etl调度是什么 调度工具ETL任务流
kettle是一个ETL工具,ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)。kettle中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。所以他的重心是用于数据oozie是一个工作流,Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。oozie工作流中是有数据流动的,但是重心是在于工作流的定义。二者虽然都有相关功能及数据的流动,但是其实用途是不一样的。
2.ETL作业调度工具2.1Sqoop调度工具2.1.1列举出所有数据库查看帮助
bin/sqoop help
列举出所有linux上的数据库
bin/sqoop list-databases --connect jdbc:mysql://localhost:3306 --username root --password root
列举出所有Window上的数据库
bin/sqoop list-databases --connect jdbc:mysql://192.168.22.36:3306 --username root --password root
查看数据库下的所有表
bin/sqoop list-tables --connect jdbc:mysql://localhost:3306/mysql --username root --password root
(1)确定mysql服务启动正常
查询控制端口和查询进程来确定,一下两种办法可以确认mysql是否在启动状态
办法1:查询端口
$ netstat -tulpn
MySQL监控的TCP的3306端口,如果显示3306,证明MySQL服务在运行中
办法二:查询进程
可以看见mysql的进程
ps -ef | grep mysqld
没有指定数据导入到哪个目录,默认是/user/root/表名
bin/sqoop import \
--connect jdbc:mysql://192.168.77.137/zhjy \
--password 123456 \
--username root \
--table zf_jygz_thjc \
--m 1 \
--fields-terminated-by '\t'
或是
bin/sqoop import \
--connect jdbc:mysql://192.168.77.137/zhjy \
--password 123456 \
--username root \
--table zf_jygz_thjc \
--m 5 \
--split-by ZF_BH(一般在设置-m>1时使用)
--fields-terminated-by '\t'
原因:
如果表中有主键,m的值可以设置大于1的值;如果没有主键只能将m值设置成为1;或者要将m值大于1,需要使用--split-by指定一个字段
设置了-m 1 说明只有一个maptask执行数据导入,默认是4个maptask执行导入操作,但是必须指定一个列来作为划分依据
导入数据到指定目录
在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。使用参数 --target-dir来指定导出目的地,使用参数—delete-target-dir来判断导出目录是否存在,如果存在就删掉
bin/sqoop import \
--connect jdbc:mysql://192.168.77.137/zhjy \
--username root \
--password 123456 \
--delete-target-dir \ --如果目录存在,将目录删除
--table zf_jygz_thjc \
--target-dir /user/zhjy \ --指定保存目录
--m 1 \
--fields-terminated-by '\t'
查询导入
bin/sqoop import \
--connect jdbc:mysql://192.168.72.133:3306/company \
--username root \
--password root \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'select name,sex from staff where id <=1 and $CONDITIONS;'
提示:must contain '$CONDITIONS' in WHERE clause。
where id <=1 匹配条件
$CONDITIONS:传递作用。
如果 query 后使用的是双引号,则 $CONDITIONS前必须加转义符,防止 shell 识别为自己的变量。
--query时不能使用--table一起使用
需要指定--target-dir路径
导入到hdfs指定目录并指定要求
bin/sqoop import \
--connect jdbc:mysql://192.168.72.133:3306/company \
--username root \
--password root\
#提高数据库到hadoop的传输速度
--direct
--table staff \
--delete-target-dir \
#导入指定列,涉及到多列,用逗号分隔
--column id,sex \
--target-dir /user/company \
--num-mappers 1 \
#指定分隔符
--fields-terminated-by '\t'
#指定导出存储格式
--as-textfile
#指定数据压缩(压缩,解压缩方式)
--compress
--compression-codec org.apache.hadoop.io.compress.SnappyCodec
数据导出储存方式(数据存储文件格式---( textfil parquet)--as-textfileImports data as plain text (default)--as-parquetfile Imports data to Parquet Files)
导入表数据子集到HDFS
bin/sqoop import \
--connect jdbc:mysql://172.16.43.67:3306/userdb \
--username root \
--password root \
--table emp_add \
--target-dir /sqoop/emp_add \
-m 1 \
--delete-target-dir \
--where "city = 'sec-bad'"
sqoop导入BLOB数据到Hive
对于CLOB,如xml文本,sqoop可以迁移到Hive表,对应字段存储为字符类型。对于BLOB,如jpg图片,sqoop无法直接迁移到Hive表,只能先迁移到HDFS路径,然后再使用Hive命令加载到Hive表。迁移到HDFS后BLOB字段存储为16进制形式。
bin/sqoop-import \
--connect jdbc:mysql://192.168.77.137:3306/zhjy \
--username root \
--password 123456 \
--table ceshi \
--columns "id,name,photo" \
--split-by id \
-m 4 \
--inline-lob-limit=16777126 \设置内联的LOB对象的大小
--target-dir /user/hive/warehouse/ods.db/ceshi
2.1.3导入关系表到Hive
第一步:导入需要的jar包
将我们mysql表当中的数据直接导入到hive表中的话,我们需要将hive的一个叫做hive-exec-1.1.0-cdh5.14.0.jar的jar包拷贝到sqoop的lib目录下
cp /export/servers/hive-1.1.0-cdh5.14.0/lib/hive-exec-1.1.0-cdh5.14.0.jar /export/servers/sqoop-1.4.6-cdh5.14.0/lib/
第二步:开始导入
day=`date -d "yesterday" %Y%m%d`
sqoop import \ --导入数据
--connect jdbc:mysql://10.2.111.87:3306/ehl_apmp \ --连接url
--username root \ --用户名
--password root \ --密码
--table zf_jygz_thjc \ --要导入的表
-m 1 \ --maptask
--hive-drop-import-delims \ --导入时删除数据库中特殊字符
--hive-overwrite \ --覆盖导入
--hive-import \ --导入到hive表中
--hive-database ods \ --导入到hive中哪个数据库
--hive-table ods_zf_jygz_thjc \ --导入到hive中哪个表
--fields-terminated-by '\t' \ --字段分隔符
--lines-terminated-by '\n' --指定行分隔符
--null-string '\\N' \ --字符串类型为null是代替字符
--null-non-string '\\N' \ --字非符串类型为null是的代替字符
--hive-partition-key day \ --hive表的分区字段
--hive-partition-value "$day" --指定导入表的分区值
导入关系表到hive并自动创建hive表
们也可以通过命令来将我们的mysql的表直接导入到hive表当中去
sqoop import --connect jdbc:mysql://10.2.111.87:3306/ehl_apmp \
--username root --password root \
--table $1 \
--hive-import \
--hive-database ods \
--create-hive-table \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '\\N' \
--split-by code \
-m 4
通过这个命令,我们可以直接将我们mysql表当中的数据以及表结构一起倒入到hive当中去
2.1.4增量导入--incremental<mode> 增量模式。
Append id 是获取一个某一列的某个值。
lastmodified “2016-12-15 15:47:35” 获取某个时间后修改的所有数据
-append 附加模式
-merge-key id 合并模式
--check-column<column name> 用来指定一些列,可以去指定多个列;通常的是指定主键id
--last -value<last check column value> 从哪个值开始增量
==注意:增量导入的时候,一定不能加参数--delete-target-dir 否则会报错==
第一种增量导入方式(不常用)
1.append方式
使用场景:有个订单表,里面每个订单有一个唯一标识的自增列id,在关系型数据库中以主键的形式存在。之前已经将id在0-1000之间的编号的订单导入到HDFS 中;如果在产生新的订单,此时我们只需指定incremental参数为append,--last-value参数为1000即可,表示只从id大于1000后开始导入。
(1)创建一个MySQL表
CREATE TABLE orders(
o_id INT PRIMARY KEY AUTO_INCREMENT,
o_name VARCHAR(255),
o_price INT
);
INSERT INTO orders(o_id,o_name,o_price) VALUES(1,'联想',5000);
INSERT INTO orders(o_id,o_name,o_price) VALUES(2,'海尔',3000);
INSERT INTO orders(o_id,o_name,o_price) VALUES(3,'雷神',5000);
INSERT INTO orders(o_id,o_name,o_price) VALUES(4,'JACK JONES',800);
INSERT INTO orders(o_id,o_name,o_price) VALUES(5,'真维斯',200);
(2)创建一个hive表(表结构与mysql一致)
bin/sqoop import \
--connect jdbc:mysql://192.168.22.30:3306/userdb \
--username root \
--password root \
--table emp \
--target-dir /sqoop/increment \
--num-mappers 1 \
--incremental append \
--check-column id \
--last-value 1202
注意:
append 模式不支持写入到hive表中
2.lastModify方式
此方式要求原有表有time字段,它能指定一个时间戳,让sqoop把该时间戳之后的数据导入到HDFS;因为后续订单可能状体会变化,变化后time字段时间戳也会变化,此时sqoop依然会将相同状态更改后的订单导入HDFS,当然我们可以只当merge-key参数为order-id,表示将后续新的记录和原有记录合并。
# 将时间列大于等于阈值的数据增量导入HDFS
sqoop import \
--connect jdbc:mysql://192.168.xxx.xxx:3316/testdb \
--username root \
--password transwarp \
--query “select order_id, name from order_table where \$CONDITIONS” \
--target-dir /user/root/order_all \
--split-by id \
-m 4 \
--incremental lastmodified \
--merge-key order_id \
--check-column time \
# remember this date !!!
--last-value “2014-11-09 21:00:00”
使用 lastmodified 方式导入数据,要指定增量数据是要 --append(追加)还是要 --merge-key(合并)last-value 指定的值是会包含于增量导入的数据中。
第二种增量导入方式(推荐)
==通过where条件选取数据更加精准==
yesterday=`date -d "yesterday" %Y_%m_%d`
where="update_time >= \"${yesterday}""
day=`date -d "yesterday" %Y-%m-%d`
sqoop import \ --导入数据
--connect jdbc:mysql://10.2.111.87:3306/ehl_apmp \ --连接url
--username root \ --用户名
--password root \ --密码
--table zf_jygz_thjc \ --要导入的表
-m 1 \ --maptask
--hive-drop-import-delims \ --导入时删除数据库中特殊字符
--hive-overwrite \ --覆盖导入
--hive-import \ --导入到hive表中
--hive-database ods \ --导入到hive中哪个数据库
--hive-table ods_zf_jygz_thjc \ --导入到hive中哪个表
--fields-terminated-by '\t' \ --字段分隔符
--lines-terminated-by '\n' --指定行分隔符
--columns 'zf_bh,zf_xm' \ --导入的字段(可选)
--where "${where}" \ --条件导入
--null-string '\\N' \ --字符串类型为null是代替字符
--null-non-string '\\N' \ --字非符串类型为null是的代替字符
--hive-partition-key day \ --hive表的分区字段
--hive-partition-value "$day" --指定导入表的分区值
2.1.5从RDBMS到hbase
bin/sqoop import
--connect jdbc:mysql://192.168.22.30:3306/userdb \
--username root \
--password root \
--table emp \
--columns "id,name,sex" \
--column-family "info"
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_test" \
--split-by id \
--num-mappers 1
会报错
原因:sqoop1.4.6 只支持 HBase1.0.1 之前的版本的自动创建 HBase 表的功能。
解决方案:手动创建 HBase 表
hbase> create 'hbase_staff','info'
导出前,目标表必须存在与目标数据库中
默认操作是将文件中的数据使用insert语句插入到表中
数据是在HDFS当中的如下目录/sqoop/emp,数据内容如下
1201,gopal,manager,50000,TP,2018-06-17 18:54:32.0,2018-06-17 18:54:32.0,1
1202,manisha,Proof reader,50000,TP,2018-06-15 18:54:32.0,2018-06-17 20:26:08.0,1
1203,khalil,php dev,30000,AC,2018-06-17 18:54:32.0,2018-06-17 18:54:32.0,1
1204,prasanth,php dev,30000,AC,2018-06-17 18:54:32.0,2018-06-17 21:05:52.0,0
1205,kranthi,admin,20000,TP,2018-06-17 18:54:32.0,2018-06-17 18:54:32.0,1
第一步:创建MySQL表
CREATE TABLE `emp_out` (
`id` INT(11) DEFAULT NULL,
`name` VARCHAR(100) DEFAULT NULL,
`deg` VARCHAR(100) DEFAULT NULL,
`salary` INT(11) DEFAULT NULL,
`dept` VARCHAR(10) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=utf8;
第二步:执行导出命令
通过export来实现数据的导出,将hdfs的数据导出到mysql当中去
全量导出
bin/sqoop export \
--connect jdbc:mysql://172.16.43.67:3306/userdb \
--username root \
--password admin \
--table emp_out \
--export-dir /sqoop/emp \
--columns id,name \(当文件数据与表结构一致时,可以不指定)
--input-fields-terminated-by ","
增量导出
bin/sqoop export \
--connect jdbc:mysql://192.168.77.137:3306/zhjy \
--username root \
--password 123456 \
--table emp_out \
--update-key id \
--update-mode allowinsert \(新增的数据被导出)
--export-dir '/user/hive/warehouse/ods_ceshi/part-m-00000' \
--input-null-string '\\N' \
--input-null-non-string '\\N' \
--input-fields-terminated-by ',' \
-m 1
更新导出
bin/sqoop export \
--connect jdbc:mysql://192.168.77.137:3306/zhjy \
--username root \
--password 123456 \
--table emp_out \
--update-key id \
--update-mode updateonly \(只能导出修改后的数据,不能导出新增的数据)
--export-dir '/user/hive/warehouse/ods_ceshi/part-m-00000' \
--input-null-string '\\N' \
--input-null-non-string '\\N' \
--input-fields-terminated-by ',' \
-m 1
总结:
参数介绍--update-key 后面也可以接多个关键字列名,可以使用逗号隔开,Sqoop将会匹配多个关键字后再执行更新操作。--export-dir 参数配合--table或者--call参数使用,指定了HDFS上需要将数据导入到MySQL中的文件集目录。--update-mode updateonly和allowinsert。 默认模式为updateonly,如果指定--update-mode模式为allowinsert,可以将目标数据库中原来不存在的数据也导入到数据库表中。即将存在的数据更新,不存在数据插入。组合测试及说明1、当指定update-key,且关系型数据库表存在主键时:A、allowinsert模式时,为更新目标数据库表存的内容,并且原来不存在的数据也导入到数据库表;B、updateonly模式时,为更新目标数据库表存的内容,并且原来不存在的数据也不导入到数据库表;2、当指定update-key,且关系型数据库表不存在主键时:A、allowinsert模式时,为全部数据追加导入到数据库表;B、updateonly模式时,为更新目标数据库表存的内容,并且原来不存在的数据也不导入到数据库表;3、当不指定update-key,且关系型数据库表存在主键时:A、allowinsert模式时,报主键冲突,数据无变化;B、updateonly模式时,报主键冲突,数据无变化;4、当不指定update-key,且关系型数据库表不存在主键时:A、allowinsert模式时,为全部数据追加导入到数据库表;B、updateonly模式时,为全部数据追加导入到数据库表;
实际案例:
(1)mysql批量导入hive
#!/bin/bash
source /etc/profile
num=0
list="table1 table2 table3"
for i in $list; do
echo "$sum"
echo "$i"
echo "sqoop开始批量导入......"
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table person --hive-table db.$i --delete-target-dir --hive-overwrite --hive-import &
num=$(expr $num 1)
if [$sum -gt 4 ]; then
{
echo "等待批量任务完成"
wait
echo "开始下一批导入"
num = 0
}
fi
done
echo "等待最后一批任务完成"
wait
echo "全部导入完成"
使用shell脚本:
#!/bin/sh
export SQOOP_HOME=/usr/share/sqoop-1.4.4
hostname="192.168.1.199"
user="root"
password="root"
database="test"
table="tags"
curr_max=0
function db_to_hive(){
${SQOOP_HOME}/bin/sqoop import
--connect jdbc:mysql://${hostname}/${database} \
--username ${user} \
--password ${password} \
--table ${table} \
--split-by docid \
--hive-import \
--hive-table lan.ding
--fields-terminated-by '\t' --incremental append --check-column docid --last-value ${curr_max}
result=`mysql -h${hostname} -u${user} -p${password} ${database}<<EOF
select max(docid) from ${table};
EOF`
curr_max=`echo $result |awk '{print $2}'`
}
if [ $# -eq 0 ];then
while true
do
db_to_hive
sleep 120
done
exit
fi
笔者目前用sqoop把mysql数据导入到Hive中,最后实现命令行导入,sqoop版本1.4.7,实现如下
sqoop job --import --connect jdbc:mysql://10.4.20.93:3303 \
--username user \
--password 123456 \
--query "select user_name ,user_id,identype from users where $CONDITIONS" \
--hive-import \
--hive-database haibian_odbc \
--hive-table users \
--split-by id \
--fields-terminated-by '\01' \
--lines-terminated-by '\n' \
--target-dir /user/hive/tmp/users \
--hive-delims-replacement ' ' --incremental append \
--check-column id \
--last-value 0
最后需要把这个导入搞成job,每天定时去跑,实现数据的自动化增量导入,sqoop支持job的管理,可以把导入创建成job重复去跑,并且它会在metastore中记录增值,每次执行增量导入之前去查询
创建job命令如下
sqoop job --create users -- import --connect jdbc:mysql://10.4.20.93:3303 \--username user \--password 123456 \--query "select user_name ,user_id,identype from users where $CONDITIONS" \--hive-import \--hive-database haibian_odbc \--hive-table users \--split-by id \--fields-terminated-by '\01' \--lines-terminated-by '\n' \--target-dir /user/hive/tmp/users \--hive-delims-replacement ' ' --incremental append \--check-column id \--last-value 0
创建完job就可以去执行它了
sqoop job --exec users
可以把该指令设为Linux定时任务,或者用Azkaban定时去执行它
shell脚本循环遍历日期,用于sqoop脚本
#! /bin/bash
first="$1"
second="$2"
while [ "$first" != "$second" ]
do
date=`date -d "$first" "%Y-%m-%d"`
sqoop export \
--connect jdbc:mysql:// \
--username \
--password \
--table dwd_fact_front_orderinfo \
--export-dir /user/hive/warehouse/dwd.db/dwd_fact_front_orderinfo/day="$date" \
--input-null-non-string '\\N' \
--input-null-string '\\N' \
--input-fields-terminated-by "\t" \
--update-key id \
--update-mode allowinsert \
--m 1;
let first=`date -d "-1 days ago ${first}" %Y%m%d`
done
hive导出到MySQL时,date类型数据发生变化?
问题原因:时区设置问题,date -R查看服务器时间,show VARIABLES LIKE "%time_zone"查看Mysql时间,system并不表示中国的标准时间,要将时间设置为东八区
set global time_zone = ' 08:00';
set time_zone = ' 08:00';
flush privileges;
(1):对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,ooize相比azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错的候选对象。
(2):功能:
两者均可以调度mapreduce,pig,java,脚本工作流任务;
两者均可以定时执行工作流任务;
(3):工作流定义:
Azkaban使用Properties文件定义工作流;
Oozie使用XML文件定义工作流;
(4):工作流传参:
Azkaban支持直接传参,例如${input};
Oozie支持参数和EL表达式,例如${fs:dirSize(myInputDir)};
(5):定时执行:
Azkaban的定时执行任务是基于时间的;
Oozie的定时执行任务基于时间和输入数据;
(6):资源管理:
Azkaban有较严格的权限控制,如用户对工作流进行读/写/执行等操作;
Oozie暂无严格的权限控制;
(7):工作流执行:
Azkaban有两种运行模式,分别是solo server mode(executor server和web server部署在同一台节点)和multi server mode(executor server和web server可以部署在不同节点);
Oozie作为工作流服务器运行,支持多用户和多工作流;
(8):工作流管理:
Azkaban支持浏览器以及ajax方式操作工作流;
Oozie支持命令行、HTTP REST、Java API、浏览器操作工作流;
3.2 Azkaban调度工具3.1.1启动solo-server
cd /export/servers/azkaban-solo-server-0.1.0-SNAPSHOT
bin/start-solo.sh
浏览器页面访问
http://node03:8081/
3.3 Oozie调度工具使用Oozie时通常整合hue,用户数据仓库调度
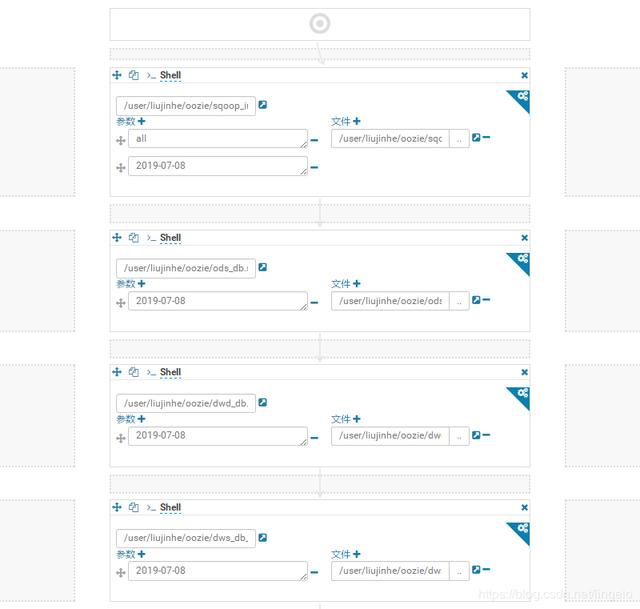
3.3.1数仓流程说明
大致流程:
MySQL -> HDFS -> ODS -> DWD -> DWS -> ADS -> MySQL
具体流程:
1. MySQL业务通过Sqoop数据导入HDFS
2. 将HDFS数据导入Hive数仓ODS层
3. 将ODS数据简单清洗写入DWD层
4. 将DWD数据轻度汇总写入DWS层宽表
5. 将DWS层数据统计结果写入ADS层
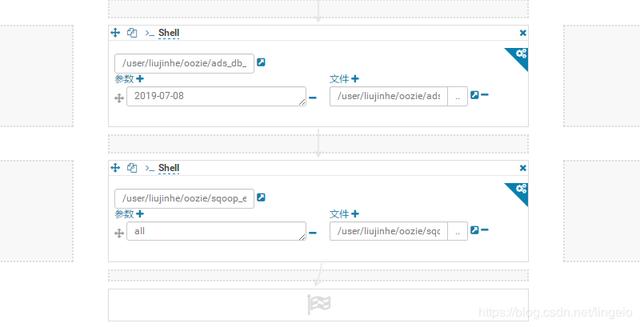
6. 将ADS层数据通过Sqoop导出到MySQL汇总表



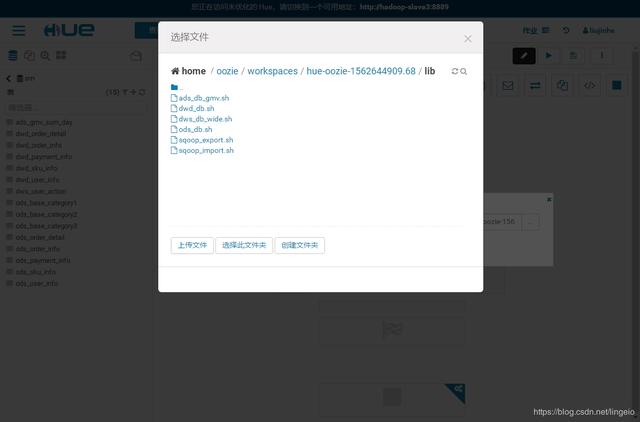

就是刚才选择的脚本
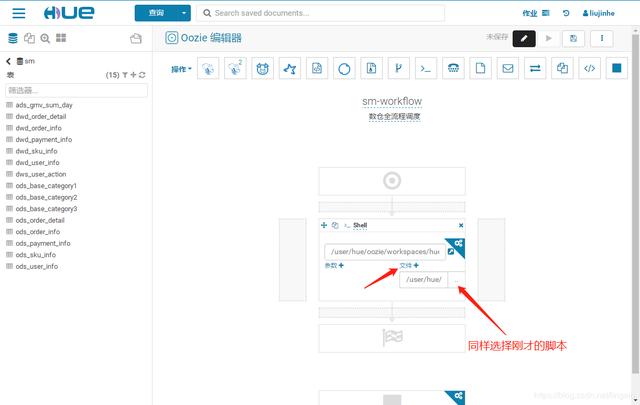
脚本里需要的参数,尽量设置为动态自动获取,如 ${date}
第一步的参数是所有文件和当天日期,后面的只需要日期,最后一步是导出所有结果,相应填入

添加文件和设置相应参数

运行后会有状态提示页面,可以看到任务进度


点击调度任务的页面情况


修改定时任务名和描述

添加需要定时调度的任务
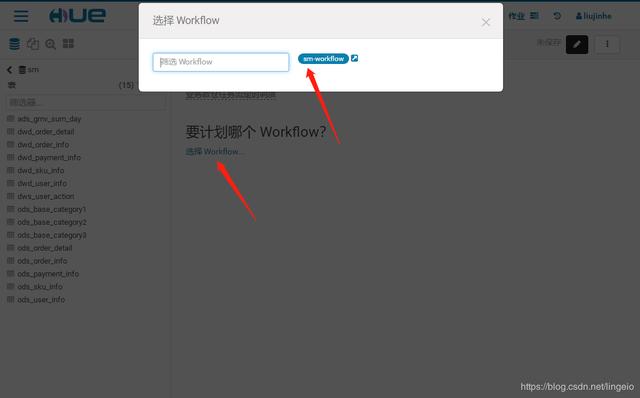
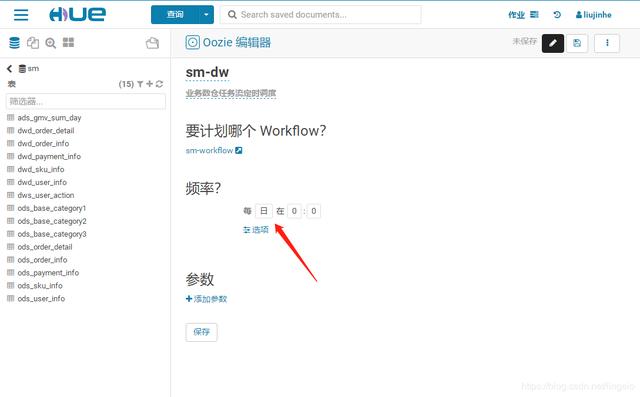

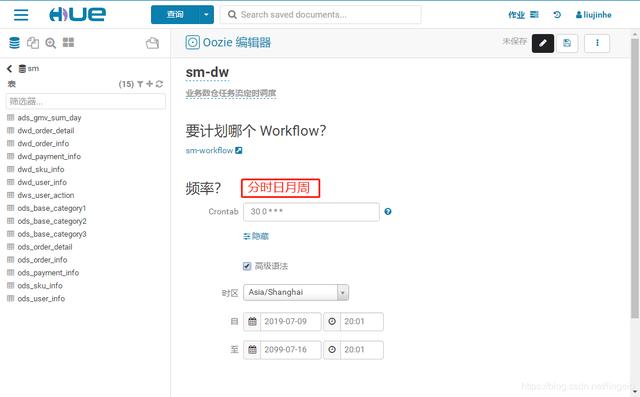

sm-workflow的参数都是写死的,没有设置动态,这里的下拉列表就不会有可选项。

设置参数
将sm-workflow的日期修改为 ${do_date},保存
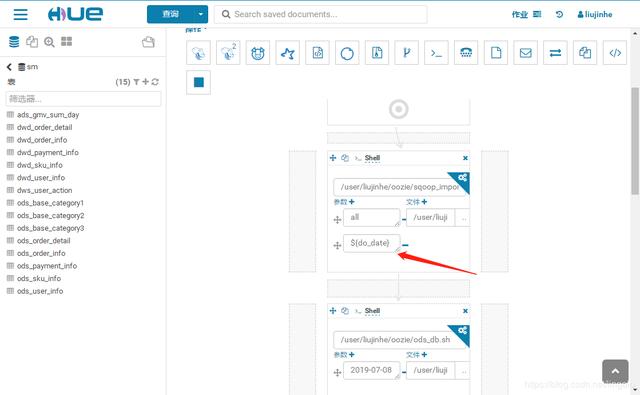
进入定时计划sm-dw中,会看到有参数 do_date
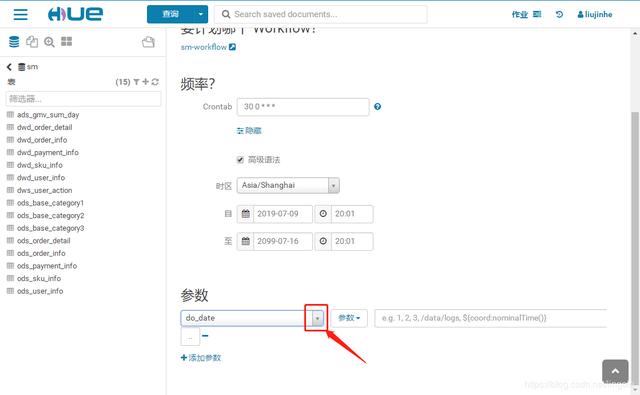

填入相应参数,前一天日期
${coord:formatTime(coord:dateOffset(coord:nominalTime(), -1, ‘DAY’), ‘yyyyMMdd’)}

Oozie常用系统常量
当然,也可以通过这样将参数传入workflow任务中,代码或者shell中需要的参数。
如,修改sm-workflow 中的 sqoop_import.sh,添加一个参数 ${num}。
编辑文件(需要登陆Hue的用户有对HDFS操作的权限),修改shell中的一个值为参数,保存。



在workflow中,编辑添加参数 ${num} ,或者num=${num} 保存。

进入schedule中,可以看到添加的参数,编辑输入相应参数即可。

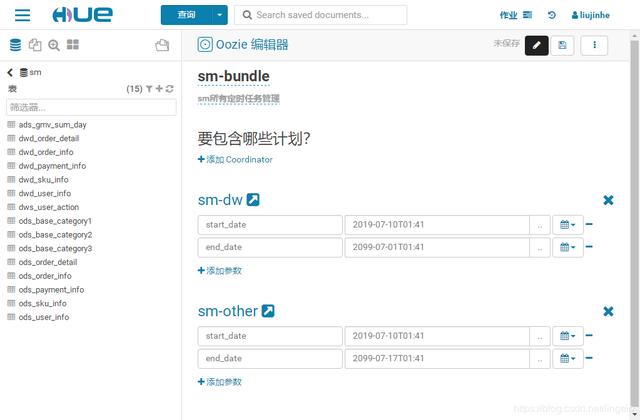
Bundle统一管理所有定时调度,阶段划分:Bundle > Schedule > workflow


免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com