pdf不可编辑怎么提取表格(汇总100个格式错乱的PDF表格)
汇总100个表头顺序不同的PDF表格。职场中遇到这样的问题会让很多人感到头皮发麻,即使是 “职场老鸟”也不例外。很多人都能想到的方法就是利用付费软件将PDF一个一个的转换为excel,然后再汇总但是它们的表头顺序是不同的只能一个一个表格的调整顺序再复制粘贴,有一个粉丝表示需要汇总100个这样的文件,已经做了1天了还没搞定,有没有什么快速的方法呢?其实我们不必舍近求远,利用Excel中的power query这个功能只需要几分钟就能轻松解决这样的。操作也并不难,只需利用2个M函数就能轻松搞定,下面就让我们来一起操作下吧!

1. PDF.Tables:获取Pdf中的表格数据
语法:=Pdf.Tables(pdf as binary) as table
这个M函数的可选参数非常多,我们可以不做设置,它的必须参数是:pdf as binary意思就说:pdf文件必须要转换为binary(二进制文件)才能放在第一参数中。as table是说函数返回的类型是表格
2. Table.PromoteHeaders:将第一行用作标题
语法:= Table.PromoteHeaders(table as table) as table
table as table它的意思是说这个函数的参数必须是一个table格式的数据,as table是说函数返回的类型是表格
对于这类的函数可能大家都比较陌生感觉看不懂。今天的操作其实非常的简单,这两个函数我们都是仅仅为其添加了一个参数,下面我们就来着手汇总下PDF
二、汇总PDF1.获取数据
首先我们需要将想要汇总的pdf文件都放在一个文件夹中,然后新建一个Excel点击【数据】功能组,在左侧找到【获取数据】→【来自文件】→【从文件夹】。跳出一个文件选择的窗口后我们找到存放PDF的文件夹然后点击打开,power query就会加载获取数据,获取数据后会跳出界面,我们直接点击【转换数据】就会进入power query的编辑界面

2.整理数据
进入PQ后我们仅仅保留前两列数据,将其余的数据都删掉。Name这一列是pdf文件的名称,Content这一列是每个pdf对应的二进制文件。然后将name这一列放在最前面,紧接着我们【转换】找到【替换值】将后缀名.pdf替换掉。最后将name更改为文件名

3.获取PDF中的表格
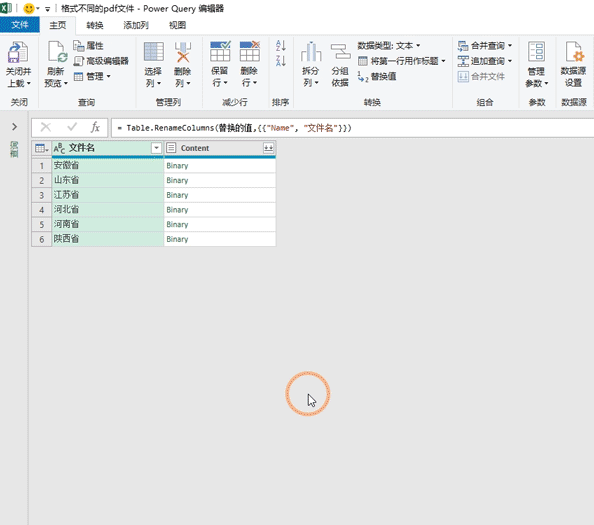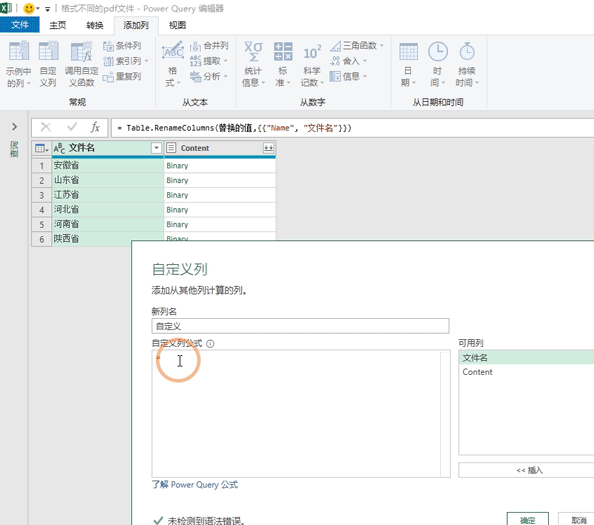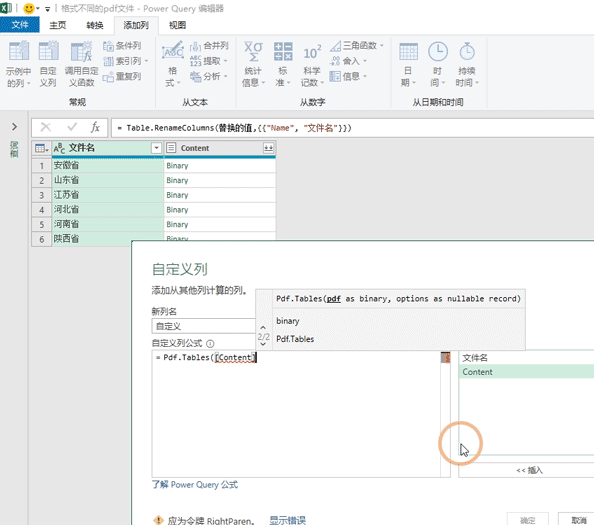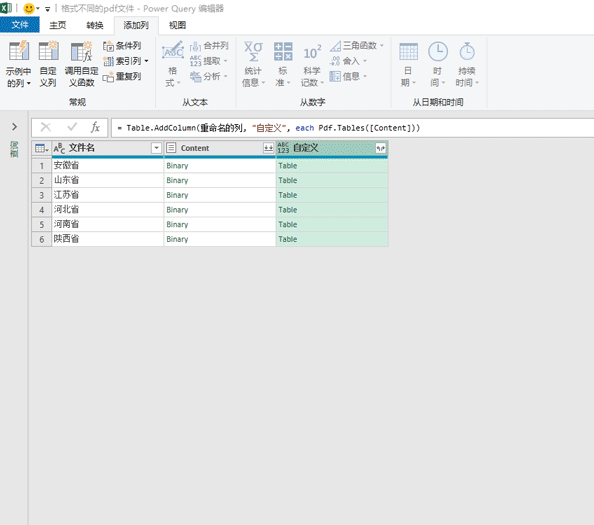
上一步PQ已经将pdf文件转换为了binary,我们就可以使用Pdf.Tables来获取pdf文件中的表格了。需要点击【添加列】找到【自定义列】就会跳出添加自定义列的界面,随后我们在自定义公式这个输入:Pdf.Tables([Content])然后点击确定,这样的话就会多出一列自定义列,并且数据都是table
随后我们点击自定义右上角的左右箭头来展开数据,在这里我们仅仅选择kind和date这两类数据,再把使用原始列明作为前缀的对勾去掉点击确定即可,这样的话在一个pdf文件就会对应2个kind分别是page和table,这两个类型中的数据是一模一样的我们只需要任选一个作为数据即可,在这里我们选择table为数据,可以在kind字段中筛选table然后点击确定即可,随后我们就可以将kind和content这两个字段都删掉了,在这里data字段中的table对应的就是每个pdf文件中的表格,我们可以点击看一下

4.提升标题
现在我们虽然获取了pdf中的表格,但是它的标题是默认的,想要达到自动匹配表头的效果,我们就必须要将表格中的标题放在PQ中标题的位置,这个时候我们就需要用到Table.PromoteHeaders这个函数,也是添加一个自定义列,然后将公式设置为:=Table.PromoteHeaders([Data])然后将data这一列数据删除掉,我们点击table可以看下表格中的标题已经放在标题行了

5.展开数据
随后我们还是点击下自定义右上角的左右箭头来展开数据,选择全部字段不要勾选使用原始列名,然后点击确定,这样的话就汇总完毕了,最后只需要点击【主页】找到【关闭并上载】将数加载回excel即可
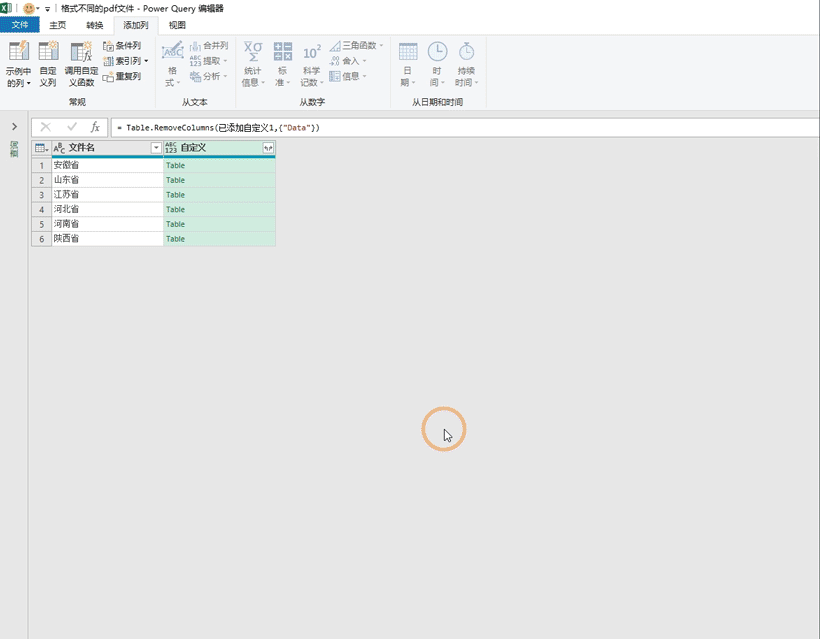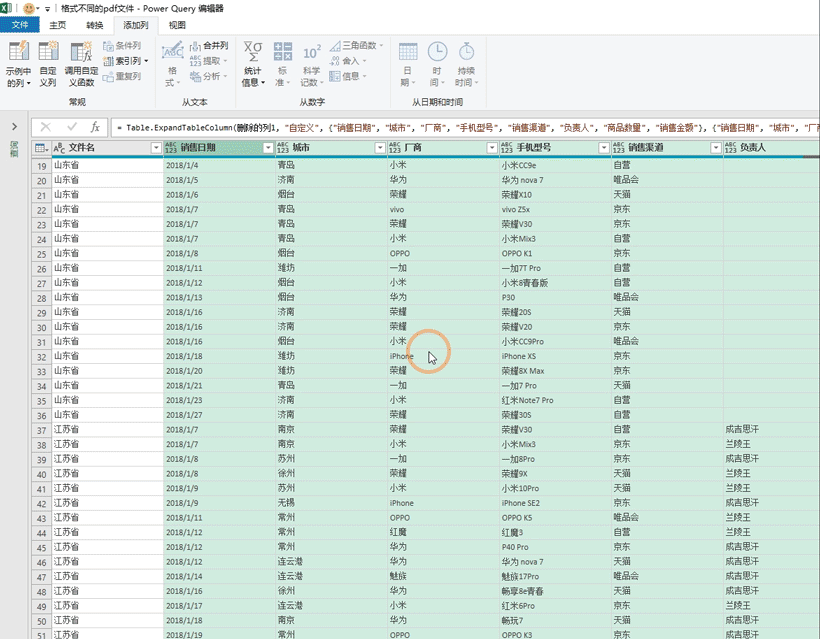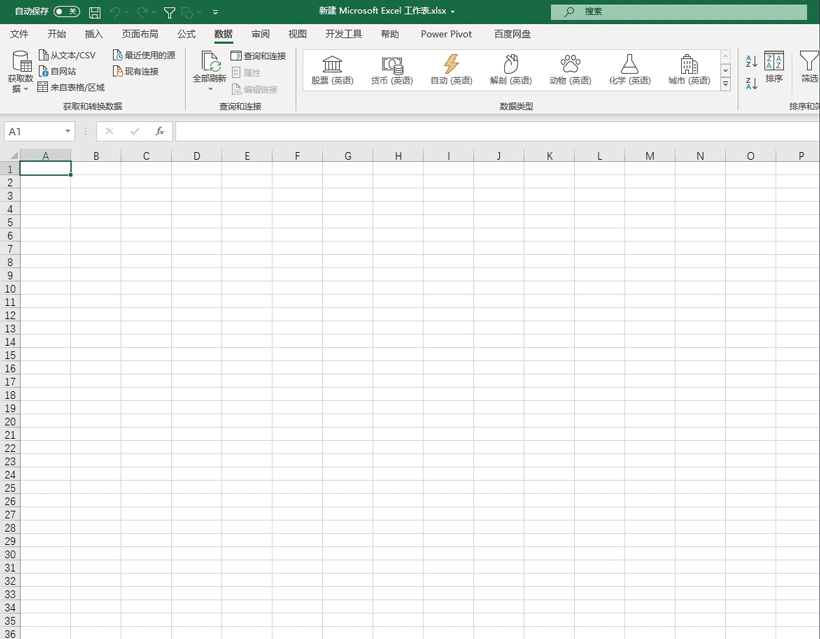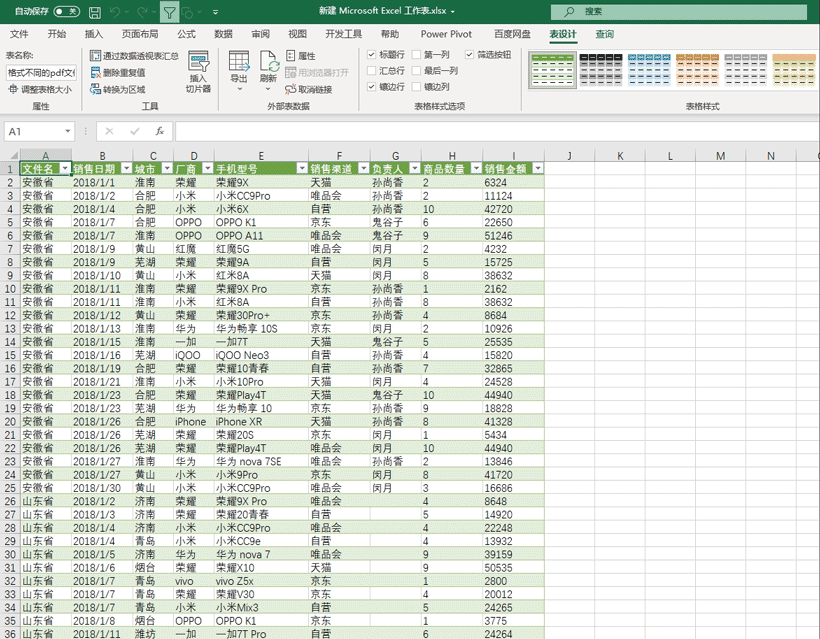
使用这个方法当我们向文件夹中放置新的pdf表格文件,只需要回到汇总的Excel表格中,点击鼠标右键选择刷新,新放置的pdf文件就能自动刷新进来,非常的方便
以上就是今天分享的全部内容,你学会了吗?
我是Excel从零到一,关注我,持续分享更多Excel技巧
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






