pytorch模型训练性能(提升大型工程编译速度的利器)
一直以来,预编译PCH文件都被证明是一个提升编译速度的好方法。通过PCH,可以在编译开始时仅包含头文件一次,这样避免了对某些经常会使用到的头文件的重复扫描,从而大大提升了编译速度,减少了整个工程的编译时间。
从传统的角度来说,将一个头文件选择作为预编译头文件有点像是一个猜谜语的游戏,你会觉得有些头文件应该被预编译,而有些在你看来不需要,并且,每个人对相同的头文件是否应该被预编译都有自己的看法。
在今天的文章中,我们将演示如何通过vcperf分析工具和C Build Insights SDK来找到那些需要被预编译的头文件。同时,我们还会以开源项目lrrlicht作为一个例子,通过对头文件进行有效的预编译,我们编译这个项目的速度有了40%的提升。
如何获取和使用vcperf在今天的例子中,我们使用到了vcperf。这是一个用来捕获编译信息的工具,并且可以在Windows Performance Analyzer(WPA)中查看这个编译信息。它的最新版本已经包含在了Visual Studio 2019 Preview版本中。
1. 下面是获取和配置vcperf和WPA的步骤:
1.1 下载并安装最新版本的Visual Studio 2019 Preview。
1.2 下载并安装最新版本的Windows ADK,里面包含有WPA。
1.3 将Visual Studio 2019 Preview的MSVC安装目录中的perf_msvcbuildinsights.dll拷贝至WPA目录。这个文件是C Build Insights WPA的插件,它必须对WPA可见,才能正确的显示C Build Insights事件。
a. MSVC的安装目录通常是:C:\Program Files (x86)\Microsoft Visual Studio\2019\Preview\VC\Tools\MSVC\{Version}\bin\Hostx64\x64
b. WPA的安装目录通常是:C:\Program Files (x86)\Windows Kits\10\Windows Performance Toolkit1.4 在WPA安装目录下打开perfcore.ini文件,添加一个perf_msvcbuildinsights.dll文件对应的条目。通过这个条目,我们可以告诉WPA在其启动时加载C Build Insights插件。
2. 下面是收集工程编译信息的步骤:
2.1 已管理员权限打开x64 Native Tools Command Prompt for VS 2019 Preview。
2.2 根据以下步骤获取工程编译信息:
a. 执行指令:[vcperf /start /level3 MySessionName]。/level3选项可以启用模板事件的收集。
b. 在系统的任意地方编译你的工程,甚至可以在Visual Studio中进行编译,因为vcperf会在整个系统范围收集事件信息。
c. 执行指令:[vcperf /stop /templates MySessionName outputFile.etl]。这条指令将会停止信息收集,并分析所有事件,包括模板事件,然后将分析后的结果保存到outputFile.etl文件中。
3. 在WPA中打开刚刚收集好的编译信息文件。
在WPA中查看头文件扫描信息C Build Insights提供了一个称之为Files的WPA视图,通过这个视图,我们可以清楚地看到编译器对整个工程中所有头文件扫描的时间。
在WPA中打开编译信息文件后,你可以在Graph Explorer窗格中拖动这个视图到Analysis窗口,如下图所示:

在这个视图中,最为重要的是Inclusive Duration和Count这两列,他们显示了对应的头文件的总体扫描时间和这个头文件被包含的次数。
案例研究:使用vcperf和WPA来为Irrlicht 3D引擎创建一个PCH在这个案例中,我们将演示如何使用vcperf和WPA来为Irrlicht这个开源项目创建一个PCH,并提升40%的编译速度。
具体的操作步骤如下:
1. 克隆Irrlicht工程仓库。
2. Checkout这个提交版本:97472da9c22ae4a。
3. 以管理员身份打开x64 Native Tools Command Prompt for VS 2019 Preview并导航到Irrlicht工程的根目录。
4. 执行指令:devenv /upgrade .\source\Irrlicht\Irrlicht15.0.sln。这条指令将会升级工程的解决方案文件升级到最新版本的MSVC。
5. 下载并安装DirectX SDK。这个SDK对于编译Irrlicht工程来说,是必须用用到的。
5.1 为了避免出现错误,你可能需要在安装DirectX SDK之前先卸载Microsoft Visual C 2010 x86 Redistributable和Microsoft Visual C 2010 x64 Redistributable。你可以在Windows 10的添加和删除程序中执行卸载操作,这两个组件会在安装DirectX SDK时重新被安装到系统中。
6. 获取Irrlicht的一份完整编译的追踪信息。在工程的根目录,执行如下指令:
6.1 vcperf /start Irrlicht。这条指令将会启动编译信息收集。
6.2 msbuild /m /p:Platform=x64 /p:Configuration=Release .\source\Irrlicht\Irrlicht15.0.sln /t:Rebuild /p:BuildInParallel=true。这条指令将会对Irrlicht工程进行重新编译。
6.3 vcperf /stop Irrlicht irrlicht.etl。这条指令将收集到的编译信息保存到irrlicht.etl这个文件中。
7. 在WPA中打开编译追踪信息。
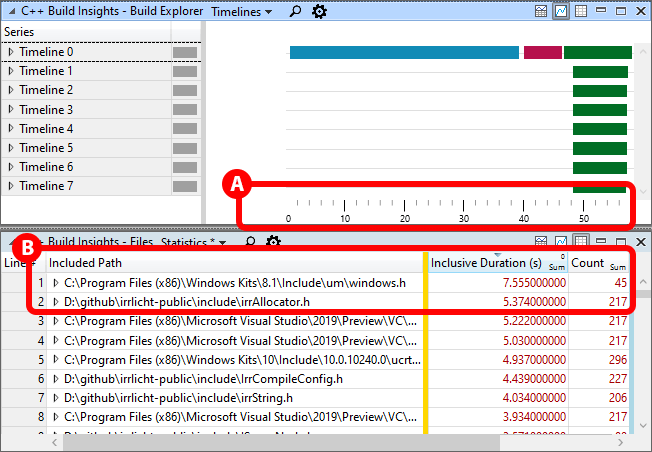
如下图所示的,我们打开了Build Explorer和Files视图。Build Explorer视图显示了整个编译时间为57秒,这一点可以在下图中的视图底部的时间轴看出来(下图中的A)。
Files视图则显示了耗费了最多扫描时间的头文件,它们分别是Windows.h和irrAllocator.h(下图中的B)。它们分别被扫描了45次和217次。
在下图中,我们可以看到这些头文件是在哪些文件中被包含的,它们显示在Files视图的IncludedBy字段。

首先,我们在工程的根目录下创建一个pch.h的文件。这个头文件将包含我们需要放入到预编译中的头文件,然后会被Irrlicht工程中的所有的C或者C 源文件所包含。当编译C 时,我们只会添加irrAllocator.h,因为它不兼容C。如下图所示:

PCH在使用之前必须被编译过一次。因为Irrlicht工程包含C和C 这两种文件,所以我们需要创建两个版本的PCH文件。通过在工程的根目录下添加pch-cpp.cpp和pch-c.c这两个源文件,我们就可以创建这两个版本的PCH。这两个源文件只会包含我们之前创建好的pch.h头文件。如下图所示:

在Visual Studio中,我们需要修改pch-cpp.cpp和pch-c.c这两个头文件的Precompiled Headers属性的值,这会告诉Visual Studio创建两个不同版本的PCH文件。如下图所示:

然后,我们还需要修改Irrlicht工程的Precompiled Headers属性。这会告诉Visual Studio使用我们之前编译好的C 版本的PCH文件。如下图所示:

对于工程中所有的C源文件,我们也需要对应地修改其Precompiled Headers属性。这会告诉Visual Studio在编译这些C源文件时,使用C版本的PCH。如下图所示:

为了使用我们创建的PCH,我们需要在所有的C和C 源文件中包含pch.h这个头文件。为了简单起见,我们在Irrlicht工程的Advanced C/C properties属性中使用到了/FI编译开关。这会使得pch.h被自动包含到每一个源文件中,即使它没有通过#include预编译指令进行显式包含。如下图所示:

为了成功的编译引入了PCH之后的Irrlicht工程,需要做下面的两个小改动:1. 在整个工程级别添加预处理宏HAVE_BOOLEAN。2. 在两个文件中取消对far preprocessor的定义。
评估最终结果在创建了PCH之后,我们收集了Irrlicht完整重新编译的信息。我们注意到,总体编译时间由57秒下降到了35秒,也即有了近40%的提升。同时,我们还发现,之前提到的Windows.h和irrAllocator.h这两个头文件已经不再显示在头文件扫描列表的顶部了。如下图所示:

在vcperf和WPA中执行的大部分分析任务都可以使用C Build Insights SDK以程序化的方式进行。我们准备了一个示例工程TopHeaders,它会显示最多被扫描的头文件和它们各自占前端编译总时间的占比。它还显示出每个头文件被包含到编译单元中的次数。
这次,让我们再次回顾之前的研究案例,不过这次,我们是使用TopHeaders这个示例工程。具体步骤如下:
1. 克隆C Build Insights SDK Samples仓库。
2. 编译Samples.sln解决方案,编译目标平台为x86或者x64,使用debug或者release配置。示例工程生成的二进制文件将会位于out/{architecture}/{configuration}/TopHeaders目录。
3. 根据之前的案例研究中的步骤对收集工程编译的信息。使用vcperf /stopnoanalyze Irrlicht irrlicht-raw.etl,而不是/stop来停止信息收集。这个操作将会生成一个能被SDK处理的原始编译信息文件。
4. 将irrlicht-raw.etl作为第一个参数传递给TopHeaders可执行文件。
如下图所示,TopHeaders将会正确的显示出Windows.h和irrAllocator.h这两个文件占用了最长的扫描时间。同时,我们还看到它们分别被包含了45次和217次,这和我们之前在WPA中看到的结果是一致的。

如果将我们修改过的(添加了PCH)工程提交给TopHeaders,则会显示出Windows.h和irrAllocator.h这两个头文件不再是主要的瓶颈问题。同时,我们也观察到有一些其他的头文件也在列表中消失了。这些头文件之前被irrAllocator.h所引用,进而被预编译到了PCH中。

首先,我们过滤掉了所有的停止活动事件,只保留了前端文件和前端扫描事件。然后,我们请求C Build Insights SDK来为我们展开前端文件的事件堆栈。这可以通过调用MatchEventStackInMemberFunction来实现,它会从事件堆栈中抓取匹配TopHeaders::OnStopFile签名的事件。当我们得到一个前端扫描事件时,我们就可以简单直接地追踪到总体的扫描时间了。

我们使用到了OnStopFile这个函数来汇总每个头文件的扫描时间到[std::unordered_map fileInfo_]结构体。同时,我们还会追踪每个包含头文件的编译单元的次数,包括被包含头文件的路径信息。

在分析的最后,我们打印出我们手机的有关头文件的信息,包括那些占用最多扫描时间的头文件列表。

随着工程规模的增加,编译时间越来越成为开发者一个头痛的问题。
善用PCH,有助于降低编译的时间,让你觉得生命中还是有那么一些美好的东西的。

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com