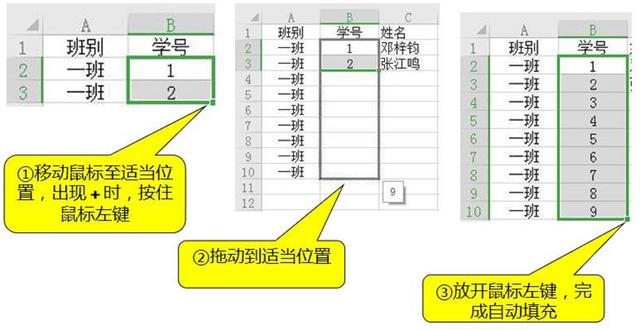
r语言读取表格数据做直方图(R语言数据可视化系列)
散点图矩阵可以非常直观地看到多个变量两两间的相关性,是变量间相关性分析的一把利器。
基本散点图矩阵-
pairs( ),绘制基本散点图矩阵
-
~mpg disp drat wt,表示所有需要绘制散点图矩阵的变量
-
在行和列的交叉处为两个变量之间的散点图,上方的图形和下方的图形对称,加入参数upper.panel=NULL可设置只显示下半部分
#查看头几行数据 head(mtcars) pairs(~mpg disp drat wt,data=mtcars,main="基本散点图矩阵")
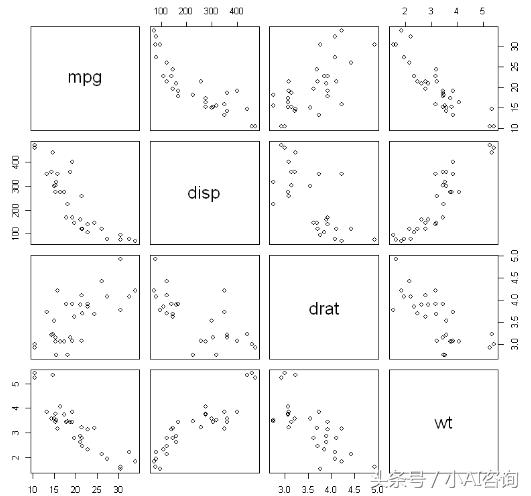
基本散点图矩阵
散点图拟合矩阵(推荐)-
scatterplotMatrix( ),推荐使用,绘制带有拟合曲线的散点图矩阵
-
散点图上添加了线性拟合和平滑拟合线(绿线和红线)
-
对角线上显示了每个变量的核密度估计图和轴须图
-
spread=FALSE,表示不添加展示分散度和对称信息的直线
-
lty=2,设置线性拟合(绿线)线的形状为type“2”,也就是虚线
library(car) scatterplotMatrix(~mpg disp drat wt,data=mtcars,spread=FALSE,lty=2,main="利用car包绘制散点图矩阵")

~mpg disp drat wt|cyl,不同发动机缸数cyl下的散点图
diagonal="histogram",设置对角线上的图形为变量的直方图
○代表4缸发动机,△代表6缸发动机,﹢代表8缸发动机
scatterplotMatrix(~mpg disp drat wt|cyl,data=mtcars,spread=FALSE,lty=2,diagonal="histogram",main="不同发动机缸数下的散点图矩阵")

不同类别下的散点图拟合矩阵
带颜色的排序散点图矩阵-
cpairs(),画图函数
-
cor( ),计算变量的相关系数矩阵
-
变量离主对角线越近相关性越高
-
优点:当变量数目比较多时,利用这个图一眼就能找到与我们所关注的变量最相关的变量
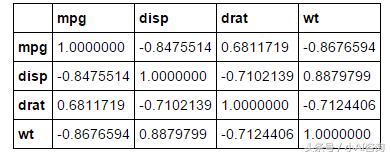
cor(mtcars[,c('mpg','disp','drat','wt')])
相关系数矩阵
library(gclus) data=mtcars[,c(1,3,5,6)] data.cor=abs(cor(data)) colors=dmat.color(data.cor) #生成颜色矩阵 order=order.single(data.cor) #用来排序 cpairs(data,order,panel.colors=colors,gap=0.5,main="带颜色的排序散点图矩阵") #gap=0.5,增加两个图形之间的间距
带颜色的排序散点图矩阵
从图中可以看出,相关性最高的是车重wt和排量disp以及车重wt和每加仑英里数mpg(标了红色,而且离主对角线近)。相关性最低的是后轴比drat和每加仑英里数mpg(标了黄色,且离主对角线较远)。
,

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com