterBatchCoordinator.COMMIT_STREAM_ID)) {
if(attempt.equals(_activeBatches.get(attempt.getTransactionId()))) {
((ICommitterTridentSpout.Emitter) _emitter).commit(attempt);
_activeBatches.remove(attempt.getTransactionId());
} else {
throw new FailedException("Received commit for different transaction attempt");
}
} else if(input.getSourceStreamId().equals(MasterBatchCoordinator.SUCCESS_STREAM_ID)) {
// valid to delete before what's been committed since
// those batches will never be accessed again
_activeBatches.headMap(attempt.getTransactionId()).clear();
_emitter.success(attempt);
} else {
_collector.setBatch(info.batchId);
//发送业务消息
_emitter.emitBatch(attempt, input.getValue(1), _collector);
_activeBatches.put(attempt.getTransactionId(), attempt);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
(一)概述
1、组件的基本关系
(1)trident拓扑最终会转化为一个spout和多个bolt,每个bolt对应一个SubTopologyBolt,它通过TridentBoltExecutor适配成一个bolt。而每个SubTopologyBOlt则由很多节点组成,具体点说这个节点包括(Stream|Node)2部分,注意,Node不是Stream自身的成员变量,而是一个具体的处理节点。Stream定义了哪些数据流,Node定义和如何进行操作,Node包含了一个ProjectedProccessor等处理器,用于定义如何进行数据处理。
(2)一个SubTopologyBOlt包含多个Group,但大多数情况下是一个Group。看TridentTopology#genBoltIds()的代码。在一个SubTopologyBolt中,含有多个节点组是可能的。例如在含有DRPC的Topology中,查询操作也存储操作可以被分配到同一个SubTopologyBolt中。于是该bolt可能收到来自2个节点组的消息。
(3)一个Group有多个Node。符合一定条件的Node会被merge()成一个Group,每个Node表示一个操作。
(4)每个Node与一个Stream一一对应。注意Stream不是指端到端的完整流,而是每一个步骤的处理对象,所有的Stream组合起来才形成完整的流。看Stream的成员变量。
(5)每个Node可能有多个父stream,但多个的情况只在merge()调用multiReduce()时使用。每个Stream与node之间创建一条边。见TridentTopology#addSourceNode()方法。
2、用户视角与源码视角
在用户角度来看,他通过newStream(),each(),filter()待方案对Stream进行操作。而在代码角度,这些操作会被转化为各种Node节点,它些节点组合成一个SubTopologyBolt,然后经过TridentBoltExecutor适配后成为一个bolt。
从用户层面来看TridentTopology,有两个重要的概念一是Stream,另一个是作用于Stream上的各种Operation。在实现层面来看,无论是stream,还是后续的operation都会转变成为各个Node,这些Node之间的关系通过重要的数据结构图来维护。具体到TridentTopology,实现图的各种操作的组件是jgrapht。
说到图,两个基本的概念会闪现出来,一是结点,二是描述结点之间关系的边。要想很好的理解TridentTopology就需要紧盯图中结点和边的变化。
TridentTopology在转换成为普通的StormTopology时,需要将原始的图分成各个group,每个group将运行于一个独立的bolt中。TridentTopology又是如何知道哪些node应该在同一个group,哪些应该处在另一个group中的呢;如何来确定每个group的并发度(parallismHint)的呢。这些问题的解决都与jgrapht分不开。
关于jgrapht的更多信息,请参考其官方网站 http://jgrapht.org
========================================================
在用户看来,所有的操作就是各种各样的数据流与operation的组合,这些组合会被封装成一个Node(即一个Node包含输入流 操作 输出流),符合一定规则的Node会被组合与一个组,组会被放到一个bolt中。
一个blot节点中可能含有多个操作,各个操作间需要进行消息传递
(二)基础类
1、Stream
Stream主要定义了数据流的各种操作,如each(),pproject()等。
(1)成员变量
Node _node;
TridentTopology _topology;
String _name;
- 1
- 2
- 3
- 4
三个成员变量:
* Node对象,这表明Stream与Node是一一对应的,每个节点对应一个Stream对象。
* name:这个Stream的名称,也等于是这这个Node的名称。
* TridentTopology: 这个Stram所属的拓扑,使用这个变量,可以调用addSourceNode()等方法。
其中_node变量被使用很少。
(2)projectionValidation()
这个方法用于检查是否对一个不存在的field进行了操作。
private void projectionValidation(Fields projFields) {
if (projFields == null) {
return;
}
Fields allFields = this.getOutputFields();
for (String field : projFields) {
if (!allFields.contains(field)) {
throw new IllegalArgumentException("Trying to select non-existent field: '" field "' from stream containing fields fields: <" allFields ">");
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
stream中定义了定义了各种各样的trident操作,下面分别介绍
(3)project()
public Stream project(Fields keepFields) {
projectionValidation(keepFields);
return _topology.addSourcedNode(this, new ProcessorNode(_topology.getUniqueStreamId(), _name, keepFields, new Fields(), new ProjectedProcessor(keepFields)));
}
- 1
- 2
- 3
- 4
- 5
首先检查一下需要project的field是否存在。然后就在TridentTopology中新增一个节点。
第一个参数就是Stream自身,第二个参数是一个Node的子类–ProcessorNode。创建ProcessorNode时,最后一个参数ProjectedProcessor用于指定如何对流进行操作。
addSourcedNode把source和node同时添加进一个拓扑,即一个流与一个节点。注意这里的节点不是source这个Stream自身的成员变量_node,而是一个新建的节点,比如在project()方法中的节点就是一个使用ProjectedProcessor创建的ProcessorNode。
2、Node SpoutNode PartitionNode ProcessorNode
(1)Node表示拓扑中的一个节点,后面3个均是其子类。事实上拓扑中的节点均用于产生数据或者对数据进行处理。一个拓扑有多个spout/bolt,每个spout/bolt有一个或者多个Group,我个Group有多个Node。
详细分析见书。
3、Group
节点组是构建SubTopologyBolt的基础,也是Topology中执行优化的基本操作单元,Trident会通过不断的合并节点组来达到最优处理的目的。Group中包含了一组连通的节点。
(1)成员变量
public final Set<Node> nodes = new HashSet<>();
private final DirectedGraph<Node, IndexedEdge> graph;
private final String id = UUID.randomUUID().toString();
- 1
- 2
- 3
- 4
nodes表示节点组中含有的节点。
graph表示拓扑的有向图。(是整个拓扑的构成的图)
id用于唯一标识一个group。
(2)构造方法
public Group(DirectedGraph graph, List<Node> nodes) {
this.graph = graph;
this.nodes.addAll(nodes);
}
- 1
- 2
- 3
- 4
- 5
初始状态时,每个Group只有一个Node.
public Group(DirectedGraph graph, Node n) {
this(graph, Arrays.asList(n));
}
- 1
- 2
- 3
- 4
将2个Group合成一个新的Group。
public Group(Group g1, Group g2) {
this.graph = g1.graph;
nodes.addAll(g1.nodes);
nodes.addAll(g2.nodes);
}
- 1
- 2
- 3
- 4
- 5
- 6
(3)outgoingNodes()
通过遍历组中节点的方式来获取该节点组所有节点的子节点,这些子节点可能属于该节点组,也可能属于其它节点组。
public Set<Node> outgoingNodes() {
Set<Node> ret = new HashSet<>();
for(Node n: nodes) {
ret.addAll(TridentUtils.getChildren(graph, n));
}
return ret;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
(4)incommingNodes()
用于获取该节点组中所有节点的父节点,这些父节点可能属于该节点组,也可能属于其它节点组。
4、GraphGrouper
GraphGrouper提供了对节点组进行操作及合并的基本方法。
(1)成员变量
final DirectedGraph<Node, IndexedEdge> graph;
final Set<Group> currGroups;
final Map<Node, Group> groupIndex = new HashMap<>();
- 1
- 2
- 3
- 4
graph:与Group相同,即这个拓扑的整个图。
currGroups:当前graph对应的节点组。节点组之间是没有交集的。
groupIndex:是一个反向索引,用于快速查询每个节点所在的节点组。
(2)构造方法
public GraphGrouper(DirectedGraph<Node, IndexedEdge> graph, Collection<Group> initialGroups) {
this.graph = graph;
this.currGroups = new LinkedHashSet<>(initialGroups);
reindex();
}
- 1
- 2
- 3
- 4
- 5
- 6
就是为上面几个变量进行初始化。
(3)reindex()
public void reindex() {
groupIndex.clear();
for(Group g: currGroups) {
for(Node n: g.nodes) {
groupIndex.put(n, g);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
根据currGroups的内容重构groupIndex。
(4)nodeGroup()
public Group nodeGroup(Node n) {
return groupIndex.get(n);
}
- 1
- 2
- 3
- 4
查询某个node属于哪个group。
(5)outgoingGroups()
计算节点组与哪些节点组之间存在有向边,即2个节点组是相连的。其基本算法是遍历每一个节点的子节点,若该子节点所在的节点组与自身不同,则获得子节点所在的节点组。
public Collection<Group> outgoingGroups(Group g) {
Set<Group> ret = new HashSet<>();
for(Node n: g.outgoingNodes()) {
Group other = nodeGroup(n);
if(other==null || !other.equals(g)) {
ret.add(other);
}
}
return ret;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(6)incomingGroups()
用于获取该节点组的父节点组,算法与上面类似。
public Collection<Group> incomingGroups(Group g) {
Set<Group> ret = new HashSet<>();
for(Node n: g.incomingNodes()) {
Group other = nodeGroup(n);
if(other==null || !other.equals(g)) {
ret.add(other);
}
}
return ret;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(7)merge()
合并2个节点组。
private void merge(Group g1, Group g2) {
Group newGroup = new Group(g1, g2);
currGroups.remove(g1);
currGroups.remove(g2);
currGroups.add(newGroup);
for(Node n: newGroup.nodes) {
groupIndex.put(n, newGroup);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(8)mergeFully
这个方法是GraphGrouper的核心算法,它用来计算何时可以对2个节点组进行合并。基本思想是:如果一个节点组只有一个父节点组,那么将这个节点组与父节点组合并;如果一个节点组只有一个子节点组,那么将子节点组与自身节点组合并。反复进行这个过程。
public void mergeFully() {
boolean somethingHappened = true;
while(somethingHappened) {
somethingHappened = false;
for(Group g: currGroups) {
Collection<Group> outgoingGroups = outgoingGroups(g);
if(outgoingGroups.size()==1) {
Group out = outgoingGroups.iterator().next();
if(out!=null) {
merge(g, out);
somethingHappened = true;
break;
}
}
Collection<Group> incomingGroups = incomingGroups(g);
if(incomingGroups.size()==1) {
Group in = incomingGroups.iterator().next();
if(in!=null) {
merge(g, in);
somethingHappened = true;
break;
}
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
(一)参考内容
http://www.cnblogs.com/hseagle/p/3490635.html
TridentTopology是storm提供的高层使用接口,常见的一些SQL中的操作tridenttopology提供的api中都有类似的影射。
从TridentTopology到vanilla topology(普通的topology)由三个层次组
成:
1. 面向最终用户的概念stream, operation
2. 利用planner将tridenttopology转换成vanilla topology
3. 执行vanilla topology
从TridentTopology到基本的Topology有三层,下图是一个全局视图。
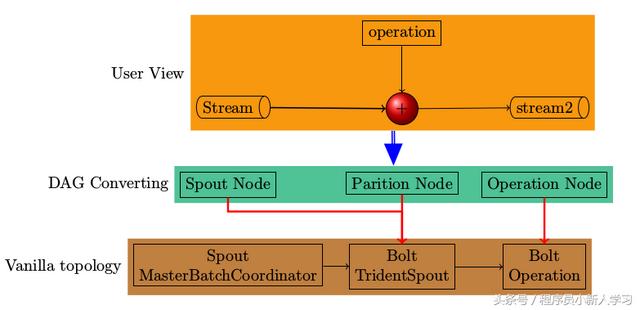
从用户层面来看TridentTopology,有两个重要的概念一是Stream,另一个是作用于Stream上的各种Operation。在实现层面来看,无论是stream,还是后续的operation都会转变成为各个Node,这些Node之间的关系通过重要的数据结构图来维护。具体到TridentTopology,实现图的各种操作的组件是jgrapht。
说到图,两个基本的概念会闪现出来,一是结点,二是描述结点之间关系的边。要想很好的理解TridentTopology就需要紧盯图中结点和边的变化。
TridentTopology在转换成为普通的StormTopology时,需要将原始的图分成各个group,每个group将运行于一个独立的bolt中。TridentTopology又是如何知道哪些node应该在同一个group,哪些应该处在另一个group中的呢;如何来确定每个group的并发度(parallismHint)的呢。这些问题的解决都与jgrapht分不开。
关于jgrapht的更多信息,请参考其官方网站 http://jgrapht.org
========================================================
在用户看来,所有的操作就是各种各样的数据流与operation的组合,这些组合会被封装成一个Node(即一个Node包含输入流 操作 输出流),符合一定规则的Node会被组合与一个组,组会被放到一个bolt中。
一个blot节点中可能含有多个操作,各个操作间需要进行消息传递。
=====================================
1、【待完善】通过上面的分析,一个Spout是准备好了,但如何将它加载到拓扑中,并开始真正的数据流:
(1)在TridentTopology中调用newStream方法,将spout节点加入拓扑。
(2)在TridentTopologyBuilder的buildTopololg方法中设置了topo的相关信息
2、拓扑创建的总体流程
(1)在用户代码中创建TridentTopology对象
TridentTopology topology = new TridentTopology();
- 1
- 2
(2)在用户代码中指定spout节点和bolt节点
比如:
topology.newStream("spout1", spout)
.parallelismHint(16)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count")).parallelismHint(16);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(3)在用户代码中创建拓扑
topology.build();
- 1
- 2
(4)topology.build()会调用TridentTopologyBuilder#buildTopology()
(5)用户代码中提交拓扑
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, buildTopology(null));
- 1
- 2
(一)概述
(二)基础类
1、GlobalStreamId
这是由trift生成的类,有2个核心成员变量
public GlobalStreamId(
String componentId,
String streamId)
- 1
- 2
- 3
- 4
分别记录了某个component的ID与其对应的streamId,如
"$mastercoord-" batchGroup MasterBatchCoordinator.BATCH_STREAM_ID
- 1
- 2
表示这个component会消费这个stream的消息。
(三)TridentTopology
主要流程:
(1)创建各种各样的节点,包括spout/bolt
(2)spout全部放到一个set中
(3)bolt的每一个节点放入一个group中
(4)对group进行各种的merge操作(如g1的所有输出均到g2,则将它们合并)
(5)直到剩余少量的mergeGroup,作为bolt
(6)TridentTopologyBuilder.buildTopology()对这些spout/mergeGroup进行分组配置。
1、生成bolt的名称:genBoltIds
genBoltIds用于为bolt生成一个唯一的id,它使用字母b开头,然后是一个数字id,接着是group的名称,然后是第2个id, 第2个group的名称….。而group的名称是由这个group包含的Node名称组成的。
private static Map<Group, String> genBoltIds(Collection<Group> groups) {
Map<Group, String> ret = new HashMap<>();
int ctr = 0;
for(Group g: groups) {
if(!isSpoutGroup(g)) {
List<String> name = new ArrayList<>();
name.add("b");
name.add("" ctr);
String groupName = getGroupName(g);
if(groupName!=null && !groupName.isEmpty()) {
name.add(getGroupName(g));
}
ret.put(g, Utils.join(name, "-"));
ctr ;
}
}
return ret;
}
private static String getGroupName(Group g) {
TreeMap<Integer, String> sortedNames = new TreeMap<>();
for(Node n: g.nodes) {
if(n.name!=null) {
sortedNames.put(n.creationIndex, n.name);
}
}
List<String> names = new ArrayList<>();
String prevName = null;
for(String n: sortedNames.values()) {
if(prevName==null || !n.equals(prevName)) {
prevName = n;
names.add(n);
}
}
return Utils.join(names, "-");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
2、添加节点:addNode()
protected Stream addNode(Node n) {
registerNode(n);
return new Stream(this, n.name, n);
}
- 1
- 2
- 3
- 4
- 5
这个方法很简单,而且,它只在newStream()及newDRPCStream中调用,很明显这是用于提供一个新的数据源的。而下面的addSourceNode()是用于在bolt中添加下一个处理节点的。
3、添加节点:addSourceNode()
创建一个新节点,指定新节点的父节点(可能多个)。指定多个sources的情况只在merge()方法中被调用multiReduce()时调用。因此这里只关注一个source的情形。
protected Stream addSourcedNode(Stream source, Node newNode) {
return addSourcedNode(Arrays.asList(source), newNode);
}
protected Stream addSourcedNode(List<Stream> sources, Node newNode) {
registerSourcedNode(sources, newNode);
return new Stream(this, newNode.name, newNode);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
addSourcedNode把source和node同时添加进一个拓扑,即一个流与一个节点。注意这里的节点不是source这个Stream自身的成员变量_node,而是一个新建的节点,比如在project()方法中的节点就是一个使用ProjectedProcessor创建的ProcessorNode。
return _topology.addSourcedNode(this, new ProcessorNode(_topology.getUniqueStreamId(), _name, keepFields, new Fields(), new ProjectedProcessor(keepFields)));
- 1
- 2
除了注册新节点 registerNode(newNode)以外,还在每个stream和节点间创建一条边。
protected void registerSourcedNode(List<Stream> sources, Node newNode) {
registerNode(newNode);
int streamIndex = 0;
for(Stream s: sources) {
_graph.addEdge(s._node, newNode, new IndexedEdge(s._node, newNode, streamIndex));
streamIndex ;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
向图中添加一个节点。然后若节点中的stateInfo成员不为空,则将该节点放入与存储序号(StateId)相对应的哈希表_colocate中。_colocate变量将所有访问同一存储的节点关联在一起,并将他们放在一个Bolt中执行。
protected void registerNode(Node n) {
_graph.addVertex(n);
if(n.stateInfo!=null) {
String id = n.stateInfo.id;
if(!_colocate.containsKey(id)) {
_colocate.put(id, new ArrayList());
}
_colocate.get(id).add(n);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






