中文 开源 语音识别 模型(开源语音识别模型)
出品|开源中国
拥有 GTP-3 语言模型,并为 GitHub Copilot 提供技术支持的人工智能公司 OpenAI 近日开源了 Whisper 自动语音识别系统,Open AI 强调 Whisper 的语音识别能力已达到人类水准。

Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。OpenAI 开放模型和推理代码,希望开发者可以将 Whisper 作为建立有用的应用程序和进一步研究语音处理技术的基础。
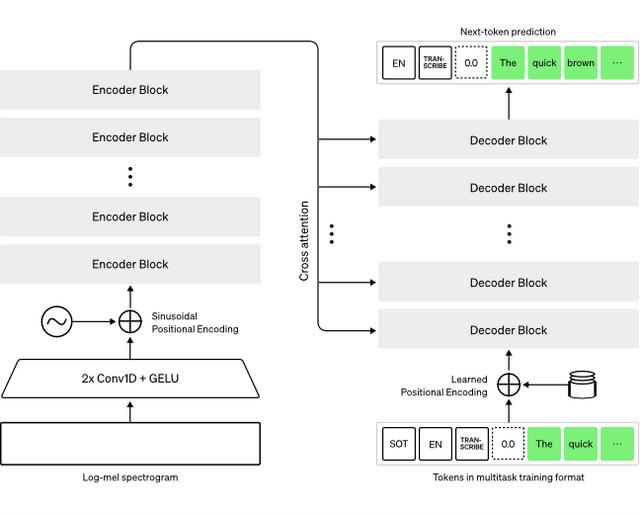
Whisper 执行操作的大致过程:
输入的音频被分割成 30 秒的小段、转换为 log-Mel 频谱图,然后传递到编码器。解码器经过训练以预测相应的文字说明,并与特殊的标记进行混合,这些标记指导单一模型执行诸如语言识别、短语级别的时间戳、多语言语音转录和语音翻译等任务。
相比目前市面上的其他现有方法,它们通常使用较小的、更紧密配对的「音频 - 文本」训练数据集,或使用广泛但无监督的音频预训练集。因为 Whisper 是在一个大型和多样化的数据集上训练的,而没有针对任何特定的数据集进行微调,虽然它没有击败专攻 LibriSpeech 性能的模型(著名的语音识别基准测试),然而在许多不同的数据集上测量 Whisper 的 Zero-shot(不需要对新数据集重新训练,就能得到很好的结果)性能时,研究人员发现它比那些模型要稳健得多,犯的错误要少 50%。
目前 Whisper 有 9 种模型(分为纯英文和多语言),其中四种只有英文版本,开发者可以根据需求在速度和准确性之间进行权衡,以下是现有模型的大小,及其内存要求和相对速度:
OpenAI 希望 Whisper 的高准确性和易用性可以让开发者在更广泛的应用中加入语音识别功能,尤其是用来协助改善无障碍工具。
,


免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






