一文读懂统一在线特征服务(一文读懂统一在线特征服务)

近年来,随着业界不断的创新和探索,机器学习在业务中承担的角色越来越重要。除了模型算法本身之外,良好的预测效果离不开特征的选择。从特征的来源看,通常可以分为3种类型:离线特征、在线特征和近实时特征本文中,我们主要聚焦于在线特征服务,介绍eBay AI平台是如何基于统一的特征元数据以及在特征工程中产生的特征数据,构建统一的特征服务能力。
背景与挑战随着AI相关技术的发展,线上模型预测在提升业务效果中扮演着越来越重要的角色。而线上预测离不开特征的快速准确获取。如果不能在较低SLA延迟下准确返回特征数据,后续的一切模型预测工作都无从谈起。
通常,业务线会根据自己的特征数据需求确定自己的特征获取方式。简单粗暴一点的,可能是直接读取数据库,更系统一些则会构建自己的特征服务去获取特征。但这种各自构建特征获取方式、缺乏统一特征服务管控的状况是我们不想看到的。重复构建无疑增加了开发和维护成本,也不利于后续的系统整合和业务演进。为此我们需要一套统一的特征服务去满足各个业务线丰富的业务需求。
当然,统一在线特征服务有许多挑战要克服:
- 多种特征类型的支持。正如前面文章中提到了,我们有离线特征,近实时特征以及embedding特征等不同的特征类型,我们需要有统一的接口去读取它们。
- 满足SLA要求。eBay内部多数业务线对特征服务的延迟要求为P99 20ms以内。
- 对于不同的业务线,需要有良好的访问隔离。不同业务线的实时性要求和流量大小可能不同,良好的访问隔离保证各业务线不会互相干扰。
- 灵活的配置变更和管理。不同的特征数据可能存储在不同的数据库中,并可能随时切换。特征读取或计算的并行度需要可以根据业务需求进行调整。所有这些可能的配置项需要暴露出来,并且能够在运行时进行切换。
为了应对在前面一节提到的多特征类型的统一访问接口支持,我们定义了一个概念:Eval Point(Evaluation Point)。
Eval Point定义了一组特征,这些特征可以包含任意的特征类型,他们组合在一起用于业务线某个特定的业务案例。在Eval Point的定义中,特征命名遵循以下命名规则:
{domain}:{variable type}:{feature group name}#{feature name}{^args (optional)}:{key name(s)}
以特征名risk:nrt:page_view#page_view_ count_userid^3d:BuyerId为例。#之前的字段定义该特征的一些元数据,比如它来自风控部门(risk),是近实时类型(nrt)的特征,包含在特征组page_view内。page_view_ count_userid则是实际的特征名称,而特征名之后则是参数。3d表示我们需要获得3天的页面访问数量。是谁的页面访问数量呢?最后的key name告诉我们,需要从服务请求payload里的BuyerId这个key里拿到用户id。
一组符合这个命名规则的特征构建起了一个Eval Point,后续特征的请求和计算都会围绕着Eval Point展开。
请求和返回格式
假设我们定义了一个名为risk_page_view的Eval Point,里面就就包含了我们刚才提到的page_view_ count_userid这个特征。则当我们需要获取特征时,其查询请求payload格式如下:
{
"requestId": "123",
"timeout": 2000,
"evalPoint": "risk_page_view",
"bestEffort": true,
"keys": {
"BuyerId": "id123456"
}
}
这些字段的含义是:
- requestId: 这个id由用户client端自行定义,比如包含timestamp或者其他业务相关信息。response结果会原样返回。这样,用户可以根据这个requestId进行后续的日志处理或者离线分析。
- timeout: 即最大执行时间,用户根据实际需要确定能够接受的最大执行时间。如果特征获取和计算超时,则立即返回。
- evalPoint: Eval Point名称,用于确定需要的特征。
- bestEffort: 这个参数用于控制计算出错时的表现。如果为false,如果特征获取出错,比如数据库没有查到、计算超时等,则返回错误信息。如果为true,则出错时,仍然会返回和正确时相同的response内容,但特征的值会给出默认值,并错误特征对应的错误码。
- keys: 特征需要的id,比如上面提到的page_view_ count_userid这个特征,根据命名规则需要BuyerId这个key,则它需要包含在keys中。
对应的,在请求执行正确,或者bestEffort为true的情况下,返回结果格式如下:
{
"requestId": "123",
"errorCount": 0,
"results": [{
"feature": "page_view_ count_userid^3d:BuyerId",
"value": 30,
"success": true
}]
}
其含义是:
- requestId: 如前述,返回结果的requestId和请求的一致。
- errorCount: 用户可以从此值快速判断请求的特征是不是全部成功。如果非零,则说明有特征出错。用户可以根据自己的需要来决定如何处理这些错误的特征。
- results: 是一个所有特征结果的数据,每个特征结果里包含几个字段。feature即为对应的特征名。value是特征的结果值,可能是正确计算得到的值,也可能是默认值。success为true或者false,表明这个特征是否正确获取。如果success为false,还会给出errorCode字段,用于告知错误原因。
results里的value支持任意的类型,比如基础数据类型的整数、浮点数、字符串,也可以包含数组和字典。涵盖了我们需要支持的离线特征、nrt近实时特征和embedding特征等所有特征类型。于此,我们确定了统一的访问接口和返回格式。
整体服务架构介绍完Eval Point以及统一的请求和结果格式,我们来看一下eBay统一在线特征服务的整体架构设计。其整体架构如下:
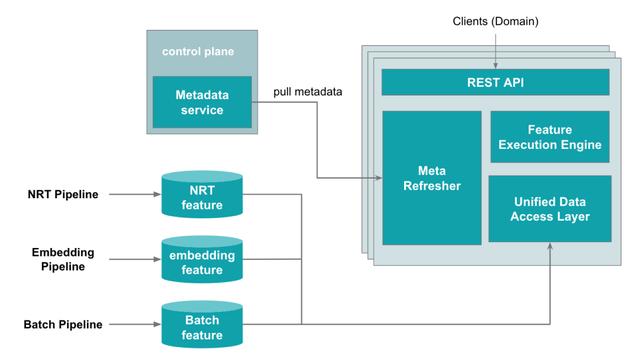
这里有几个主要组成部分:
- Meta Refresher: 前文(点击可跳转)已经介绍过中心化元数据的特征管理平台,在线特征服务的所有元数据定义也会从这个中心化元数据得来。为了简化流程,当前我们采用的是定期从元数据服务拉取的方式来刷新元数据。我们会判断元数据是否有变化,来决定是否需要重新对dsl进行编译或者对执行引擎进行更新。
- Unified Data Access Layer: 在我们遇到的挑战中我们提到,不同的特征可能存在不同的kv数据库中,以不同的存储格式来保存。我们抽象出一个统一的数据访问层,通过我们的元数据定义来决定如何来读取并解析这些数据。
- Feature Execution Engine:特征执行引擎则是整个服务最关键的组成部分,它封装了前文提到的DSL执行引擎,并可以基于元数据来控制以何种执行顺序、批处理大小、并行度等执行参数来获取特征。
- REST API: 保证对于所有的特征类型,都是统一的对外接口。
资源隔离
得益于eBay内部的云管理平台cloud,我们的服务可以快速进行多中心多实例部署。同时,cloud平台内有Pool的概念。同一个服务可以部署多个pool,并且每个pool内的资源相互独立。我们可以为各业务线创建单独的pool,从而到达资源隔离的效果。
数据共享与隔离
统一特征平台的其中一个重要目的就是方便大家共享和复用特征数据,所以我们默认会使用一个统一的enterprise level共享的kv数据库。但随着特征越来越多,共享数据库的流量越来越大,可能出现SLA不满足业务线要求的问题,则此时业务线会基于自身需求的考虑希望使用自己独立的数据库。
为了应对这一问题,首先在我们的特征工程端,pipeline支持特征多写,可以将同一份数据同时写入共享数据库和业务线独立数据库。而我们的在线特征服务,通过元数据配置我们可以指定特征从哪个数据库读取数据,同时得益于我们数据访问层的抽象以及eBay cloud平台多资源池的功能,我们可以保证业务线读取到独立数据库的数据并互不影响。
以这种方式,我们既能充分保证数据共享带来的便利性,同时又能兼顾业务线对访问性能、数据安全级别等方面的要求。
执行优化前面提到我们在线特征服务的所有计算都是围绕Eval Point展开的。下面介绍一下我们是如何基于Eval Point进行执行优化的。整个执行流程如下图所示,拆分成了如下几个阶段:

(点击可查看大图)
- 解析Eval Point定义,构建DAG: 一个Eval Point包含了多个特征的定义,而每个特征的定义里又有数据读取等UDF的定义。得益于DSL,我们能方便地把整个计算的依赖关系构建成一个DAG图。这一步,我们生成了原始的逻辑DAG (Raw Logical DAG)。
- DAG分析和优化:我们定义了一些规则,逻辑DAG可以基于这个规则进行优化,比如剪枝、合并节点等等,生成优化后的逻辑DAG (Optimized Logical DAG)。目的是为了减少计算冗余,保证后面实际执行阶段的性能。
- 生成物理执行计划:有了优化后的逻辑DAG后,我们就可以构建实际用于执行的物理执行计划了。逻辑DAG节点里主要包含的是执行需要的元数据,比如特征名称、需要访问哪个kv数据库等等。而物理执行计划的节点里则封装了实际的执行代码。
- 计算物理执行计划:最后,执行引擎接受物理执行计划以及请求的特征参数,在线程池中异步完成特征的获取和计算,并返回结果。
规则案例
这里我们举一个DAG优化的规则:kv数据库访问的Batching。
每一个Eval Point请求通常包含了多个特征,或者是Eval Point的batch请求需要拿到多个id对应的同一个特征。每个特征和id组都对应着kv数据库中的一行数据,如果我们每个特征都访问一次kv数据库,显然是相当低效的,所以我们需要将kv数据库访问batch化。下图展示了DAG优化前和优化后的变化。

左侧是我们优化前的DAG图。每个特征对应一个FeatureExec节点,包含了特征名(feature1)和对应的id(User1)等元信息。而它依赖于LoadVarExec节点,这个节点用于定义kv数据库读取数据相关的元信息,比如数据库名,实际的key等等。可见每个特征都对应一个kv数据库访问操作,如果直接这样映射到物理执行计划,那会比较低效。
右侧则是经过优化后的逻辑DAG图。我们把LoadVarExec节点合并到一起,同一个节点包含了多个需要的数据,这样我们可以数据库的bulk read api, 一次性从kv数据库拿到多条数据。
在实际使用中,我们对kv数据库访问的batch size可以根据业务需求进行一定的调优。我们当前默认batch size是5,即最多五个不同的LoadVarExec会合并成一个。如果超过5个,就会创建新的batch。比如有20个不同的特征,则优化后需要4次kv数据库访问。
Batch size也不宜设置得过大。因为如果过大,则单一请求的所有特征数据访问全部集中到同一个kv数据库后端节点,反而影响性能。合理的batch size设置能够将数据请求合理地分配给kv数据库集群,保证最佳的性能。这需要我们在实际业务场景中根据业务需要进行调整。
服务监控作为线上服务,自然离不了实时的服务监控来帮助我们及时发现并修复问题。在实际使用中,我们总结出主要2类指标:一类是服务性能指标,另一类则是元数据指标。
服务性能指标需要满足特定的SLA要求,比如端到端延迟P99不能高于20ms,错误率不能高于5%等等。主要包括:
- 请求的延迟,kv数据库访问延迟这些服务通用的指标。
- Eval Point相关的一些指标。比如特征访问的错误率,多数错误主要是key not found。
而元数据指标是为了监控元数据的正确性,保证线上服务永远使用的是正确的元数据。可能出现的元数据错误主要有:
- 特征的定义没有通过DSL编译,无法执行
- Eval Point的定义里包含了非法的特征,导致这个Eval Point对应的DAG无法构建
- Eval Point定义出现了无法向后兼容的变更
一旦出现这些元数据错误,如果当时已经有生产环境流量在服务,则可能严重影响生产环境的正常运行,所以必须及时发现和处理。
总结和展望本文主要介绍了eBay AI团队在统一在线特征服务建设方面的一些工作。目前统一在线特征服务已经初具雏形,多个业务线正在进行验证和整合。未来我们还会继续加强以下几个方面的能力:
- 统一的DAG执行引擎。当前DAG的执行还只限于特征服务,后续跟模型推理服务整合后可以构建更完整的从特征获取、模型推理到规则判断整个预测逻辑端到端的执行优化。
- 灵活的参数调优。当前许多执行参数还没有暴露给用户,无法根据具体的业务场景和需求进行调优。后续需要将这些参数暴露到元数据配置中,能够灵活修改和更新。
- 线上服务的监控管理优化。线上特征服务作为线上预测的关键组件之一,其SLA至关重要。包括dsl编译、执行、数据访问等环节都需要进行有效的监控和管理,保证能够及时发现问题并恢复。当前服务已经有了许多基础的指标metrics。但随着业务线的不断引入,还需要根据具体的业务需求加入更多监控指标。
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






