清华大学高级机器学习 解读清华谷歌等10篇强化学习论文总结
强化学习(Reinforcement Learning,RL)正成为当下机器学习中最热门的研究领域之一。与常见的监督学习和非监督学习不同,强化学习强调智能体(agent)与环境(environment)的交互,交互过程中智能体需要根据自身所处的状态(state)选择接下来采取的动作(action),执行动作后,智能体会进入下一个状态,同时从环境中得到这次状态转移的奖励(reward)。
强化学习的目标就是从智能体与环境的交互过程中获取信息,学习状态与动作之间的映射,指导智能体根据状态做出最佳决策,最大化获得的奖励。
在强化学习系统中,除了智能体和环境,重要元素还包括价值函数(value function)、策略(policy)以及奖励信号(reward signal)。Value-based 和 Policy-based 是强化学习算法设计的两大思路。在智能体与环境交互过程中,奖励是智能体在某个状态执行动作后立即得到的反馈,而价值函数则反映了智能体考虑未来的行动之后对所有可能状态的评估。
本文对近两年来发表在ICLR、ICML等AI顶会上有关强化学习的论文进行了解读,以飨读者。
Ask the Right Questions:Active Question Reformulation with Reinforcement Learning
论文作者:Christian Buck, Jannis Bulian, Massimiliano Ciaramita, Wojciech Gajewski, Andrea Gesmundo, Neil Houlsby, Wei Wang(谷歌)
论文地址:https://arxiv.org/pdf/1705.07830v2.pdf
总结:本文将问答看做一个强化学习任务,主要思想是在用户和问答系统之间增加一个问题重构模块。该模块可以将用户问题改写成不同形式,这些改写后的问题可以通过问答系统得到多个答案,该模块再从这些答案中选择质量最高的回答返回给用户。问题重构模块的核心是一个类似机器翻译的sequence-to-sequence模型,该模型首先通过单语语料预训练,之后使用Policy Gradient进行强化学习的训练过程,目标是使问答系统得到最佳回答的奖励。

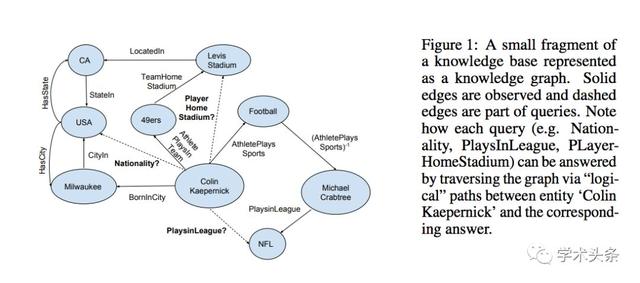
Go for a Walk and Arrive at the Answer:Reasoning over Paths in Knowledge Bases using Reinforcement Learning
论文作者:Rajarshi Das, Shehzaad Dhuliawala, Manzil Zaheer, Luke Vilnis, Ishan Durugkar, Akshay Krishnamurthy, Alex Smola, Andrew McCallum(马萨诸塞大学,卡内基梅隆大学,德克萨斯大学奥斯汀分校,亚马逊)
论文地址:https://arxiv.org/pdf/1711.05851.pdf
总结:本文提出了MINERVA算法解决知识图谱中的自动推理问题。MINERVA算法主要用于基于知识图谱的自动问答:给定三元组中的关系和其中一个实体,补全另一个实体。作者采用基于路径搜索的方法,从已知的实体节点出发,根据问题选择合适的路径到达答案节点。作者将问题形式化为一个部分可观察的马尔可夫决策过程,将观察序列和历史决策序列用基于LSTM的策略网络表示。LSTM的训练使用了Policy Gradient方法。
Active Neural Localization
论文作者:Devendra Singh Chaplot, Emilio Parisotto, Ruslan Salakhutdinov(卡内基梅隆大学)
论文地址:https://www.aminer.cn/pub/5a9cb66717c44a376ffb8b95/active-neural-localization
总结:本文介绍了Active Neural Localization模型,根据给定的环境地图和智能体的观察,可以估计出智能体的位置。该方法可以直接从数据学习,并主动预测智能体行动来获得精确和高效的定位。该方法结合了传统的filter-based定位方法和策略模型,可以使用强化学习进行end-to-end训练。模型包括一个感知模型和一个策略模型,感知模型根据当前智能体的观测计算可能位置的信念(Belief),策略模型基于这些信念估计下一步行动并进行精确定位。

The Reactor:A fast and sample-efficient Actor-Critic agent for Reinforcement Learning
论文作者:Audrunas Gruslys, Mohammad Gheshlaghi Azar, Marc G. Bellemare, Remi Munos(DeepMind)
论文地址:https://arxiv.org/pdf/1704.04651.pdf
总结:本文提出了Reactor模型,该模型结合了off-policy经验回放的低样本复杂度和异步算法的高训练效率两方面优点,比Prioritized Dueling DQN和Categorical DQN有更低的样本复杂度,同时比A3C有更低的运行时间。作者在模型中使用了多个技术,包括:新的策略梯度算法beta-LOO,多步off-policy分布式强化学习算法Retrace,prioritized replay方法以及分布式训练框架。

Reinforcement Learning for Relation Classification from Noisy Data
论文作者:Jun Feng,Minlie Huang,Li Zhao,Yang Yang,Xiaoyan Zhu(清华大学,微软亚洲研究院,浙江大学)
论文地址:https://www.aminer.cn/pub/5b1642388fbcbf6e5a9b54be/reinforcement-learning-for-relation-classification-from-noisy-data
总结:现有的关系分类方法主要有两个局限性:无法进行sentece-level的关系分类;依赖远程监督(distant supervision)标注的数据,但标注数据中存在较大误差。本文介绍了一个sentence-level的关系分类算法。算法由两个部分组成,分别是“instance selector”和“relation classifier”。Instance selector用于选取质量高的句子作为relation classifier的训练数据,该过程可以看做一个强化学习问题。作者分别定义了Instance selector的动作空间,状态空间和奖励函数,并给出了基于Policy Gradient的优化方法。

Learning Structured Representation for Text Classification via Reinforcement Learning
论文作者:Tianyang Zhang, Minlie Huang,Li Zhao(清华大学,微软亚洲研究院)
论文地址:https://www.microsoft.com/en-us/research/wp-content/uploads/2017/11/zhang.pdf
总结:本文提出了一个基于深度学习的句子表示算法,可以针对任务学习句子的结构化表示。该算法不需要解析树或其他显示的结构化表示标注作为输入,而是通过训练数据自动效识别与任务相关的句子结构。作者使用强化学习的方法构建任务相关的句子结构表示,模型由三部分组成,分别是Policy Network (PNet),Structured Representation Model和Classification Network (CNet),PNet为句子产生一个动作序列,Structured Representation Model将动作序列转化为结构化表示,CNet提供奖励信号,模型参数可以使用Policy Gradient方法优化。

Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning
论文作者:Anusha Nagabandi, Gregory Kahn, Ronald S. Fearing, Sergey Levine(加州大学伯克利分校)
论文地址:https://www.aminer.cn/pub/5a260c8417c44a4ba8a31564/neural-network-dynamics-for-model-based-deep-reinforcement-learning-with-model-free
总结:本文提出了一种新的model-based的强化学习学法,并可以用于初始化model-free的算法。作者提出的model-based算法使用神经网络拟合动力学模型,并结合了MPC(model predictive control)。作者使用model-based优化得到的动力学模型作为model-free算法的初始化,可以同时保留model-based算法样本复杂度小,model-free算法泛化能力强两方面的优势。

Learning to Collaborate:Multi-ScenarioRanking via Multi-Agent Reinforcement Learning
论文作者:Jun Feng, Heng Li, Minlie Huang, Shichen Liu, Wenwu Ou, Zhirong Wang, Xiaoyan Zhu(清华大学,阿里巴巴)
论文地址:https://arxiv.org/pdf/1809.06260v1.pdf
总结:本文提出了一个多场景联合排序算法,目标是提高多场景的整体效果。多场景之间存在博弈关系,单个场景提升无法保证整体提升。本文将多场景排序看做一个完全合作,部分可观测的多智能体序列决策问题,并采用多智能体强化学习的框架建模。作者提出了MA-RDPG(Multi-Agent Recurrent Deterministic Policy Gradient)算法,利用DRQN对用户的历史信息建模,同时用DPG对连续状态和连续动作空间进行探索。

Curriculum Learning for Heterogeneous Star Network Embedding via Deep Reinforcement Learning
论文作者:Meng Qu,Jian Tang,Jiawei Han(伊利诺伊大学香槟分校)
论文地址:https://www.aminer.cn/pub/5a9cb60d17c44a376ffb3c89/curriculum-learning-for-heterogeneous-star-network-embedding-via-deep-reinforcement-learning
总结:本文将深度强化学习应用到了异构星型网络的表示学习中。在异构星型网络表示的学习过程中通常需要采样一系列的边来得到点之间的相似性,作者发现这些边的顺序会显著影响表示学习的效果。作者借鉴了课程学习(Curriculum Learning)的思想,研究如何在网络表示学习中学习这些边的采样顺序。该问题可以形式化为马尔可夫决策过程,作者提出了一个基于深度强化学习的解决方法。

Soft Actor-Critic:Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
论文作者:Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, Sergey Levine(加州大学伯克利分校)
论文地址:https://arxiv.org/pdf/1801.01290.pdf
总结:本文提出了soft actor-critic算法。该算法是一个基于最大熵强化学习的off-policy actor-critic算法,在最大化奖励的同时最大化熵,让动作尽可能随机。作者证明了算法的收敛性,并在多个benchmark上超越了已有的on-policy或off-policy的算法。

大家都在看:
AAAI2020放榜,审稿遭疯狂吐槽!八篇入选论文提前看!
ICCV2019 | 旷视提出轻量级目标检测网络ThunderNet
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






