如何设计一个系统架构(如何设计一个能够扩展到百万用户的系统)
作者 | Trung Anh Dang
译者 | 弯月
出品 | CSDN(ID:CSDNnews)
设计一个能够支持数亿用户的系统并非易事,对软件架构师来说是一个很大的挑战。
以下是本文涵盖的一些主题:
-
从最简单的开始:一个服务器搞定一切。
-
可扩展性的艺术:向外扩展,向上扩展。
-
扩展关系数据库:主从复制、主主复制、联合、分片、反规范化和 SQL 调优。
-
使用哪个数据库:NoSQL 还是 SQL?
-
高级概念:缓存、CDN、geoDNS.等。
本文不打算讨论高性能计算中常见的问题,例如容错、可靠性、高可用性等。
下面,我们开始。

下图是我设计的一个最基本的应用。最简单的方法是将整个应用程序部署在一个服务器上。这可能也是我们大多数人入门时期采用的方式。
-
一个网站(包括 API)在Apache(或 Tomcat)之类的Web服务器上运行。
-
一个Oracle(或 MySQL)之类的数据库。

同一台物理机器上同时拥有网络服务器和数据库服务器
但是,这样的架构存在以下缺点:
-
如果数据库出现故障,系统就会出现故障。
-
如果网络服务器出现故障,整个系统就会出现故障。
在这种情况下,我们没有故障转移和冗余。一旦服务器宕机就会导致整个系统宕机。
使用 DNS 服务器解析主机名和 IP 地址
在上图中,为了获取托管系统的服务器IP地址,用户(或客户端)需要连接到 DNS系统。在获得 IP 地址后,请求将直接发送到我们的系统。
每次访问网站时,计算机都会执行 DNS 查找。
通常,域名系统(Domain Name System,DNS)服务器都会使用托管公司提供的付费服务,无需在自己的服务器上运行。

可扩展性的艺术
由于数据量、工作量(例如交易数量)以及用户数量的增加等多种原因,我们的系统必须具备可扩展性。
可扩展性通常意味着能够通过添加更多资源来处理更多用户、客户端、数据、事务或请求,同时还不会影响用户体验。
我们必须决定如何扩展系统。在我们的这个例子中,有以下两种扩展类型:向上扩展(scale-up)和向外扩展(scale-out)。

向上扩展 vs 向外扩展
向上扩展:向现有服务器添加更多内存和 CPU
向上扩展也称为“垂直扩展”,指的是系统的资源最大化,以扩展其处理不断增加的负载的能力。例如,我们可以通过添加内存和CPU来增强服务器的能力。
如果我们的服务器拥有8GB内存,则只需更换或添加硬件就可以轻松升级到32GB甚至128GB。
垂直扩展的方法有很多,如下所示:
-
通过向 RAID 阵列添加更多硬盘来增加 I/O 容量。
-
通过使用固态硬盘(SSD)来改善 I/O 的访问时间。
-
使用具有更多处理器的服务器。
-
通过升级网络接口或安装其他接口来提高网络吞吐量。
-
通过增加内存来减少 I/O 的操作。
对于小型系统来说,垂直扩展是一个不错的选择,因为硬件升级的成本较低,但这种方式也有如下限制:
-
不可能无限扩展单个服务器的能力。主要取决于操作系统以及服务器的内存总线宽度。
-
在升级系统的内存时,必须关闭服务器,因此,如果系统只有一台服务器,停机是不可避免的。
-
功能强大的计算机通常比流行的硬件贵很多。
向上扩展不仅适用于硬件,同时也适用于软件,例如,优化查询和应用程序代码。
承受不了的一台服务器?
随着用户数量的增长,一台服务器是远远不够的。这时,我们需要考虑将单个服务器分成多个服务器。

随着用户数据增长,一台服务器永远都不够
这种架构有以下优点:
-
Web 服务器和数据库服务器可以分别调优;
-
Web 服务器需要更好的 CPU,而数据库服务器则需要更多内存;
-
Web 层和数据层可以使用单独的服务器,并独立地扩展。
向外扩展:添加任意数量的硬件和软件实体
向外扩展也称为“横向扩展”,我们可以向资源池添加更多实体(机器、服务)。水平扩展比垂直扩展更难实现,因为我们需要在构建系统之前考虑好。
通常,水平扩展的初始成本较高,因为即使是最基本的功能也需要多台服务器来处理,但后期的回报更丰富。因此,我们需要权衡利弊。
-
增加服务器数量意味着需要维护的资源也更多。
-
需要修改系统的代码,以实现在多台服务器上的并行处理和工作负载分摊。
使用负载均衡器来平衡所有节点之间的流量
负载均衡器是一种专门的硬件或软件组件,可将流量分散到服务器集群中,以提高系统(包括但不限于应用程序、网站或数据库)的响应能力和可用性。

使用负载均衡器来平衡所有节点之间的流量
通常,负载均衡器位于客户端与服务器之间,接收传入的网络和应用程序流量,并通过各种算法在多个后端服务器之间分配流量。所以,它也可以用在多种地方,例如;Web 服务器与数据库服务器之间,以及客户端与 Web 服务器之间。
HAProxy 和 NGINX 是两种流行的开源负载均衡软件。
负载均衡技术是一种保证容错的方法,可按如下方式提高可用性:
如果服务器 1 离线,所有流量都将路由到服务器 2 和服务器 3。网站不会离线。此时你需要向服务器池添加一个健康的新服务器,以平衡负载。
当流量快速增长时,你只需要在 Web 服务器池中添加更多服务器,负载均衡器就会将流量路由到新的服务器上。
负载均衡器采用各种策略和工作分配算法来优化负载的分配,如下所示:
轮转:在这种情况下,每个服务器按先进先出 (FIFO) 的顺序接收请求。
最少连接数:请求将被定向到连接数量最少的服务器。
最快响应时间:请求将被定向到响应时间最快(最近或频繁)的服务器。
加权:更强大的服务器收到的请求比较弱的服务器更多。
IP Hash:在这种情况下,根据计算的客户端 IP 地址的哈希值将请求重定向到服务器。
平衡多个服务器间请求的最直接的方法是使用硬件设备:
直接向共享 IP 添加服务器,或删除服务器。
可以根据需要进行负载平衡。
软件负载平衡比硬件负载平衡器更为廉价。这里的负载均衡在第 4 层(网络层)和第 7 层(应用层)运行。
第 4 层:负载均衡器使用网络层的 TCP 协议提供的信息。这一层的负载均衡在选择服务器时通常不会查看请求内容。
第 7 层:可以根据查询字符串、cookie 或任何头部信息平衡请求,也可以使用源地址、目标地址等常规的层信息来平衡请求。
扩展关系数据库
在简单的系统中,我们可以使用Oracle 或 MySQL之类的关系型数据库来保存数据项。但是关系数据库系统有其自身的挑战,尤其是当我们需要扩展它们时。
有许多技术可以扩展关系数据库:主从复制、主主复制、联合、分片、非规范化和 SQL 调优。
复制指的是一种将相同数据的多个副本存储在不同的机器上的技术。
联合(或功能分区)会按功能拆分数据库。
分片是一种与分区相关的数据库架构模式,可以将不同的数据放在不同的服务器上,不同的用户可以访问不同的数据。
反规范化可以将数据写入多个表,从而避免昂贵的连接,以牺牲部分写入性能为代价来提高读取性能。
SQL 调优。
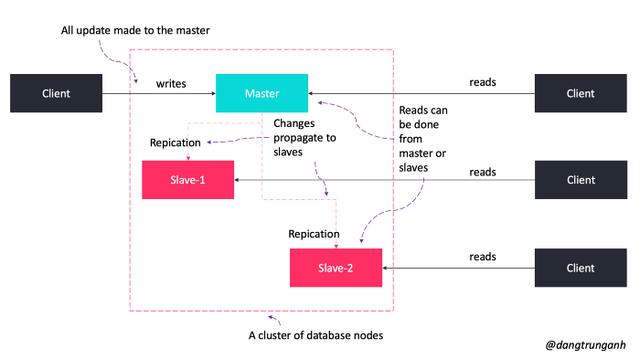
主从复制
主从复制技术能够将数据从一台数据库服务器(主服务器)复制到一台或多台数据库服务器(从服务器),如下图所示。
主节点更新
更新数据时,客户端需要连接到主服务器。
接着,数据会被复制到从服务器,直到所有数据在服务器之间保持一致。
这种方法仍然存在一些瓶颈:
如果主服务器由于某种原因宕机,仍然可以通过从服务器读取数据,只不过无法写入新数据了。
我们需要额外的算法来将从服务器提升为主服务器。
下面是一些解决方案,可以实现只有一台服务器处理更新请求的情况。
同步解决方案:数据修改事务需要等到所有服务器都接受后才提交(分布式事务),因此不会在故障转移时丢失数据。
异步解决方案:提交 -> 延迟 -> 复制到的其他服务器,因此在故障转移时可能会丢失一些数据更新。
如果同步解决方案太慢,则可以改为异步解决方案。
主主复制
每个数据库服务器都可以与其他服务器同时担任主服务器。在某个时间点,所有主服务器进行同步,以确保它们保存了正确以及最新的数据。
节点读写数据库
主主复制的优势在于:
如果某个主服务器出现故障,其他数据库服务器可以正常运行,而且还可以担负起主服务器的责任。当数据库服务器重新上线后,可以通过复制来更新数据。
主站可以位于多个物理站点,并且可以分布在整个网络中。
但服务器的更新能力受限于主服务器。
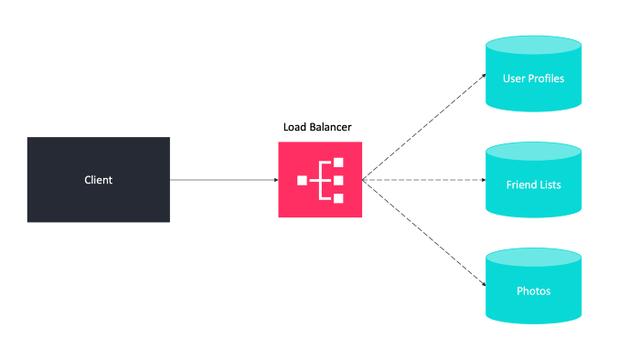
联合
联合(或功能分区)会按功能拆分数据库。例如,你可以拥有三个数据库,分别用于论坛、用户和产品,这样就可以减少每个数据库的读写流量,从而减少复制延迟。
按功能拆分数据库
更小的数据库可以将更多的数据保存在内存中,这样可以改善缓存的局部性,进而提高缓存命中率。由于没有单一的中央主序列化写入,你可以实现并行写入,从而提高吞吐量。
分片
分片(也称为数据分区)是一种将大数据库分成许多小块的技术,每个数据库只能管理数据的一个子集。
在理想情况下,每个用户都使用不同的数据库节点。这种方式助于提高系统的可管理性、性能、可用性和负载均衡。
每个用户只需与一台服务器对话,因此可以快速获得服务器的响应。
服务器之间的负载均衡更好,例如,如果我们有五台服务器,则每台服务器只需处理 20% 的负载。
在实践中,有许多不同的技术可以将数据库分解为多个小块。
水平分区
这种技术会将不同的行放入不同的表中。例如,如果我们将用户的个人资料存储在一个表中,则可以将ID小于1000的用户存储在一个表中,同时将ID大于1001且小于2000的用户存储在另一个表中。
不同行放入不同表中
纵向分区
在这种情况下,我们根据服务器中保存的与特定功能相关的表来划分数据。例如,如果我们正在构建一个类似 Instagram 的系统,我们需要在数据库中存储与用户、上传的照片以及他们关注的人相关的数据,我们可以将用户个人资料信息放在一个数据库服务器上,将好友列表放在另一个服务器上,而第三个服务器上则保存照片。
把划分数据存储在相应的表中
基于目录的分区
如果想以松散耦合的方式解决这个问题,则需要创建一个查找服务,该服务知道当前的分区模式,并拥有一份每个实体到其所属的数据库分片的映射。
当数据存储的扩展超出单个存储节点的可用资源,或者需要通过减少数据存储的竞争来提高性能时,我们就可以采用这种方法。但请记住,分片技术存在以下一些常见问题:
多表连接会变得更加昂贵,并且在某些情况下无法实现。
分片会损害数据库参照完整性。
数据库架构变更可能会变得非常昂贵。
数据分布不均匀,有些分片的负载很高。
反规范化
反规范化会以牺牲部分写入性能为代价来提高读取性能。数据的冗余副本会被写入多个表,以避免昂贵的多表连接。
当数据的分布采用联合和分片等技术之后,跨数据中心的管理连接会进一步增加复杂性。反规范化可以规避这种复杂的连接。
在大多数系统中,读取的次数大大超过了写入的次数,比例为 100:1,甚至 1000:1。因此,每当读取涉及复杂的数据库连接时,就可能会非常昂贵,并在磁盘操作上花费大量时间。
有些关系数据库,比如 PostgreSQL 和 Oracle 支持物化视图,它们会存储冗余信息,并保持冗余副本一致。
使用哪个数据库?
在数据库领域,有两种主要的解决方案:SQL 和 NoSQL。二者的构建方式、存储信息的类型以及使用的存储方法都不同。
SQL
关系数据库以行和列的形式存储数据。每一行包含关于一个实体的所有信息,每一列包含所有的单独数据点。
最流行的关系数据库包括 MySQL、Oracle、MS SQL Server、SQLite、Postgres 以及 MariaDB等。
NoSQL
NoSQL又称为非关系数据库。这些数据库通常分为五个主要类别:键值数据库、图数据库、列数据库、文档数据库以及 Blob 数据库。
键值存储数据库
数据存储在键值对数组中。“键”是链接到“值”的属性名称。常见的键值存储包括 Redis、Voldemort 和 Dynamo。
文档数据库
在这些数据库中,数据存储在文档中(而不是表中的行和列),并且这些文档归类成集合。每个文档可以具有完全不同的结构。
常见的文档数据库包括 CouchDB 和 MongoDB。
宽列数据库
列式数据库中,没有“表”,只有列,它们是行的容器。与关系数据库不同,我们不需要预先知道所有的列,每一行也不必具有相同的列数。
列式数据库最适合分析大型数据集,常见的有 Cassandra 和 HBase。
图数据库
这些数据库常用于存储关系最适合用图表示的数据。数据保存在拥有节点(实体)、属性(关于实体的信息)和线(实体之间的连接)的图结构中。
常见的图数据库包括 Neo4J 和 InfiniteGraph。
Blob 数据库
Blob 数据库就好像文件的键/值存储,可通过API访问,如 Amazon S3、Windows Azure Blob Storage、Google Cloud Storage、Rackspace Cloud Files 或 OpenStack Swift 等。
如何选择数据库?
数据库技术的选择没有统一的标准。这就是为什么许多企业同时使用 SQL 和 NoSQL 数据库来满足不同需求的原因。
如何选择?
水平扩展 Web 层
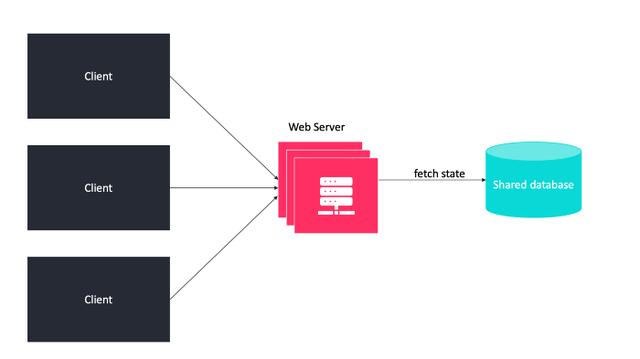
以上,我们谈到了数据层的扩展,下面我们来看看Web层的扩展。为了扩展Web层,我们需要将用户会话(状态)的数据存储在关系数据库或 NoSQL 等数据库中,将用户会话(状态)的数据移出 Web 层。这也称为无状态架构。
无状态系统很简单
不要使用有状态的架构。
我们必须尽可能选择无状态架构,因为状态的实现限制了可扩展性,降低了可用性,并增加了成本。
在上述情况下,负载均衡器的效率最高,因为它可以选择任何服务器来处理请求。
高级概念
缓存
负载均衡可以帮助你在数量不断增加的服务器上进行水平扩展,但缓存能够更好地利用现有资源,在后续请求期间更快地提供数据。
如果数据不在缓存中,则从数据库中获取,然后将其保存到缓存中并从中读取
通过向服务器添加缓存,我们可以避免直接从服务器读取网页或数据,从而减少响应时间,并降低服务器的负载。这也有助于提升应用程序的可扩展性。
缓存可以应用于许多层,例如数据库层、Web 服务器层和网络层。
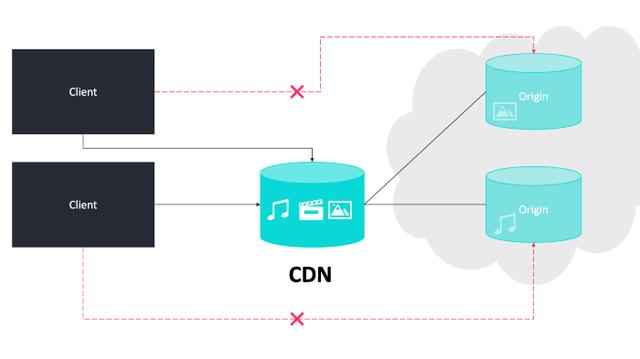
内容交付网络(Content Delivery Network,CDN)
CDN 服务器保存着内容(如图像、网页等)的缓存副本,并选择地理位置最近的服务器处理请求。
使用CDN 可以缩短了用户的页面加载时间,因为数据都是从地理位置最近的服务器上加载的。这也有助于提高内容的可用性,因为数据存储在多个位置。
CDN 的使用缩短了用户的页面加载时间,因为数据是在最接近它的位置检索的
CDN 服务器向Web 服务器发出请求以验证缓存的内容,并在需要时更新缓存。缓存的内容通常是静态的,例如 HTML 页面、图像、JavaScript 文件、CSS 文件等。
进军全球市场
当应用开始进军全球市场时,你需要在世界各地建立和运维数据中心,以确保产品可以全天候不间断地提供服务。传入的请求被路由到基于 GeoDNS 的“最佳”数据中心。
当应用走向全球
GeoDNS 是一项 DNS 服务,允许根据客户的位置将域名解析为 IP 地址。从亚洲连接的客户端获得的IP地址可能不同于从欧洲连接的客户端。
综合
通过迭代应用本文中的技术,例如无状态架构、应用负载均衡器、尽可能多地使用缓存数据、支持多个数据中心、在 CDN 上托管静态资产、通过分片扩展数据库规模等。我们就可以轻松地将系统扩展到 1 亿用户。
缩放是一个迭代过程
原文链接:https://levelup.gitconnected.com/how-to-design-a-system-to-scale-to-your-first-100-million-users-4450a2f9703d
参考链接:
https://httpd.apache.org
http://tomcat.apache.org
https://www.oracle.com/database/
https://www.mysql.com
https://en.wikipedia.org/wiki/Domain_Name_System
https://www.facebook.com/note.php?note_id=10150468255628920
,
















免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com