python字符串编码格式转换(Python中字符串编码转换encode编码和decode解码详解)
欢迎你来到站长在线的站长学堂学习Python知识,本文学习的是《Python中字符串编码转换:encode编码和decode解码详解》。本知识点主要内容有:常用编码简介、使用encode()方法编码、使用decode()方法解码、unicode和UTF-8的关系说明。
我们在《Python中的基本数据类型》中,学习过:字符串就是连续的字符序列,可以是计算机能够表示的一切字符的集合。字符串属于不可变序列,通常用单引号(' ')、双引号(" ")或者三引号(''' '''或""" """)括起来。还提到了字符串常用的转义字符。今天主要来讲解一下字符串编码转换。
1、常用编码简介1.1、ASCII,即美国标准信息交换码,1967年制定,主要用于美国和西欧,它仅对10个数字、26个大写英文字母、26个小写英文字母,以及一些其他符号进行了编码。ASCII码最多只能表示256个符号,每个字符占一个字节(bytes)。
1.2、gb2312,国家简体中文字符集,1980年制定,兼容ASCII。每个中文字符占两个字节。
1.3、Unicode,国际标准组织统一标准字符集,1991年制定。Unicode包含了跟全球所有国家编码的映射关系。每个字符占两个字节。
1.4、UTF-8,国际通用编码,制定于1992年,对全世界所有国家用到的字符都进行了编码。UTF-8采用一个字节表示英文字符,用三个字节表示中文。在Python3.x中默认的编码就是UTF-8编码,这就有效的解决了中文乱码的问题。
1.5、GBK,为GB2312的扩展字符集,兼容GB2312,支持繁体字,1995年制定。每个中文字符占两个字节。
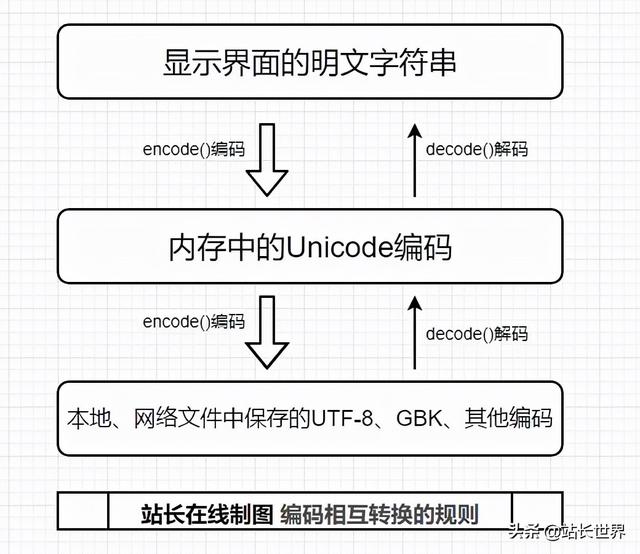
在Python中,有两种常用的字符串类型,分别为str和bytes。其中,str表示Unicode字符(ASCII或者其他);bytes表示二进制数据(包括编码的文本)。这两种类型的字符串不能拼接在一起使用。通常情况下,str在内存中以Unicode表示,一个字符对应若干个字节。但是如果在网络上传输,或者保存到磁盘上,就需要把str转换为字节类型,即bytes类型。
bytes类型的数据是带有b前缀的字符串(用单引号或双引号表示),例如,b'\xd2\xb0'和b'QQ'都是bytes类型的数据。
str和bytes之间可以通过encode()和decode()方法进行转换,这两个方法是互为逆过程。下面分别进行介绍。
2、使用encode()方法编码encode()方法为str对象的方法,用于将字符串转换为二进制数据(即bytes),也称为“编码”,其语法格式如下:
str.encode([encoding="utf-8"][,errors="strict"])
参数说明如下:
str:表示要进行转换的字符串。
encoding="utf-8":可选参数,用于指定进行转码时采用的字符编码,默认为utf-8,如果想使用简体中文,也可以设置为gb2312。当只有这一个参数时,也可以省略前面的“encoding=”,直接写编码。
errors="strict":可选参数,用于指定错误处理方式,其可选择值可以是strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)或xmlcharrefreplace(使用XML的字符引用)等,默认值为strict。
说明
在使用encode()方法时,不会修改原字符串,如果需要修改原字符串,需要对其进行重新赋值。
例如,定义一个名称为a的字符串,内容为“星星之火可以燎原”,然后使用encode()方法将其采用GBK编码转换为二进制数,并输出原字符串和转换后的内容,代码如下:
a = '星星之火可以燎原'
b = a.encode('gbk') # 将gbk编码转换为二进制数据,不处理异常
print('原字符串:',a) # 输出原字符串
print('转换后:',b) # 输出转换后的二进制数据
上面的代码执行后,将显示以下内容。
原字符串: 星星之火可以燎原
转换后: b'\xd0\xc7\xd0\xc7\xd6\xae\xbb\xf0\xbf\xc9\xd2\xd4\xc1\xc7\xd4\xad'
>>>
如果采用UTF-8编码,转换后的二进制数据为:
a = '星星之火可以燎原'
b = a.encode('utf-8') # 将UTF-8编码转换为二进制数据,不处理异常
print('原字符串:',a) # 输出原字符串
print('转换后:',b) # 输出转换后的二进制数据
原字符串: 星星之火可以燎原
转换后: b'\xe6\x98\x9f\xe6\x98\x9f\xe4\xb9\x8b\xe7\x81\xab\xe5\x8f\xaf\xe4\xbb\xa5\xe7\x87\x8e\xe5\x8e\x9f'
>>>
decode()方法为bytes对象的方法,用于将二进制数据转换为字符串,即将使用encode()方法转换的结果再转换为字符串,也称为“解码”。
其语法格式如下:
bytes.decode([encoding="utf-8"][,errors="strict"])
参数说明如下:
bytes:表示要进行转换的二进制数据,通常是encode()方法转换的结果。
encoding="utf-8":可选参数,用于指定进行解码时采用的字符编码,默认为UTF-8,如果想使用简体中文,也可以设置为gb2312。当只有这一个参数时,也可以省略前面的“encoding=”,直接写编码。
errors="strict":可选参数,用于指定错误处理方式,其可选择值可以是strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)或xmlcharrefreplace(使用XML的字符引用)等,默认值为strict。
站长在线提醒您:在使用decode()方法时,不会修改原字符串,如果需要修改原字符串,需要对其进行重新赋值。
例如,将上面示例中编码后得到二进制数据(保存在变量b中)进行解码,可以使用下面的代码:
a = b'\xd0\xc7\xd0\xc7\xd6\xae\xbb\xf0\xbf\xc9\xd2\xd4\xc1\xc7\xd4\xad'
print('解码后:',a.decode("gbk")) # 对进行制数据进行解码
上面的代码执行后,将显示以下内容:
解码后: 星星之火可以燎原
>>>
同样的,我们选择utf-8的字符串也是可以的
a = b'\xe6\x98\x9f\xe6\x98\x9f\xe4\xb9\x8b\xe7\x81\xab\xe5\x8f\xaf\xe4\xbb\xa5\xe7\x87\x8e\xe5\x8e\x9f'
print('解码后:',a.decode("utf-8")) # 对进行制数据进行解码
上面的代码执行后,将显示以下内容:
解码后: 星星之火可以燎原
>>>
站长在线提醒您:在设置解码采用的字符编码时,需要与编码时采用的字符编码一致。
本文相关知识扩展阅读:
4、Unicode和UTF-8的关系说明Unicode直接支持全球所有语言,包含了跟全球所有国家编码的映射关系。
Unicode解决了字符和二进制的对应关系,但是使用unicode的每一个字符,都占用了两个字节,太浪费空间。如unicode表示“Python”需要12个字节才能表示,比原来ASCII表示增加了1倍。
由于计算机的内存比较大,并且字符串在内容中表示时也不会特别大,所以内容可以使用unicode来处理,但是存储和网络传输时一般数据都会非常多,那就不能这样传输了。
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行格式转换,以便于在存储和网络传输时可以节省空间!
UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚语系占3个,其它及特殊字符占4个。
UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
UTF-32: 使用4个字节表示所有字符。
总结:UTF 是为unicode编码 设计 的一种在存储和传输时节省空间的编码方案。
到此为止,本文学习的是《Python中字符串编码转换详解》。本知识点主要内容有:常用编码简介、使用encode()方法编码、使用decode()方法解码、Unicode和UTF-8的关系说明。就讲解完毕了,有问题的可以给我留言哦!
关注【站长在线】,让新手小白系统的零基础学习Python,感谢你对我们的关注,点赞,转发,评论哦!
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






