阿里云云安全解决方案(阿里云云原生一体化数仓)
MaxCompute是一款多功能、低成本、高性能、高可靠、易于使用的数据仓库和支持全部数据湖能力的大数据平台,支持超大规模、serverless和完善的多租户能力,内建企业级安全能力和管理功能,支持数据保护和安全共享,数据/生态开放,可以满足数据仓库/BI、数据湖非结构化数据处理和分析、湖仓一体联邦计算、机器学习等多业务场景需求。
阿里云MaxCompute提供了全托管的服务,用户开箱即用,只需要关注自己的业务和资源使用,真正做到Paas平台Saas模式使用。MaxCompute是一个真正的云原生多租户平台,可以做到较低的资源成本,让用户获得更低的TCO。租户之间可以方便的共享数据,而不必在多个Hadoop实例之间开接口。从接入和使用角度看,简单易用,支持多引擎, 可上可下。很多使用MC的客户反馈,不是业务不能迁移,只是再也没有其他更好用更经济的选择了。从数仓管理能力上看,MaxCompute提供统一元数据、统一的账号和权限体系,完善的企业级安全能力。从资源使用角度上看,自适应的按需弹性资源,避免资源浪费或不足,节省成本又满足需求。业务负载隔离,消除业务间资源争抢。从规模和数据存储角度看,支持TB到EB级的大规模部署应用和扩展。连接广泛外部数据源,支持结构化和非结构化数据存储和处理,支持联邦计算。
MaxCompute积累了阿里多年双11自动优化和稳定可靠能力,这一点是任何Hadoop商业版产品所不具备的, MaxCompute凭借先发优势和阿里持续自身业务锤炼,让产品非常成熟稳定。

MaxCompute是基于大数据技术的数仓,采用了自研的分布式存储引擎pangu、分布式资源管理调度器fuxi,和分布式高性能SQL引擎,与开源的HDFS、Yarn、hive Spark SQL关系对等,但能力全面领先开源。MaxCompute的存储包括数仓schema on write模式所需的库表,也包括最近开放的volume非结构化存储。MaxCompute采用了大数据存算分离的架构,可以在大规模场景下进一步的降低成本,降低客户TCO。MaxCompute提供了沙箱运行环境,让用户的UDF和业务代码更安全也更灵活的运行在多租环境中,免去了在数据外部由用户管理私有代码的麻烦和限制。
MaxCompute通过tunnel服务,收敛了数据入仓的通道,对外只暴漏tunnel endpoint,让数据出入仓更安全,同时检查文件格式、收集元数据,用于后续读写优化,以极小的代价获得相比Hive 近一个数量级的性能领先差异,这正是数仓模式的优势所在。MaxCompute还提供了web控制台、IDE studio、CMD、SDK等多种连接方式, MMA迁移工具帮助用户快速迁移到MaxCompute,Lemming提供边缘端的采集、计算和云边协同计算。
MaxCompute对接OSS数据湖对象存储,通过DLF获取湖上元数据,可以做到湖仓一体联邦,这时MaxCompute是仓,OSS是湖。对接客户的Hadoop系统,通过自动获取hms中元数据,自动映射hive database为MaxCompute 项目的external project,免去建外表即可直接将仓内数据与hive、HDFS数据关联计算,这时MaxCompute是仓,Hadoo是湖。
MaxCompute周边的二方生态和三方生态也构成了完整的数据链路和大数据解决方案。MaxCompute可以通过Dataworks数据集成获取批加载的数据,还可以直接对接Flink、Kafka、Datahub等消息队列或流式数据,实时入仓。Hologres可与MaxCompute无缝集成,权限互认、pangu直读,基于数仓模型直接获得交互式分析的高并发、低延时能力。MaxCompute的黄金搭档DataWorks是一套与MaxCompute一起发展起来的开发治理工具,有了DataWorks可以更好的发挥MC的能力和优势。
MaxCompute还支持PAI、ES、OS以及ADB、SLS等二方引擎,实现机器学习、检索、数据集市分析、日志处理等能力。并支持QuickBI、DataV等报表、dashboard、大屏应用。数据中台治理工具Dataphin、DataQ都将基于MaxCompute的多年阿里最佳实践,产品化赋能客户。更有Tableau、帆软等三方生态工具已经与MaxCompute互认,给用户更多选择。

可以从四个方面预设数据安全问题,下面对MaxCompute数据安全能力的解读会对应到这些问题上,解决企业数据安全的问题,保障数据安全。
|
what |
where |
who |
whether |
|
有什么数据? |
数据在哪里? |
谁能用数据? |
是否被滥用? |
|
有什么用户? |
从哪里可以访问数据? |
谁用了数据? |
是否有泄露风险? |
|
有什么权限? |
数据能下载到哪里? |
是否有丢失风险? |
按照防数据滥用、防数据泄露、防数据丢失这个三个点,看下MaxCompute的安全体系核心功能。先从MaxCompute的数据安全核心能力开始。
防数据滥用包含:细粒度的权限管理(ACL/Policy/Role)、Label Security分级管理
防数据泄露包含:认证、租户隔离、项目空间保护、网络隔离
MaxCompute和DataWorks关系,以及MaxCompute隔离机制
在当前云上体系中,用户需在阿里云注册一个主账号,才可以申请开通MaxCompute,创建项目空间。
MaxCompute的付费模式有两种,按量付费(后付费共享资源)和包年包月(预付费独享资源),当开通MaxCompute项目时,需要开通DataWorks工作空间,DataWorks可以理解为一站式开发治理工具,包含数据采集、脚本开发、调度、数据服务等。MaxCompute包含表、字段、UDF、resource、元数据等。DataWorks一个工作空间可以帮忙两个项目,也就是两个MaxCompute project,一个开发环境一个生产环境,这两个project是隔离的,防止生产环境中关键敏感数据的泄露。

MaxCompute访问与控制
当前MaxCompute访问认证鉴权经过以下步骤,身份认证用于身份识别;请求源检查(ip白名单)用户检查是否设置网络隔离;项目空间状态检查,检查项目空间是否开启项目保护等安全设置;检查MaxCompute项目的labelsecurity|rle|policy|acl等权限管理规则。接下来就按照这个顺序讲一下MaxCompute的安全机制,到权限管理部分再详细展开讲一下权限体系。
认证流程
- 每个阿里云账号都需要创建相应的访问密钥AccessKey,主要用于在阿里云各产品间互相认证使用权限。
- 用户可以在云控制台中自行创建AccessKey。AccessKey由AccessKeyId和AccessKeySecret组成,其中AccessKeyId是公开的,用于标识用户身份,AccessKeySecret是秘密的,用于用户身份的鉴别。AccessKey可以更换。
- 当用户向MaxCompute发送请求时,首先需要将发送的请求按照MaxCompute指定的格式生成签名字符串,然后使用AccessKeySecret对签名字符串进行加密以生成请求签名。MaxCompute收到用户请求后,通过AccessKeyId找到对应的AccessKeySecret,以同样的方法提取签名字符串和验证码,如果计算出来的验证码和提供的一致即认为该请求是有效的;否则,MaxCompute将拒绝处理这次请求,并返回HTTP 403错误。
当用户真正发生请求时,会把(Accessld、请求时间、请求参数) 签名以固定的格式发送到MaxCompute前端,MaxCompute前端包含HttpServer和tunnel(数据上传下载通道)。这个过程需要检查用户请求是否过期。当MaxCompute拿到用户请求的AK信息,跟AK服务上的AK信息做对比,如果AK信息一致,则代表用户请求有效。MaxCompute的数据资源及计算资源的访问入口都需经过身份验证。用户认证 检查请求 Request 发送者的真实身份:正确验证消息发送方的真实身份,正确验证接收到的消息在途中是否被篡改。云账号认证使用消息签名机制,可以保证消息在传输过程中的完整性 Integrity 和真实性 Authenticity。

RAM子账号
- MaxCompute支持RAM鉴权。RAM(Resource Access Management)是阿里云提供的资源访问控制服务。通过RAM,主账号可以创建出子账号,子账号从属于主账号,所有资源都属于主账号,主账号可以将所属资源的访问权限授予给子账号。
- 用户对MaxCompute资源访问分为两种,即用户主账号访问和用户子账号访问。主账号是阿里云的一个账号主体,主账号下可以包含不同的子账号以便用户可以灵活使用。MaxCompute支持主子账号的权限访问策略。
- 当用户使用主账号访问时,MaxCompute会校验该主账号是否为对应资源的所有者,只有对应资源的所有者才具备访问该资源的权限。
- 当用户使用子账号访问时,此时会触发子账号授权策略。MaxCompute会校验该子账号是否被对应主账号授予了访问该资源的权限,同时也会校验该子账号对应的主账号是否具有该资源的所有者权限。
一个主账号可以把当前主账号下的RAM账号加入MaxCompute project,也可以把其他主账号加入MaxCompute project,但不可以把其他主账号下的RAM账号加入MaxCompute project。

RAM Role
- RAM角色(RAM role)与RAM用户一样,都是RAM身份类型的一种。RAM角色是一种虚拟用户,有确定的身份,可以被赋予一组权限策略,但没有确定的登录密码或访问密钥。RAM角色需要被一个受信的实体用户扮演,扮演成功后实体用户将获得RAM角色的安全令牌,使用这个安全令牌就能以角色身份访问被授权的资源。
- 您可以通过RAM访问控制台创建RAM角色并修改RAM角色的权限策略,然后将RAM角色添加至MaxCompute项目。后续项目中的RAM用户可以扮演该RAM角色执行操作。
- RAM角色为访问控制平台中的角色,非MaxCompute项目内的角色。
- RAM Role是跨产品之间访问数据的一个角色

角色
- 角色(Role)是MaxCompute内一组访问权限的集合。当需要对一组用户赋予相同的权限时,可以使用角色来授权。基于角色的授权可以大大简化授权流程,降低授权管理成本。当需要对用户授权时,应当优先考虑是否应该使用角色来完成。
- 一个用户可以被分配到多个角色。从而拥有这些角色的权限的合集。
- MaxCompute角色有两种类别账户级别和项目级别。
|
角色类别 |
角色名称 |
角色说明 |
|
账户级别(tenant) |
Super_Administrator |
MaxCompute内置的管理角色。除了不能创建项目、删除项目、开通服务,其他在MaxCompute上的操作权限等同于阿里云账号。 |
|
Admin |
MaxCompute内置的管理角色。用于管理所有对象及网络连接(Networklink)的权限。 | |
|
项目级别(Project) |
Project Owner |
项目所有者。用户创建MaxCompute项目后,该用户为此项目的所有者,拥有项目的所有权限。除项目所有者之外,任何人都无权访问此项目内的对象,除非有项目所有者的授权许可。 |
|
Super_Administrator |
MaxCompute内置的管理角色。拥有操作项目内所有资源的权限和管理类权限。权限详细信息,请参见项目级别管理角色权限说明。项目所有者或具备Super_Administrator角色的用户可以将Super_Administrator角色赋予其他用户。 | |
|
Admin |
MaxCompute内置的管理角色。拥有操作项目内所有资源的权限和部分基础管理类权限。权限详细信息,请参见项目级别管理角色权限说明。项目所有者可以将Admin角色赋予其他用户。Admin角色不能将Admin权限赋予其他用户、不能设定项目的安全配置、不能修改项目的鉴权模型、所对应的权限不能被修改。 | |
|
自定义角色 |
非MaxCompute内置的角色,需要用户自定义。 |
租户
- 每个账号是一个租户(建议一个一级部门对应一个独立的租户),租户间的数据安全隔离是在逻辑层控制的,并非物理隔离。
- 租户是计量和计费的主体。
- 通过多租户机制,各部门可以独立管理自己的数据。除非显式授权,否则租户之间无法访问对方的数据。
- 租户可以拥有一个或多个项目。来自多个部门成员也可以共用一个项目(类似虚拟联合项目组)
- 系统提供统一的权限管理模型,即不管是项目内部的数据授权,还是项目之间的数据授权,都遵循同一套权限管理机制。
- 在物理层面,如果存在多个集群,那么每个租户归属其中一个集群,即一个租户不能跨多个集群存储数据。但是在逻辑层面,用户是无需关心该租户的实际物理存储集群的,底层集群的分布对用户透明。

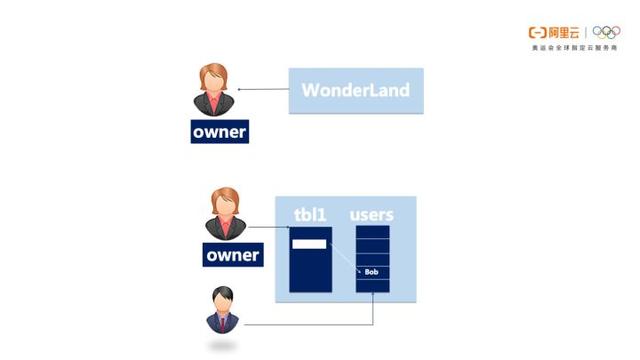
项目空间用户管理
Alice 创建一个 名为 WonderLand的项目,自动成为 Owner
没有 Alice 的授权,其他任何人都无法访问 WonderLand
Alice 要授权 Bob 允许他访问 WonderLand中的一些对象:
首先,Bob 要有一个合法的云账号或者是Alice的RAM子账号
然后,Alice 要 把 Bob 的账号加到项目中来
最后,赋一些对象的权限给 Bob
Alice 要禁止 Bob 访问项目,则直接将他的账号从项目中移除即可
Bob 虽然被移除出了项目,但他之前被授予的权限仍然保留在项目中。
下次一旦他被 Alice 加入同一个项目,原有的权限将会被自动激活。 除非彻底清除Bob的权限。
控制访问
Ip白名单
- MaxCompute支持在访问认证基础上增强的一种以IP白名单的方式,进行访问控制。
- 可以配置project访问机器的白名单来进行限制Ip访问。
- 如果使用应用系统(如ODPSCMD或者SDK客户端)进行项目空间数据访问,需要配置ODPSCMD或者SDK客户端所在的部署机器的IP地址。如果使用了代理服务器或者经过了多跳代理服务器来访问MaxCompute服务实例,需要添加的IP地址为最后一跳代理服务器的IP地址。
- 一些其他需要访问MaxCompute服务实例中所有project的其他上层业务系统IP发生变化的时候,如果没有全局性IP白名单配置,需要找到所有设置白名单的project列表一个个进行新IP的修改配置,非常容易出错。为此MaxCompute实现了系统级别IP白名单功能,系统级别IP白名单是MaxCompute实例服务级全局性配置。
当用户请求提供的IP是否跟MaxCompute元数据存储的白名单匹配,做一个项目级别的检查,如果IP匹配允许访问。白名单格式允许固定IP、掩码或者IP段的方式。可以查看下面的例子
作用范围:项目空间
白名单格式:101.132.236.134、100.116.0.0/16、101.132.236.134-101.132.236.144
设置白名单:adminConsole;setprojectodps.security.ip.whitelist=101.132.236.134,100.116.0.0/16
关闭白名单:清空白名单*

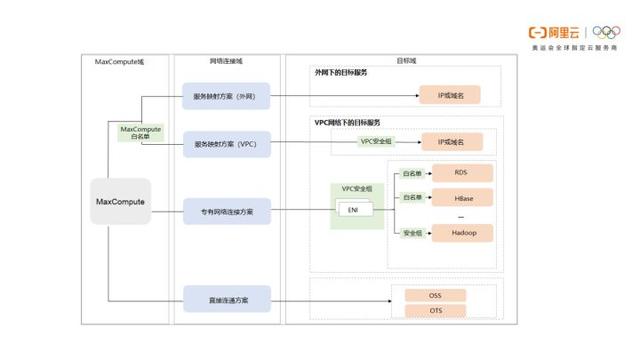
VPC访问MaxCompute
MaxCompute作为阿里云开发的海量数据处理平台,在安全性方面需要满足安全隔离规范的要求。因此,MaxCompute团队增加了MaxCompute对专有网络(VPC)的支持,为MaxCompute配置使用限制,即MaxCompute VPC的限制。目前MaxCompute支持VPC的具体情况如下所示:
- 经典网络/VPC网络/Internet网络三网隔离,只能访问各自对应的endpoint及VIP。
- 经典网络能够访问所有project 。
- 没有配置VPCID及IP白名单的project可以被三种网络中请求通过的相应域名访问,没有限制。
- 配置了VPC_ID的project只能被对应的VPC访问。
- 配置了IP白名单的project只能被对应的机器访问 。
- 对于加了代理的访问请求,判断为最后一跳代理IP及VPCID为准 。
下图为具体示例
下图绿色部分为经典网络部分,蓝色为用户本身的VPC网络,红色为公共云访问。
- 经典网络中只能访问Intranet_inner
- VPC网络中中只能访问Intranet_public
- Internet网络中只能访问Internet_vip
- 经典网络能够访问所有project
- 配置了VPC_ID的project只能被对应的VPC访问
- 配置了Ip白名单的project只能被对应机器访问
- 没有配置VPCID及Ip白名单的project可以被三种网络中请求通过相应域名访问,没有限制,如P5
- 对于加了代理的访问请求,判断为最后一跳代理IP及VPCId为准
- 左侧连接线为准,其他连接将不能访问

公共云MaxCompute访问外部网络
服务映射方案(外网)
适用于通过UDF或外部表访问处于外网中的目标IP或域名的场景。需要提工单申请,如果目标IP或域名不存在安全限制,审核通过后即可访问目标IP或域名。
服务映射方案(VPC)
适用于MaxCompute与VPC间的网络已连接,需要通过UDF或外部表访问处于VPC网络中的单个IP或域名的场景。只需要将MaxCompute项目所属地域的IP网段添加至VPC的安全组,并将目标IP或域名所属VPC实例添加至MaxCompute项目,完成双向授权后,即可访问目标IP或域名。
专有网络连接方案
适用于通过外部表、UDF或基于湖仓一体架构访问处于VPC网络下的RDS、HBase集群、Hadoop集群场景。您需要通过VPC网络管理控制台进行授权以及配置安全组,在MaxCompute控制台创建MaxCompute与VPC网络之间的连接,配置RDS、HBase集群、Hadoop集群等目标服务安全组,以此来建立MaxCompute与目标服务间的网络通路。
直接连通方案
适用于通过UDF或外部表访问阿里云OSS、OTS(Tablestore)服务的场景。OSS、OTS服务与MaxCompute连通无需申请开通专有网络。
项目空间保护
当有project:WonderLand、SecretGarden,可能有以下风险导致数据流出。1、SQL:create table SecretGarden.Gotit as select * from WonderLand.customers;
2、MR:通过MR将表读出,然后写入SecretGarden中去
3、导出:通过数据导出工具,将该表数据导出
4、PAI:将数据间接导出
5、其他.....
当启动项目保护模式,也就是设置ProjectProtection规则:数据只能流入,不能流出set ProjectProtection = true
设置后,上述的4种操作将统统失效,因为它们都触犯了ProjectProtection规则。
当启动项目保护但依旧需要对某些表可以允许流出时,有两种方案
方案1:在设置项目保护(ProjectProtection)的同时,附加一个例外策略(exception):
set ProjectProtection = true with exception ;

方案2:将两个相关的项目空间设置为互信(TrustedProject),则数据的流向将不会被视为违规:
add trustedproject = SecretGarden;

应用场景
安全特性:
受保护的MC项目,允许数据流入,禁止未显式授权的数据输出
应用场景:
避免将高敏感的数据(例如企业员工工资信息)被随意导出到不受保护的项目中
实现逻辑:将高敏感的数据所在的MaxCompute项目设置为强保护模式,这样该数据只能在当前受保护的项目中被访问到,用户即便已获得数据访问权限也无法在项目之外读取这份数据或者将数据导出项目。经过加工或脱敏后产生的新数据,经过显示授权之后,可以流出受保护的项目。
安全特性:
受保护的MaxCompute项目,对数据访问行为进行多因素校验,包括数据流出目的地(IP地址、目标项目名称)、限制数据访问时间区间等20多个维度。即便用户账号密码被盗取,也不能随意拿走数据。
应用场景:
担保模式的数据交换
场景说明:两个单位要使用对方的敏感数据,但是又不愿意、不允许把数据直接给到对方,怎么做?
实现逻辑:双方将数据导入到受保护的项目中(黑盒子),在受保护的项目中完成两边数据的整合加工,产生一个不敏感的结果数据,经过显示授权之后,可以流出受保护的项目,返回给双方。这样双方都使用到了对方的数据,却拿不走。
数据访问控制机制
权限检查顺序
MaxCompute的权限检查顺序如下:LabelSecurity Label检查--> plicy(DENY直接返回)policy检查--> ACL(绑定role)ACL检查,role和用户权限叠加-->package 跨project的权限检查。我们也按照这个顺序讲一下MaxCompute的权限相关的功能。
授权方式
授权需要三部分内容,主体(被授权人),客体(MaxCompute项目中的对象或行为),操作(与客体类型有关)。授权时,需要把用户加入项目内,再分配一个或多个角色,这样就会继承角色内所有的权限。
授权的内容包括:表(可以按字段授权)、函数、资源
有3种访问控制方式:ACL(Access Control List)、Policy、Label
授权对象:单个用户、角色
应用场景描述:
当租户Owner决定对另一个用户B授权时,首先将该用户B添加到自己的租户中来。只有添加到租户中的用户才能够被授权。用户B加入租户之后,可以被分配到一个或多个角色(也可以不分配任何角色),那么该用户B将自动继承所有这些角色所拥有的各种权限。当一个用户离开此项目团队时,租户Owner需要将该用户从租户中移除。用户一旦从租户中被移除,该用户将不再拥有任何访问此租户资源的权限。

ACL(Access Control Lists)授权
ACL权限控制为白名单授权机制,即允许用户或角色对指定对象执行指定操作。ACL权限控制方式简单明了,可实现精准授权。
- 主体:被授权人,必须存在于project中。
- 授权人为执行授权操作的用户。授权人需要具备为目标客体和目标操作授权的权限,才可以执行授权操作。
- 使用阿里云账号执行授权操作时,支持为当前账号下的RAM用户和其他阿里云账号授权。
- 使用RAM用户账号执行授权操作时,仅支持为隶属同一个阿里云账号的其他RAM用户授权,不支持为其他账号授权。
- 客体:对象:项目、表/视图、字段、函数、资源、实例、Package
- 角色(role)是一组权限的集合
- 对象删除时,所有相关的ACL也被删除
因此向项目中添加用户并授权可以有以下两种方式,通过添加用户并授权,或者创建角色,对角色授权,添加用户,再对用户授予角色。
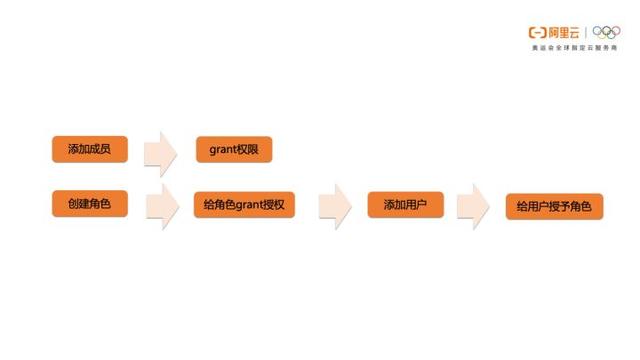
示例
grant CreateTable, CreateInstance, List on project myprj to user Alice;
增加用户权限
grant worker to aliyun$abc@aliyun.com;
加用户进角色
revoke CreateTable on project myprj from user Alice;
删除用户权限
权限说明
|
客体(Object) |
操作(Action) |
说明 |
支持的授权人 |
|
Project |
Read |
查看项目自身(不包括项目中的任何对象)的信息。 |
项目所有者(Project Owner) |
|
Write |
更新项目自身(不包括项目中的任何对象)的信息。 | ||
|
List |
查看项目所有类型的对象列表。例如show tables;、show functions;等。 |
项目所有者(Project Owner) 具备Super_Administrator或Admin角色的用户 | |
|
CreateTable |
在项目中创建表(Table)。例如create table <table_name>...;。 | ||
|
CreateInstance |
在项目中创建实例(Instance),即运行作业。 | ||
|
CreateFunction |
在项目中创建自定义函数(Function)。例如create function <function_name> ...;。 | ||
|
CreateResource |
在项目中添加资源(Resource)。例如add file|archive|py|jar <local_file>... ;、add table <table_name> ...;。 | ||
|
All |
具备上述Project的所有权限。 | ||
|
Table |
Describe |
读取表的元数据信息,包含表结构、创建时间、修改时间、表数据大小等。例如desc <table_name>;。 |
表所有者 项目所有者(PO) 具备Super_Administrator角色的用户 具备Admin角色的用户(不支持修改表所有人) |
|
Select |
查看表的数据。例如select * from <table_name>;。 | ||
|
Alter |
修改表的元数据信息,包含修改表所有人、修改表名称、修改列名、添加或删除分区等。例如alter table <table_name> add if not exists partition ...;。 | ||
|
Update |
更新表数据。例如insert into|overwrite table <table_name> ...;、update set ...;、delete from …;。 | ||
|
Drop |
删除表。例如drop table <table_name>;。 | ||
|
ShowHistory |
查看表的备份数据信息。例如show history for table <table_name>;。 | ||
|
All |
具备上述Table的所有权限。 | ||
|
Function |
Read |
读取自定义函数(MaxCompute UDF)的程序文件。 |
函数所有者 项目所有者(PO) 具备Super_Administrator或Admin角色的用户 |
|
Write |
更新自定义函数。 | ||
|
Delete |
删除自定义函数。例如drop function <function_name>;。 | ||
|
Execute |
调用自定义函数。例如select <function_name> from ...;。 | ||
|
All |
具备上述Function的所有权限。 | ||
|
Resource |
Read |
读取资源。 |
资源所有者 项目所有者(PO) 具备Super_Administrator或Admin角色的用户 |
|
Write |
更新资源。 | ||
|
Delete |
删除资源。例如drop resource <resource_name>;。 | ||
|
All |
具备上述Resource的所有权限。 | ||
|
Instance |
Read |
读取实例。 |
项目所有者(PO) 具备Super_Administrator或Admin角色的用户 |
|
Write |
更新实例。 | ||
|
All |
具备上述Instance的所有权限。 | ||
|
Download |
对角色或用户使用Tunnel下载表、资源、函数、实例的行为进行管控 | ||
|
Label |
为表或列数据设置敏感等级标签为用户或角色设置访问许可等级标签 |
Policy授权
- Policy授权是一种新的授权机制,它主要解决ACL授权机制无法解决的一些复杂授权场景,比如:
- 一次操作对一组对象进行授权,如所有的函数、所有以 “abc_” 开头的表。
- 带限制条件的授权,如授权只会在指定的时段内才会生效、当请求者从指定的IP地址发起请求时授权才会生效、或者只允许用户使用SQL(而不允许其它类型的Task)来访问某张表。
- Policy授权机制使用访问策略语言(Access Policy)来描述授权。策略语言目前支持20种访问条件(即从20个维度来限制对一张表的访问,例如访问来源IP地址)
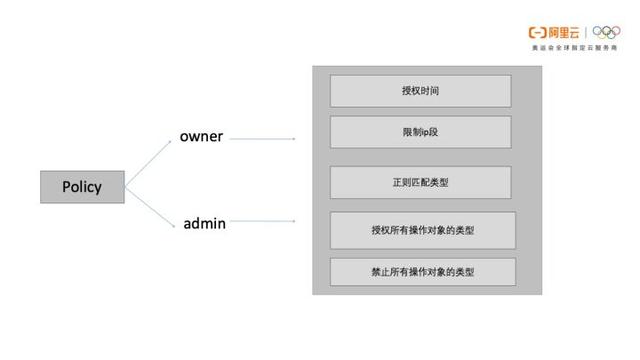
Policy结构和示例
当用户已经被赋予内置角色时,如果需要对用户的操作权限进行更精细化的管理,无法通过ACL权限控制方案解决此类授权问题。此时,可以通过Policy权限控制方案,新增角色,允许或禁止角色操作项目中的对象,并将角色绑定至用户后,即可实现精细化管控用户权限。
Policy支持的语法结构如下,可以对主体、行为、客体、条件、是否效果进行规则定义,例如对访问时间、访问ip进行限制。

ACL和Policy差异

LabelSecurity
前面两种权限控制方式(ACL和Policy)都属于DAC(即自主访问控制Discretionary Access Control)
基于标签的安全(LabelSecurity)是项目空间级别的一种强制访问控制策略(Mandatory Access Control, MAC),它的引入是为了让项目空间管理员能更加灵活地控制用户对列级别敏感数据的访问。
DAC vs MAC
------------------------
强制访问控制机制(MAC)独立于自主访问控制机制(DAC)。为了便于理解,MAC与DAC的关系可以用下面的例子来做个类比。
对于一个国家来说(类比一个项目),这个国家公民要想开车(类比读数据操作),必须先申请获得驾照(类比申请SELECT权限)。这些就属于DAC考虑的范畴。
但由于这个国家交通事故率一直居高不下,于是该国新增了一条法律:禁止酒驾。此后,所有想开车的人除了持有驾照之外,还必须不能喝酒。这个禁止酒驾就相当于禁止读取敏感度高的数据。这就属于MAC考虑的范畴。
LabelSecurity安全等级
- LabelSecurity需要将数据和访问数据的人进行安全等级划分。数据敏感等级取值范围为0~9。数值越大,安全级别越高。用户或角色最高可访问的敏感等级与数据敏感等级标签相对应。
- 在政府和金融机构的最佳实践中,一般将数据的敏感度标记分为四类:0级 (不保密, Unclassified), 1级 (秘密, Confidential), 2级 (机密, Sensitive), 3级 (高度机密, Highly Sensitive)。
- 在对数据和人分别设置安全等级标记之后,LabelSecurity的默认安全策略如下:
- (No-ReadUp) 不允许用户读取敏感等级高于用户等级的数据,除非有显式授权。
- (Trusted-User) 允许用户写任意等级的数据,新创建的数据默认为0级(不保密)。
- 租户中的LabelSecurity安全机制默认是关闭的,租户Owner可以自行开启。LabelSecurity安全机制一旦开启,上述的默认安全策略将被强制执行。当用户访问数据表时,除了必须拥有Select权限外,还必须获得读取敏感数据的相应许可等级。
比如下方用户A的Label是3级,用户有这张表的select权限,应该是可以查到这张表所有的数据,但开启 LabelSecurity之后,安全等级为4级的数据是访问不到的。

LabelSecurity应用场景
安全特性:
- 不允许用户读取敏感等级高于用户等级的数据(No-ReadUp),除非有显示授权
应用场景:
- 限制所有非Admin用户对一张表的某些敏感的列的读访问
实现逻辑:把Admin用户设置为最高等级,非Admin用户用户设置为某个普通等级(例如Label=2),那么除了Admin用户之外,其他所有人都访问不了 Label>2 的数据。
安全特性:
- 不允许用户写敏感等级不高于用户等级的数据(No-WriteDown)
应用场景:
- 限制已获得敏感数据访问许可的用户肆意传播和复制敏感数据
场景说明:张三由于业务需要而获得了等级为3的敏感数据的访问权限。但管理员仍然担心张三可能会将敏感等级为3的那些数据写入到敏感等级为2的列中,从而导致敏感等级为2的李四也能访问这份数据。
实现逻辑:将安全策略设置为 No-WriteDown,从而禁止张三将数据写入低于他自身等级的数据列
Package授权(跨项目的数据分享)
Package是一种跨项目空间共享数据及资源的机制,主要用于解决跨项目空间的用户授权问题。
- 当多个组织中的用户协同工作时,数据提供方不方便把其他项目的用户都加入自己的项目
- Package支持用户跨project,跨组织进行授权
- 数据提供方”打包授权后不管”
- Package优先级高于项目空间保护


管理package 安装package
管理package里面的资源 授权package的资源到本地用户角色
管理package的授权项目
数据提供者可以在创建、添加资源、授权可安装package项目的环节控制共享数据,数据消费方可以在安装package、首选package资源到本地用户角色环节,管理数据使用和权限。
MaxCompute其他安全能力再来看一下MaxCompute为了保证数据安全的其他平台级支撑能力。
防数据滥用包含:定期审计
防数据泄露包含:沙箱隔离、存储/传输加密
防数据丢失包含:备份恢复、容灾
系统安全--基于沙箱的纵深防御体系
MaxCompute中所有计算是在受限的沙箱中运行的,多层次的应用沙箱,从KVM级到Kernel级。系统沙箱配合鉴权管理机制,用来保证数据的安全,以避免出现内部人员恶意或粗心造成服务器故障。用户的业务进程是托管在MaxCompute引擎侧执行,所以权限会有隔离。但用户提交的UDF/MR程序可能会:
- 恶意耗尽集群资源(CPU, Memory, Network, Disk);
- 直接访问Pangu文件,窃取或篡改其他用户数据;
- 窃取Linux节点上飞天系统进程的敏感数据(如Tubo的capability);
- ......

MaxCompute不同于其他多租系统,会把用户代码放在外部环境中实现,然后通过接口对接。用户需要在其他环境中实现、调试、对接,自己保证并发、安全等。MaxCompute全托管模式可以让用户的私有代码通过沙箱环境,跑在MaxCompute的环境中,由MaxCompute实现并发和安全隔离,简单易用且完全自由的实现用户自定义的逻辑。
安全审计
MaxCompute 还提供精准的、细粒度的数据访问操作记录,并会长期保存。 MaxCompute平台体系所依赖的功能服务模块非常之多,我们可以把它称之为底层服务栈。对于数据操作记录来说, MaxCompute 会收集服务栈上的所有操作记录,从上层table/column级别的数据访问日志,一直到底层分布式文件系统上的数据操作日志。最底层分布式文件系统上处理的每一次数据访问请求,也都能追溯到MaxCompute哪个项目空间中的哪个用户的哪个作业发起的数据访问。日志包括task、tunnel、endpoint访问等操作,以及授权、label、package 等信息,详见元仓或information_schema。
公共云实时审计日志,事中预警、事后分析
完整记录用户在MaxCompute项目内的操作行为。

接入阿里云Action Trail服务: 查看检索 投递(日志/OSS)。
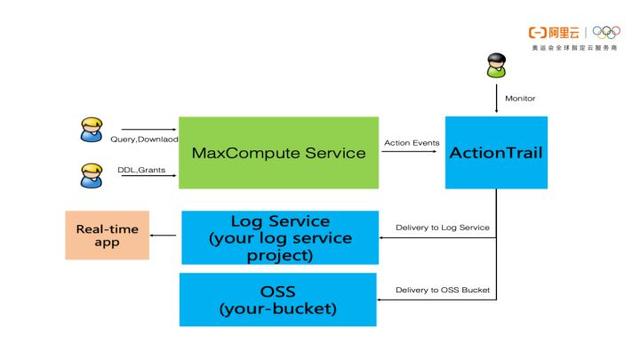
满足客户实时审计、问题回溯分析等需求。

存储加密和传输加密
传输加密 MaxCompute采用Restfull的接口,服务器接入采用https,其任务调用及数据传输安全性由https保证

存储加密 ,MaxCompute支持TDE透明加密,防拷贝。存储加密支持MC托管密钥,也支持基于KMS的BYOK(用户自定义密钥), 支持AES256等主流加密算法,专有云还支持国密算法SM4 。

备份恢复
MaxCompute持续备份功能,无需手工操作备份,自动记录备份每一次的DDL或DML操作产生的数据变化历史,可在需要时对数据恢复到特定历史版本。系统会自动备份数据的历史版本(例如被删除或修改前的数据)并保留一定时间,可以对保留周期内的数据进行快速恢复,避免因误操作丢失数据。该功能不依赖外部存储,系统默认为所有MaxCompute项目开放的数据保留周期为24小时,备份和存储免费,当项目管理员修改备份保留周期超过1天时,MaxCompute会对超过1天的备份数据按量计费。

容灾
公有云异地容灾
- 为 MaxCompute项目指定备份位置到备份集群后,自动实现主集群与备份集群的数据复制,达到主集群与被集群数据的一致,实现异地数据容灾。
- 故障切换时,MaxCompute项目从主集群切换到备份集群后,使用备份集群的计算资源访问备份集群的数据,完成服务的切换和恢复(fail over)。
- 目前用户还需要切换frontend和开通计算资源、以及容灾决策修改默认集群。
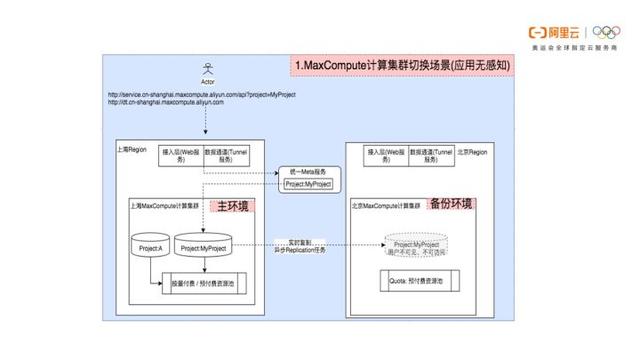
专有云容灾
- 适合金融级容灾备份场景
- 统一数据资源视图,统一权限管理模型,元数据近实时同步,数据定时同步,用户无感知
- MaxCompute平台内部做数据分布管理,大数据管家一键切换主备,业务不中断
- 由控制集群记录项目默认集群,主备模式也可利用备份集群的计算资源(1建议备集群缩容扩到主集群,2 在备集群容灾预留资源外创建非容灾单集群项目, 此类项目后续也不可改为容灾 )
- RPO依赖同步周期,RTO秒级或分钟级(受灾难决策影响)
- 注意复制链路的网络延迟(建议低于20ms) 和带宽(按需)要求

最后从应用安全的层次看一下DataWorks和MaxCompute结合带来的数据安全的能力。
防数据滥用包含:安全中心、授权审批
防数据泄露包含:数据脱敏
大数据平台全流程数据安全保障
大数据平台安全架构包含基础安全平台可信、MaxCompute大数据平台安全、应用安全。
本次分享主要是MaxCompute大数据平台安全能力,包括元数据管理、审计日志以及从采集、传输、存储、处理、交换、销毁这几方面来描述MaxCompute应用了哪些能来保障用户安全。
在引擎安全能力之上要有应用来配合才能在业务侧实现安全能力,包括权限的申请、敏感数据识别、访问统计等。

数据地图
数据地图是在元数据基础上提供的企业数据目录管理模块,涵盖全局数据检索、元数据详情查看、数据预览、数据血缘和数据类目管理等功能。数据地图可以更好地查找、理解和使用数据。

安全中心
DataWorks的安全中心,能够快速构建平台的数据内容、个人隐私等相关的安全能力,满足企业面向高风险场景的各类安全要求(例如,审计),无需额外配置即可直接使用该功能。
数据权限管理
安全中心提供精细化的数据权限申请、权限审批、权限审计等功能,实现了权限最小化管控,同时,方便查看权限审批流程各环节的进展,及时跟进处理流程。

数据内容安全管理
安全中心提供的数据分级分类、敏感数据识别、数据访问审计、数据源可追溯等功能,在处理业务流程的过程中,能够快速及时识别存在安全隐患的数据,保障了数据内容的安全可靠。
安全诊断的最佳实践
安全中心提供的平台安全诊断、数据使用诊断等功能,在符合安全规范要求的前提下,提供了诊断各类安全问题的最佳实践。保障业务在最佳的安全环境,更有效的执行。

数据保护伞
数据保护伞是一款数据安全管理产品,提供数据发现、数据脱敏、数据水印、访问控制、风险识别、数据审计、数据溯源等功能。
根据上文的分享,可以回答出之前四个方面的问题。
what
有什么数据? -- > 了解数据 及时清理
有什么用户? -- > 认证、租户隔离、项目空间保护
有什么权限? -- > 细粒度的权限管理、ACL/Policy/Role
where
数据在哪里? -- > 认证、租户隔离、项目空间保护
从哪里可以访问数据? -- > 沙箱隔离
数据能下载到哪里? -- > 网络隔离
who
谁能用数据? -- > 安全中心、授权审批
谁用了数据? -- > 定期审计、元数据/日志
whether
是否被滥用? -- > Label Security 分级管理
是否有泄露风险? -- > 数据脱敏
是否有丢失风险? -- > 备份恢复、容灾、存储/传输加密
原文链接:https://click.aliyun.com/m/1000351847/
本文为阿里云原创内容,未经允许不得转载。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com