把pdf转换成网页版(这个工具真好用)
前两天有个客户需要把网页转为pdf,之前也没开发过类似的工具,就在百度搜索了一波,主要有下面三种
- 在线转pdf
- 使用浏览器打印功能转pdf
- 使用本地软件工具转pdf
在线转pdf
在百度(我一般用必应)搜索“在线网页转pdf”就有很多可以做这个事的网站,免费的如
- PDF24Tools
各种pdf的操作都有,免费使用,速度一般。
官网地址https://tools.pdf24.org/zh

PDF24 Tools
- doctron
开源免费项目,使用golang写的,提供在线转
官网地址http://doctron.lampnick.com/
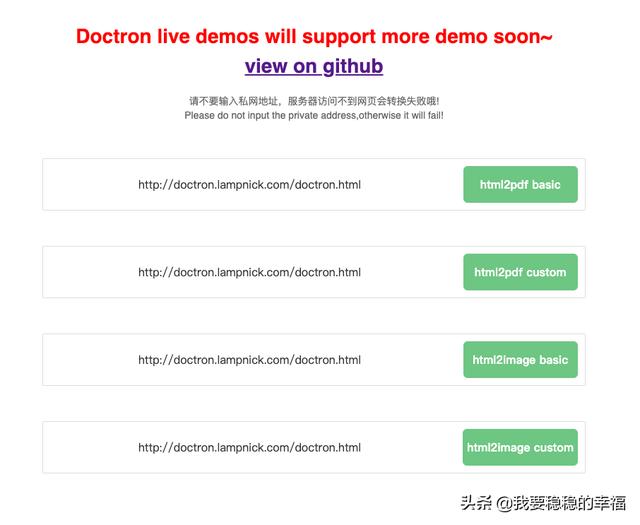
doctron在线体验demo
还有挺多其他的,可以自己搜索,但是都不符合我的预期。
使用浏览器打印功能转pdf- 在浏览器右键,点击打印或者ctrl p
- 在弹出的打印对话框中找到目标打印机选择“另存为PDF”
- 点击“保存”按钮即可下载pdf了
Doctron,这是我今天要介绍的重头戏。
Doctron是基于docker、无状态、简单、快速、高质量的文档转换服务。目前支持将html转为pdf、图片(使用chrome(Chromium)浏览器内核,保证转换质量)。支持PDF添加水印。
- 使用chrome内核保证高质量将HTML转为pdf/图片。
- 简易部署(提供docker镜像,DockerFile以及k8s yaml配置文件)。支持丰富的转换参数。转为pdf和图片支持自定义大小。
- 无状态服务支持。
管他的,先把代码下载下来再说
git clone https://gitcode.net/mirrors/lampnick/doctron.git

仓库
运行
go build
./doctron --config conf/default.yaml

运行截图
转pdf,访问http://127.0.0.1:8080/convert/html2pdf?u=doctron&p=lampnick&url=<url>,更换链接中的url为你需要转换的url即可。

转换效果
然后就可以写程序去批量转换需要的网页了,但是我需要转换的网页有两个需求
1、网站需要会员登录,不然只能看得到一部分
2、需要把网站的头和尾去掉的
这就为难我了,不会go语言啊,硬着头皮搞了,肯定有个地方打开这个url的,就去代码慢慢找,慢慢调试,功夫不负有心人,终于找到调用的地方了。
第一步:添加网站用户登录cookie

添加cookie之前

添加cookie之后
第二步:去掉网站头尾
chromedp.Evaluate(`$('.header').css("display" , "none");
$('.btn-group').css("display" , "none");
$('.container .container:first').css("display" , "none");
$('.breadcrumb').css("display" , "none");
$('.footer').css("display" , "none")`, &ins.buf),
打开网页后执行js代码把头尾隐藏掉
第三步:程序化,批量自动生成pdf
public static void createPDF(String folder , String cl , String pdfFile, String urlhref) {
try {
String fileName = pdfFile.replace("/", ":");
String filePath = folder fileName;
File srcFile = new File(filePath);
File newFolder = new File("/Volumes/disk2/myproject" File.separator cl);
File destFile = new File(newFolder, fileName);
if(destFile.exists()){
return;
}
if(srcFile.exists()){
//移动到对应目录
if(!newFolder.exists()){
newFolder.mkdirs();
}
FileUtils.moveFile(srcFile , destFile);
return;
}
if(!newFolder.exists()){
newFolder.mkdirs();
}
String url = "http://127.0.0.1:8888/convert/html2pdf?u=doctron&p=lampnick&url=" urlhref;
HttpEntity<String> entity = new HttpEntity<String>(null, null);
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<byte[]> bytes = restTemplate.exchange(url, HttpMethod.GET, entity, byte[].class);
if (bytes.getBody().length <= 100) {
if(urlList.containsKey(urlhref)){
Integer failCount = urlList.get(urlhref);
if(failCount > 3){
System.out.println("下载失败:" cl " / " pdfFile " " urlhref);
return;
}
failCount ;
urlList.put(urlhref , failCount);
}else{
urlList.put(urlhref , 1);
}
createPDF(folder , cl , pdfFile , urlhref);
}else{
if (!destFile.exists()) {
try {
destFile.createNewFile();
} catch (Exception e) {
e.printStackTrace();
}
}
try (FileOutputStream out = new FileOutputStream(destFile);) {
out.write(bytes.getBody(), 0, bytes.getBody().length);
out.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
最终成果:

文件夹分类存放

pdf文件
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com