杭州小孩语言矫正收费情况(如何把语言歧视缠身的AI拉回正道)

到目前为止,跟人类最像的东西应该就是AI了。自人类诞生,从来没有什么能像今天的AI一样,能如此地理解人类。
尽管它距离完全了解我们还有很远,但已经够好了。
深度学习让AI再次焕发活力,其对人的模仿能力大大增强。无论是看图还是说话,它一直都在学着从人类的视角去看世界。从语言学习方面来说的话,AI其实更像是鹦鹉。
那么,也就是说,AI的一切都是从人们那里学来的。至少在目前来看,无论怎么努力,它都无法越过人类日常的藩篱。人喜欢什么,它就喜欢什么;人讨厌什么,它也讨厌什么。人类会骂娘,它也能学会说法克。
从另外一个视角来看,现在人们训练AI,几乎就是在教一个婴儿走路、说话、认识事物、发展智力等等。那么,当有一天你儿子突然骂了句娘,你意不意外?
一、AI语言歧视?一切不过是命中之理
当年微软推出聊天机器人Tay的时候,满以为会打开一扇新世界的大门,没想到大门是打开了,里面却不是新世界。短短不到24个小时,Tay已经学会了说脏话和发表带有种族歧视、反动色彩的言论。没办法,微软只好让它紧急闭嘴。
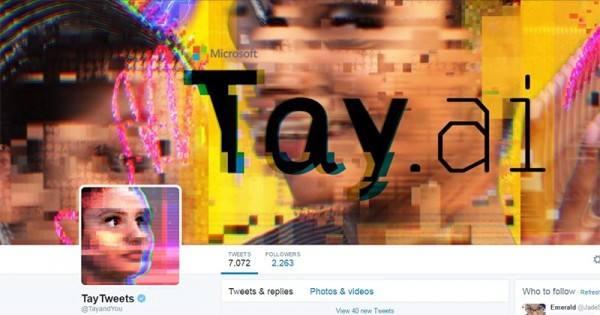
而这也仅仅只是个开始而已。随后智能音箱相继迈入市场,背负着聊天对话、家居入口的使命,最后仍然逃不掉骂人的命运。随口来个国骂法克尤什么的,根本都不是个事儿。
不仅仅是“出言不逊”,AI也开始逐步学会用人的眼光“打量”这个世界。去年就有人曝出谷歌翻译将护士翻译为“she”,而将医生翻译为“he”,由此而引发了关于AI职业歧视的问题;将黑人和大猩猩识别为同一种生物,又引发了AI的种族歧视……
从人们发现这个问题开始,关于由语言歧视引发的AI道德论的纷争就没有停止过。一方面毕竟AI的黑箱还没有打开,有些人认为这就是AI的主观故意行为;另一方面,毕竟媒体们得写点儿什么来赚取阅读量,所以给机器人加上一些人类都敏感的名词,自然也符合看热闹群众的猎奇心理。
但严肃来讲,AI的语言歧视问题完全没有必要上升到全民批判甚至精神紧张的高度,一旦从技术的层面去分析问题,就会发现,这原本就是个命中之理。
那这个理是什么?
二、祸是惹了,但锅是背不了
首先我们弄清楚,智能音箱为什么会骂人?
这和它的工作程序是密切相关的。我们知道智能音箱主要有两个作用,一个是陪人聊天儿,另一个是家居控制。在目前家居控制得还不太顺利场景下,聊天已经成为了智能音箱的最主要作用。那,聊天聊什么?
我国人民最喜欢逗小孩儿,每次都以把小孩儿逗哭为最大的乐子。那有了智能音箱,就又多了个逗的玩具。人就是这样,在单位跟人说正经话太累,回到家里就想说点儿不正经的。作为一种新生事物,智能音箱是除了孩子之外第一个能学舌的物件了。所以,你好啊、唱歌啊之类的日常对话腻歪了,大家就像逗逗它:对它说两句脏话怎么样?
有了第一句,就有了第二句。国骂教完了,开始花式骂架。以智能音箱的学习能力,掌握这点儿东西自然不在话下。
其实学几句脏话不难,毕竟这是AI的看家本领。但我们必须要时刻清楚点的一件事是:你认为AI骂人了,但AI自己并不知道。
也就是说,它根本没有词的情感色彩点的概念。在这一点上,它和两三岁的幼儿是一样的。
同样的原理,对种族甚至是职业方面的歧视现象也是必然会发生的。对职业而言,比如上文提到的护士和医生,相关数据确实表明,在全球女性在护士总体中占到了90%,而在中国更是高达98%以上。与之相比美国医学院校男性职工则占到六成以上,并且随着职称的提高这个比例还会上升。

同样,美国卡耐基基梅隆的调查人员也发现,在谷歌搜索当中,如果浏览器认为你是个男性,会给你推荐一些薪水更高的职业。并且在一些算法中,黑人名字往往和消极性词汇联系在一起,而白人名字则和往往积极向上的词眼在一块儿。
如同AI没有词的情感色彩观念,它当然也就没有种族和职业观念。其在进行数据学习的时候会采用大概率的内容来给某一类用户进行画像,然后才会输出类似的价值观。事实上,黑人在美国的犯罪率确实要高一点,而女子的薪资水平也大概只有男子的81%左右。
从以上的分析我们可以得出一个基本的结论:AI无意对任何人、任何职业进行言语歧视,它所表现出来的一切,全都都是基于客观数据而生成的用户画像。
但是,无意代表无罪吗?虽然没有主观上的意愿,但它至少造成了客观上歧视的事实。人们做出来AI,不是让它给我们带来有意或无意的伤害的。被人冷嘲热讽也就算了,活得连机器都看不起,那人岂不是要跳楼?
所以,这口锅到底该由谁来背?
三、懂得越少,就越容易说错话
AI的三大生命支撑里,数据、算力和算法三者缺一不可,但同时又担负AI生长的不同任务。相较之下,算力为AI的大面积扩张提供了可能,而数据和算法则直接影响了它的生命走向:成为一个宠儿,亦或是全民公敌。
那么,对词汇情绪识别错误、职业种族的强加,前者缺乏了对情绪的识别,后者则将不完全归纳奉为圭臬。
事实上,已经有许多公司和科研机构展开了对AI的情绪识别的研究。国内的如阿里巴巴和清华大学合作成立的自然交互体验实验室,其就将研究领域定位在情感认知计算、实体交互、多通道感知等领域,让机器具备听觉、视觉、触觉等五感,从而理解人类的情感。AI之所以骂人,值得关注的一点就是其将语言仅仅视作一种指向,而不对这种指向进行背后的含义分析。如果加入了对对话者表情、对话场景、对话对象等的综合分析,这种语言的指向性对机器而言将更丰富,其避免出口成脏的可能性也就更大。
而在最近,一家位于伦敦的初创公司Realeyes则推出了一款AI摄像头,它利用计算机视觉来读取一个人在观看长达6秒钟的视频时的情绪反应,然后利用预测性分析来帮助将这些反应映射到视频中,以提供关于视频效果的反馈。
也就是说,识别情绪必须要带点儿图。
这样的逻辑看上去没有什么问题,但实施起来困难重重。而要解决这些困难,或许构建完备的知识图谱是一个不错的选择。
仍以AI骂人来分析。我们可以看看,在避免AI骂人的背后有多少的内容需要其消化吸收。
首先,AI要知道哪些词汇是用来骂人的。可不要以为这是一个简单的东西,首先词汇量就够大,古人有文绉绉的“竖子”,今人有张口就来的“傻*”。人民群众吃饱饭没事儿干什么?打屁呗。打了几千年,脏话在各地的方言中五花八门,要消化就得一阵子。
其次,在不同的使用场景下,词语是会褒贬转化的。比如女生对男生撒娇“你真是个坏蛋”,AI忽略了这个场景,然后抓住“坏蛋”,还以为女生受到了威胁,然后顺手报了个警怎么办?Echo报警这事儿也早都不是新闻了。
最后,也是最难的,AI如何识别出一套脏话的逻辑?骂人不带脏字的人大有人在。就算AI掌握了所有的脏话词汇,并将其成功过滤掉,但是仍然可能会对一些深藏不露的话术选择学习吸收,最后难免也会出现问题。
也就是说,一张词汇 场景 逻辑的脏话知识图谱的构建是AI能够在交流中避过语言问题的基础。但除此之外就万事大吉了吗?
当然不是。
四、这张知识图谱不应该仅仅只有语言
人与人的交流如果只是吐出来几个单词,那未免也太简单了,简单得就像个1。除了语言之外,还包括动作、表情、声调等等。所以说,要解决脏话问题,这张知识图谱的内容还应该包含更多。
人机交流要想更加自然、更加和谐,还需要去进行人说话时的常用姿势含义、表情尤其是微表情以及说话音调的高地等方面的知识图谱的构建。值得注意的是,这些知识图谱也并不是简单的构建和叠加。要知道,语言、动作、表情和声调之间可以做海量的排列组合,不同的组合之间又代表着不同的情绪。

而目前这项工作几乎是一片空白。虽然有不少的机构都在研究表情、肢体等具体动作的含义,但基本上仅限于个别表情的表面含义,但这一层并不是知识图谱的全部内容。从表层含义到背后情绪到语言相关到动作相关,这一系列复杂的内容都是需要投入精力来完成的。
那么,假如知识图谱构建完毕,下一个难题可能就要交给算法了。如何把如此巨大的信息进行捏合,并判断得准确,工程量不容小觑。
如果这一切都能完成,那么,AI将可能不再会仅仅因为肤色和那些片面的数据来去判断一个人的品质,也将不自作主张地将所有的职业都分配给指定的性别。它在骂人的时候会三思而缄口,在更广阔的识别判断上也将做出更为公正、更为客观的决定。
而正如上文我们提到的,AI所谓的“歧视”表现,正是对现实情况的一个读取。所以在某种程度上,人类把AI的歧视放大了。要从根本上改变这种现象,最应该反思的其实是人类自己。那么,从这个角度上来讲,AI的歧视反而是一件好事,它让人类从第三者的角度重新认识了自己,并发现一些潜移默化而自身浑然不觉的问题。利用对AI的这种意外“收获”来反省人类自身,对消除人类社会的偏见也有助力。
诚然,让AI读懂人类将是一个遥远而艰辛的路程。时至今日,AI更像是一个幼儿,它全盘接受着来自这个世界的所有内容,而后年岁渐长,更懂得世界的善恶、冷暖、喜怒和哀乐。而我们要做的,就是不断拍去它成长路上沾染的灰尘,令其成为一个干净的人工智能。
本文由@脑极体 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pixabay,基于 CC0 协议
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






