万字长文概述NLP中的深度学习技术之卷积神经网络(万字长文概述NLP中的深度学习技术之卷积神经网络)
随着词嵌入的流行及其在分布式空间中展现出的强大表征能力,我们需要一种高效的特征函数,以从词序列或 n-grams 中抽取高级语义信息。随后这些抽象的语义信息能用于许多 NLP 任务,如情感分析、自动摘要、机器翻译和问答系统等。卷积神经网络(CNN)因为其在计算机视觉中的有效性而被引入到自然语言处理中,实践证明它也非常适合序列建模。

图 5:用于执行词级分类预测的 CNN 框架。(Collobert and Weston (2008))
使用 CNN 进行句子建模可以追溯到 Collobert 和 Weston (2008) 的研究,他们使用多任务学习为不同的 NLP 任务输出多个预测,如词性标注、语块分割、命名实体标签和语义相似词等。其中查找表可以将每一个词转换为一个用户自定义维度的向量。因此通过查找表,n 个词的输入序列 {s_1,s_2,... s_n } 能转换为一系列词向量 {w_s1, w_s2,... w_sn},这就是图 5 所示的输入。
这可以被认为是简单的词嵌入方法,其中权重都是通过网络来学习的。在 Collobert 2011 年的研究中,他扩展了以前的研究,并提出了一种基于 CNN 的通用框架来解决大量 NLP 任务,这两个工作都令 NLP 研究者尝试在各种任务中普及 CNN 架构。
CNN 具有从输入句子抽取 n-gram 特征的能力,因此它能为下游任务提供具有句子层面信息的隐藏语义表征。下面简单描述了一个基于 CNN 的句子建模网络到底是如何处理的。
基础 CNN1. 序列建模
对于每一个句子,w_i∈R^d 表示句子中第 i 个词的词嵌入向量,其中 d 表示词嵌入的维度。给定有 n 个词的句子,句子能表示为词嵌入矩阵 W∈R^n×d。下图展示了将这样一个句子作为输入馈送到 CNN 架构中。

图 6:使用 CNN 的文本建模(Zhang and Wallace , 2015)。
若令 w_i:i j 表示 w_i, w_i 1,...w_j 向量的拼接,那么卷积就可以直接在这个词嵌入输入层做运算。卷积包含 d 个通道的卷积核 k∈R^hd,它可以应用到窗口为 h 个词的序列上,并生成新的特征。例如,c_i 即使用卷积核在词嵌入矩阵上得到的激活结果:

若 b 是偏置项,f 是非线性激活函数,例如双曲正切函数。使用相同的权重将滤波器 k 应用于所有可能的窗口,以创建特征图。
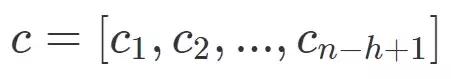
在卷积神经网络中,大量不同宽度的卷积滤波器(也叫做内核,通常有几百个)在整个词嵌入矩阵上滑动。每个内核提取一个特定的 n-gram 模式。卷积层之后通常是最大池化策略 c^=max{c},该策略通过对每个滤波器应用最大运算来对输入进行二次采样。使用这个策略有两大原因。
首先,最大池化提供固定长度的输出,这是分类所需的。因此,不管滤波器的大小如何,最大池化总是将输入映射到输出的固定维度上。其次,它在降低输出维度的同时保持了整个句子中最显著的 n-gram 特征。这是通过平移不变的方式实现的,每个滤波器都能从句子的任何地方提取特定的特征(如,否定),并加到句子的最终表示中。
词嵌入可以随机初始化,也可以在大型未标记语料库上进行预训练。第二种方法有时对性能提高更有利,特别是当标记数据有限时。卷积层和最大池化的这种组合通常被堆叠起来,以构建深度 CNN 网络。这些顺序卷积有助于改进句子的挖掘,以获得包含丰富语义信息的真正抽象表征。内核通过更深的卷积覆盖了句子的大部分,直到完全覆盖并创建了句子特征的总体概括。
2. 窗口方法
上述架构将完整句子建模为句子表征。然而,许多 NLP 任务(如命名实体识别,词性标注和语义角色标注)需要基于字的预测。为了使 CNN 适应这样的任务,需要使用窗口方法,其假定单词的标签主要取决于其相邻单词。因此,对于每个单词,存在固定大小的窗口,窗口内的子句都在处理的范围内。如前所述,独立的 CNN 应用于该子句,并且预测结果归因于窗口中心的单词。按照这个方法,Poira 等人(2016)采用多级深度 CNN 来标记句子中的每个单词为 aspect 或 non-aspect。结合一些语言模式,它们的集成分类器在 aspect 检测方面表现很好。
词级分类的最终目的通常是为整个句子分配一系列的标签。在这样的情况下,有时会采用结构化预测技术来更好地捕获相邻分类标签间的关系,最终生成连贯标签序列,从而给整个句子提供最大分数。
为了获得更大的上下文范围,经典窗口方法通常与时延神经网络(TDNN)相结合。这种方法中,可以在整个序列的所有窗口上进行卷积。通过定义特定宽度的内核,卷积通常会受到约束。因此,相较于经典窗口方法(只考虑要标记单词周围窗口中的单词),TDNN 会同时考虑句子中的所有单词窗口。TDNN 有时也能像 CNN 架构一样堆叠,以提取较低层的局部特征和较高层的总体特征。
应用
在这部分,研究者介绍了一些使用 CNN 来处理 NLP 任务的研究,这些研究在它们当时所处时代属于前沿。
Kim 探讨了使用上述架构进行各种句子分类任务,包括情感、主观性和问题类型分类,结果很有竞争力。因其简单有效的特点,这种方法很快被研究者接受。在针对特定任务进行训练之后,随机初始化的卷积内核成为特定 n-gram 的特征检测器,这些检测器对于目标任务非常有用。但是这个网络有很多缺点,最主要的一点是 CNN 没有办法构建长距离依存关系。

图 7:4 种预训练 7-gram 内核得到的最好核函数;每个内核针对一种特定 7-gram。
Kalchbrenner 等人的研究在一定程度上解决了上述问题。他们发表了一篇著名的论文,提出了一种用于句子语义建模的动态卷积神经网络(DCNN)。他们提出了动态 k-max 池化策略,即给定一个序列 p,选择 k 种最有效的特征。选择时保留特征的顺序,但对其特定位置不敏感。在 TDNN 的基础上,他们增加了动态 k-max 池化策略来创建句子模型。这种结合使得具有较小宽度的滤波器能跨越输入句子的长范围,从而在整个句子中积累重要信息。在下图中,高阶特征具有高度可变的范围,可能是较短且集中,或者整体的,和输入句子一样长。他们将模型应用到多种任务中,包括情感预测和问题类型分类等,取得了显著的成果。总的来说,这项工作在尝试为上下文语义建模的同时,对单个内核的范围进行了注释,并提出了一种扩展其范围的方法。
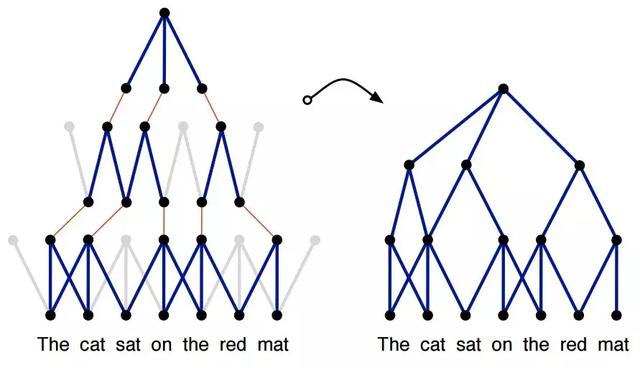
图 8:DCNN 子图,通过动态池化,较高层级上的宽度较小滤波器也能建立输入句子中的长距离相关性。
情感分类等任务还需要有效地抽取 aspect 与其情感极性(Mukherjee and Liu, 2012)。Ruder 等人(2016)还将 CNN 应用到了这类任务,他们将 aspect 向量与词嵌入向量拼接以作为输入,并获得了很好的效果。CNN 建模的方法一般因文本的长短而异,在较长文本上的效果比较短文本上好。Wang et al. (2015) 提出利用 CNN 建模短文本的表示,但是因为缺少可用的上下文信息,他们需要额外的工作来创建有意义的表征。因此作者提出了语义聚类,其引入了多尺度语义单元以作为短文本的外部知识。最后 CNN 组合这些单元以形成整体表示。
CNN 还广泛用于其它任务,例如 Denil et al. (2014) 利用 DCNN 将构成句子的单词含义映射到文本摘要中。其中 DCNN 同时在句子级别和文档级别学习卷积核,这些卷积核会分层学习并捕获不同水平的特征,因此 DCNN 最后能将底层的词汇特征组合为高级语义概念。
此外,CNN 也适用于需要语义匹配的 NLP 任务。例如我们可以利用 CNN 将查询与文档映射到固定维度的语义空间,并根据余弦相似性对与特定查询相关的文档进行排序。在 QA 领域,CNN 也能度量问题和实体之间的语义相似性,并借此搜索与问题相关的回答。机器翻译等任务需要使用序列信息和长期依赖关系,因此从结构上来说,这种任务不太适合 CNN。但是因为 CNN 的高效计算,还是有很多研究者尝试使用 CNN 解决机器翻译问题。
总体而言,CNN 在上下文窗口中挖掘语义信息非常有效,然而它们是一种需要大量数据训练大量参数的模型。因此在数据量不够的情况下,CNN 的效果会显著降低。CNN 另一个长期存在的问题是它们无法对长距离上下文信息进行建模并保留序列信息,其它如递归神经网络等在这方面有更好的表现。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






