python3.8.5零基础入门教程(Python3入门)
接着上篇接着讲,如需要看上篇的朋友下方了解更多,跳转
列表(list)
- 列表是一种无序的、可重复的数据序列,可以随时添加、删除其中的元素。
- 列表页的每个元素都分配一个数字索引,从 0 开始
- 列表使用方括号创建,使用逗号分隔元素
- 列表元素值可以是任意类型,包括变量
- 使用方括号对列表进行元素访问、切片、修改、删除等操作,开闭合区间为[)形式
- 列表的元素访问可以嵌套
- 方括号内可以是任意表达式
创建列表
hello = (1, 2, 3)
li = [1, "2", [3, 'a'], (1, 3), hello]
访问元素
li = [1, "2", [3, 'a'], (1, 3)]
print(li[3]) # (1, 3)
print(li[-2]) # [3, 'a']
切片访问
格式: list_name[begin:end:step] begin 表示起始位置(默认为0),end 表示结束位置(默认为最后一个元素),step 表示步长(默认为1)
hello = (1, 2, 3)
li = [1, "2", [3, 'a'], (1, 3), hello]
print(li) # [1, '2', [3, 'a'], (1, 3), (1, 2, 3)]
print(li[1:2]) # ['2']
print(li[:2]) # [1, '2']
print(li[:]) # [1, '2', [3, 'a'], (1, 3), (1, 2, 3)]
print(li[2:]) # [[3, 'a'], (1, 3), (1, 2, 3)]
print(li[1:-1:2]) # ['2', (1, 3)]
访问内嵌 list 的元素:
li = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ['a', 'b', 'c']]
- 首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)
- 如果没有异常发生,忽略 except 子句,try 子句执行后结束。
- 如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。最后执行 try 语句之后的代码。
- 如果一个异常没有与任何的 except 匹配,那么这个异常将会传递给上层的 try 中。
- 一个 try 语句可能包含多个 except 子句,分别来处理不同的特定的异常。
- 最多只有一个 except 子句会被执行。
- 处理程序将只针对对应的 try 子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
- 一个 except 子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组。
- 最后一个 except 子句可以忽略异常的名称,它将被当作通配符使用。可以使用这种方法打印一个错误信息,然后再次把异常抛出。
- try except 语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后。这个子句将在 try 子句没有发生任何异常的时候执行。
- 异常处理并不仅仅处理那些直接发生在 try 子句中的异常,而且还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。
- 不管 try 子句里面有没有发生异常,finally 子句都会执行。
- 如果一个异常在 try 子句里(或者在 except 和 else 子句里)被抛出,而又没有任何的 except 把它截住,那么这个异常会在 finally 子句执行后再次被抛出。
抛出异常
使用 raise 语句抛出一个指定的异常。
raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
自定义异常
可以通过创建一个新的异常类来拥有自己的异常。异常类继承自 Exception 类,可以直接继承,或者间接继承。
当创建一个模块有可能抛出多种不同的异常时,一种通常的做法是为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类。
大多数的异常的名字都以”Error”结尾,就跟标准的异常命名一样。
实例
import sys
class Error(Exception):
"""Base class for exceptions in this module."""
pass
# 自定义异常
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
try:
print('code start running...')
raise InputError('input()', 'input error')
# ValueError
int('a')
# TypeError
s = 1 'a'
dit = {'name': 'john'}
# KeyError
print(dit['1'])
except InputError as ex:
print("InputError:", ex.message)
except TypeError as ex:
print('TypeError:', ex.args)
pass
except (KeyError, IndexError) as ex:
"""支持同时处理多个异常, 用括号放到元组里"""
print(sys.exc_info())
except:
"""捕获其他未指定的异常"""
print("Unexpected error:", sys.exc_info()[0])
# raise 用于抛出异常
raise RuntimeError('RuntimeError')
else:
"""当无任何异常时, 会执行 else 子句"""
print('"else" 子句...')
finally:
"""无论有无异常, 均会执行 finally"""
print('finally, ending')
文件操作
打开文件
open() 函数用于打开/创建一个文件,并返回一个 file 对象:
open(filename, mode)
- filename:包含了你要访问的文件名称的字符串值
- mode:决定了打开文件的模式:只读,写入,追加等
文件打开模式:
文件对象方法
- fileObject.close()
- close() 方法用于关闭一个已打开的文件。关闭后的文件不能再进行读写操作,否则会触发 ValueError 错误。 close() 方法允许调用多次。
- 当 file 对象,被引用到操作另外一个文件时,Python 会自动关闭之前的 file 对象。 使用 close() 方法关闭文件是一个好的习惯。
- fileObject.flush()
- flush() 方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。
- 一般情况下,文件关闭后会自动刷新缓冲区,但有时你需要在关闭前刷新它,这时就可以使用 flush() 方法。
- fileObject.fileno()
- fileno() 方法返回一个整型的文件描述符(file descriptor FD 整型),可用于底层操作系统的 I/O 操作。
- fileObject.isatty()
- isatty() 方法检测文件是否连接到一个终端设备,如果是返回 True,否则返回 False。
- next(iterator[,default])
- Python 3 中的 File 对象不支持 next() 方法。 Python 3 的内置函数 next() 通过迭代器调用 __next__() 方法返回下一项。在循环中,next() 函数会在每次循环中调用,该方法返回文件的下一行,如果到达结尾(EOF),则触发 StopIteration。
- fileObject.read()
- read() 方法用于从文件读取指定的字节数,如果未给定或为负则读取所有。
- fileObject.readline()
- readline() 方法用于从文件读取整行,包括 “\n” 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 “\n” 字符。
- fileObject.readlines()
- readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for... in ... 结构进行处理。如果碰到结束符 EOF,则返回空字符串。
- fileObject.seek(offset[, whence])
- seek() 方法用于移动文件读取指针到指定位置。
- whence 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾。whence 值为默认为0,即文件开头。例如:
- seek(x, 0):从起始位置即文件首行首字符开始移动 x 个字符
- seek(x, 1):表示从当前位置往后移动 x 个字符
- seek(-x, 2):表示从文件的结尾往前移动 x 个字符
- fileObject.tell(offset[, whence])
- tell() 方法返回文件的当前位置,即文件指针当前位置。
- fileObject.truncate([size])
- truncate() 方法用于从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后 V 后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。
- fileObject.write([str])
- write() 方法用于向文件中写入指定字符串。
- 在文件关闭前或缓冲区刷新前,字符串内容存储在缓冲区中,这时你在文件中是看不到写入的内容的。
- 如果文件打开模式带 b,那写入文件内容时,str (参数)要用 encode 方法转为 bytes 形式,否则报错:TypeError: a bytes-like object is required, not 'str'。
- fileObject.writelines([str])
- writelines() 方法用于向文件中写入一序列的字符串。这一序列字符串可以是由迭代对象产生的,如一个字符串列表。换行需要指定换行符 \n。
实例
filename = 'data.log'
# 打开文件(a 追加读写模式)
# 用 with 关键字的方式打开文件,会自动关闭文件资源
with open(filename, 'w ', encoding='utf-8') as file:
print('文件名称: {}'.format(file.name))
print('文件编码: {}'.format(file.encoding))
print('文件打开模式: {}'.format(file.mode))
print('文件是否可读: {}'.format(file.readable()))
print('文件是否可写: {}'.format(file.writable()))
print('此时文件指针位置为: {}'.format(file.tell()))
# 写入内容
num = file.write("第一行内容\n")
print('写入文件 {} 个字符'.format(num))
# 文件指针在文件尾部,故无内容
print(file.readline(), file.tell())
# 改变文件指针到文件头部
file.seek(0)
# 改变文件指针后,读取到第一行内容
print(file.readline(), file.tell())
# 但文件指针的改变,却不会影响到写入的位置
file.write('第二次写入的内容\n')
# 文件指针又回到了文件尾
print(file.readline(), file.tell())
# file.read() 从当前文件指针位置读取指定长度的字符
file.seek(0)
print(file.read(9))
# 按行分割文件,返回字符串列表
file.seek(0)
print(file.readlines())
# 迭代文件对象,一行一个元素
file.seek(0)
for line in file:
print(line, end='')
# 关闭文件资源
if not file.closed:
file.close()
输出:
文件名称: data.log
文件编码: utf-8
文件打开模式: w
文件是否可读: True
文件是否可写: True
此时文件指针位置为: 0
写入文件 6 个字符
16
第一行内容
16
41
第一行内容
第二次
['第一行内容\n', '第二次写入的内容\n']
第一行内容
第二次写入的内容
序列化
在 Python 中 pickle 模块实现对数据的序列化和反序列化。pickle 支持任何数据类型,包括内置数据类型、函数、类、对象等。
方法
dump
将数据对象序列化后写入文件
pickle.dump(obj, file, protocol=None, fix_imports=True)
必填参数 obj 表示将要封装的对象。 必填参数 file 表示 obj 要写入的文件对象,file 必须以二进制可写模式打开,即wb。 可选参数 protocol 表示告知 pickle 使用的协议,支持的协议有 0,1,2,3,默认的协议是添加在 Python 3 中的协议3。
load
从文件中读取内容并反序列化
pickle.load(file, fix_imports=True, encoding='ASCII', errors='strict')
必填参数 file 必须以二进制可读模式打开,即rb,其他都为可选参数。
dumps
以字节对象形式返回封装的对象,不需要写入文件中
pickle.dumps(obj, protocol=None, fix_imports=True)
loads
从字节对象中读取被封装的对象,并返回
pickle.loads(bytes_object, fix_imports=True, encoding='ASCII', errors='strict')
实例
import pickle
data = [1, 2, 3]
# 序列化数据并以字节对象返回
dumps_obj = pickle.dumps(data)
print('pickle.dumps():', dumps_obj)
# 从字节对象中反序列化数据
loads_data = pickle.loads(dumps_obj)
print('pickle.loads():', loads_data)
filename = 'data.log'
# 序列化数据到文件中
with open(filename, 'wb') as file:
pickle.dump(data, file)
# 从文件中加载并反序列化
with open(filename, 'rb') as file:
load_data = pickle.load(file)
print('pickle.load():', load_data)
输出:
pickle.dumps(): b'\x80\x03]q\x00(K\x01K\x02K\x03e.'
pickle.loads(): [1, 2, 3]
pickle.load(): [1, 2, 3]
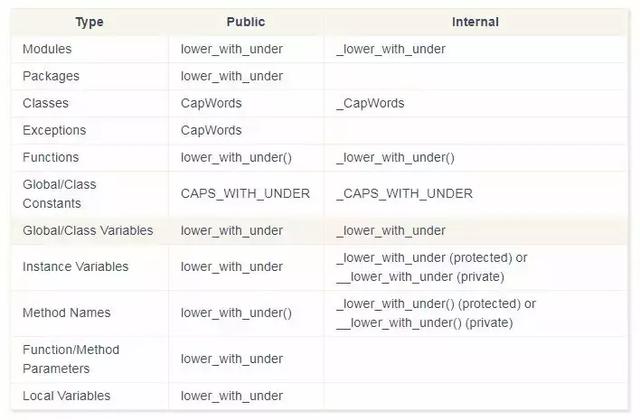
命名规范
Python 之父 Guido 推荐的规范
要是有小伙伴看不懂的话可以找老师领取视频教学资料,联系我即可,

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






