大数据计算框架flink(大数据Flink数据处理)


flink的安装部署,集群配置我们都说完了,然后我们再来看


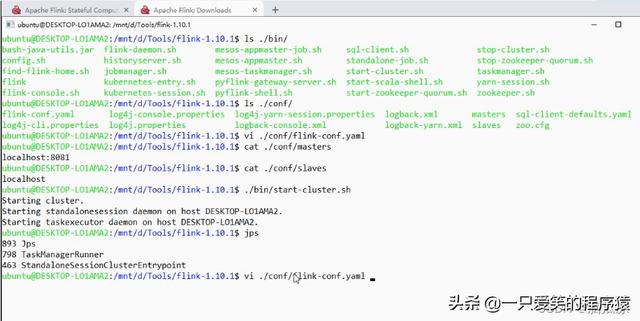
可以看到在bin目录下有个start-cluster.sh
启动这个就可以启动集群.
当然现在我们只有一个节点对吧,我们是本地模式standalonesession这个就相当于,我们的jobmanager对吧,一个会话提交任务要通过这个会话.
然后taskexecutor相当于taskmanager对吧,用来干活的


我们可以用jps看一下进程可以看到有个taskmanagerrunner,有个standaloneSessionCluster对吧.

然后我们再看一下配置文件
/conf/flink-conf.yaml


可以看到除了上一节我们说的以外,下面还有
High Availability 高可用的部分配置对吧


然后再往下可以看到有个
Fault tolerance and checkpointing
tolerance 宽容 是容错和检查点.


可以看到这里有个state.backend:filesystem
这个是状态后端,可以看到我们的检查点,可以配置在远程也可以配置在文件系统
后面说状态的时候会说到.


然后我们再看下面有个Rest & web frontend可以看到这个
是用来在web上管理的
可以看到端口是8081对吧


然后下面是一些高级的功能


然后我们去看看web端,输入localhost:8081 就可以访问了


然后首先我们看到现在他有1个slots也就是一个jobmanager对吧.


然后我们再看taskmanagers这里有一个taskmanager对吧,然后
可以看到这个taskmanager的内容,可以看到物理内存是7.7gb,然后
jvm堆内存是512mb,然后flink managed mem,flink管理的堆外内存是512mb对吧.


可以看到我们之前分配的总内存是
1728mb对吧,现在 jvm的堆内存是512,然后flink 的堆外内存是512mb对吧,
但是合起来还不够1728对吧,那么剩下的也是堆外内存,用来记录一下运行的状态
参数什么的.


然后我们再看taskmanagers下面有具体的,内存多少,使用了多少详细情况


然后我们再看,还有个logs,可以看到有个日志窗口,
taskmanager启动的窗口可以在这里看


然后我们再看jobmanager,这里也有个配置信息可以看到,跟
我们看的那个配置文件中的一样,然后也有个logs对吧,可以看jobmanager启动情况


然后我们再看有个stdout对吧,这个可以看到是,标准输出
这里如果flink执行程序,输出内容会在这里看到
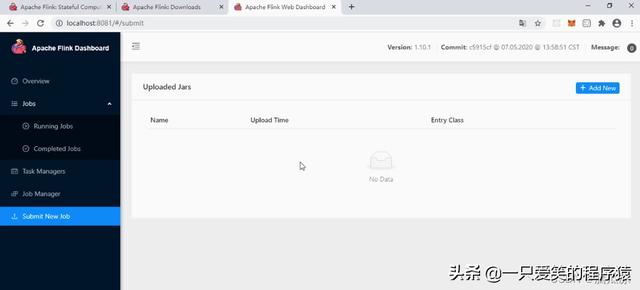

然后再看submit new job这里可以看到
有个add new对吧,我们可以打包一个jar包然后上传上来


然后我们这里找到StreamWordCount我们之前写的程序
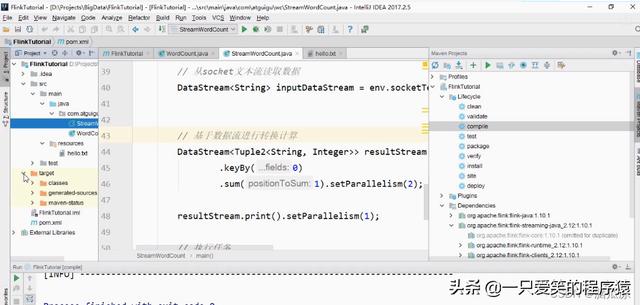
这里,可以看到我们设置的并行度是
setParallelism(1) 1对吧


然后我们再看,实际上,我们设置并行度的时候,可以给某个任务单独的设置并行度,我们可以让
某个任务单独,设置用几个线程来执行.
比如我们给sum这个操作设置用2个线程执行对吧,然后给输出print设置用1个线程来处理,注意
在flink环境中,因为是分布式大数据环境,所以所有的任务他都给拆分成了,一个个小的任务,而每个
任务都可以设置并行度,你可以设置你的某个小任务使用几个线程来执行.

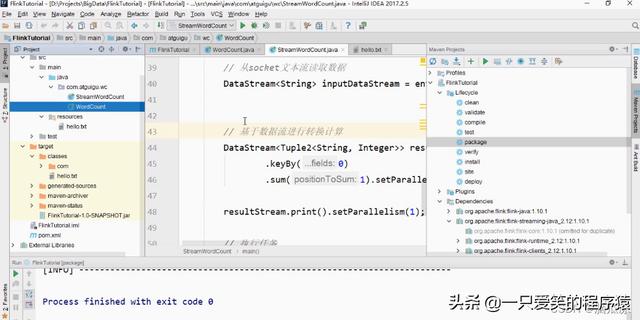
然后我们开始去打包,首先先去编译一下
compile编译一下


然后再去package,这里打包,打包以后可以看到是
有打包出来的.jar包对吧?


然后我们把生成的这个jar包,我们提交到flink上面去,可以看到提交好了,点击add new ,找到
jar文件,然后上传就可以了.

然后我们提交了以后,他是没有执行的对吧,我们知道我们,现在有两个可以执行的程序,可以看到上面
WordCount这个,还有StreamWordCount这个流处理的对吧.我们有两个可以执行的程序
我们让他执行哪个这里还没有配置,然后还有执行的时候,有参数我们也还没有配置
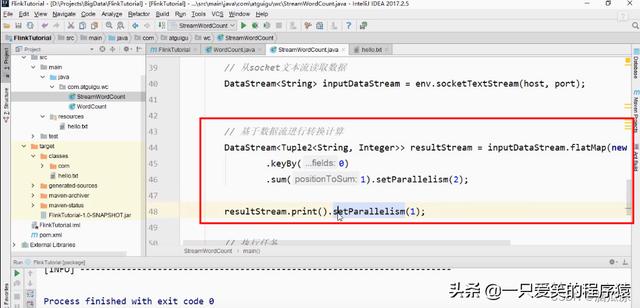

然后我们再看并行度配置,如果我们在代码中进行了并行度配置,肯定是,代码中的配置是优先级最高的
然后
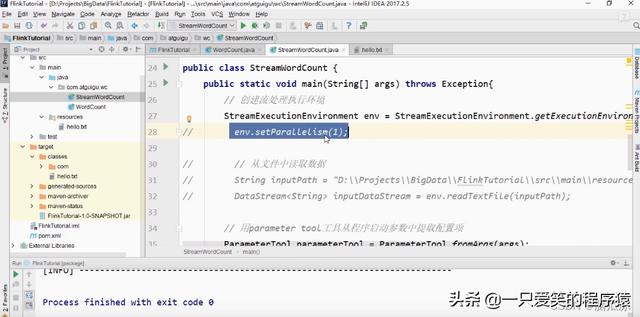

然后才是env.setParallelism(1) 这个整体上的并行度设置,如果在代码中没有设置,就默认用这个env.setParallelism(1)
整体的设置.如果这里整体的也没有设置就,用之前我们配置文件中的,那个parallelism.default的配置了


然后我们去给我们提交上去的jar,配置参数,点击一下FlinkTutorial-1.0-SNAPSHOT.jar这个jar包
可以看到弹出来的,地方可以进行参数配置,首先配置,执行的实体类:com.atguigu.wc.StreamWordCount
然后再配置参数:--host localhost --post 7777 然后再设置右上角那个:是并行度
那么这个并行度和代码中设置的有什么关联呢?


我可以点一下这个show plan去看,可以看到执行的计划.
注意这里我们右上角的并行度我们设置为3了.


1.可以看到他的执行计划,这个source socket Stream 这里,这个parallelism这里是1对吧,为什么呢?


因为,我们可以看到这个
source socket stream这里是去读一个文件,对吧,读取的时候,只能用一个进程去读取对吧,要不然,这个进程读一些,那个进程读取一些,到时候拼起来就跟原来的文件不一样了,所以这个文件只能一个进程去读取,所以这里并行度是1


2.然后看flatMap这里的parallelism这里是3 并行度,为什么呢?因为这个flatMap,可以看到代码中没有设置,
代码没有设置的话,那么,并且我们的env.parallelism = 这个整体上的并行度也没有设置.
那么这个时候,他就会使用我们这里设置的并行度对吧,我们设置了是3所以,这个flatMap阶段的并行度就是3.


然后我们再去看keyed aggregation这个阶段,也就是对key的聚合阶段对吧.这里可以看到是2.
这个2可以看到实际上是我们自己在代码中设置的对吧.


然后再看这个sink print to std out这里是1对吧


这个也是我们自己设置的可以看到resultStream.print().setParallelism(1) 是1对吧.


然后如果我们把我们右上角填写的并行度3,删除掉,然后我们再点开,show plan 然后再看
可以看到就变成3个了对吧,执行计划.


可以看到这个时候,source socket stream ->flatmap 这两步的并行度都是1了对吧,因为source socket stream只能是1,我们上面
解释了,然后flatMap,因为我们没有指定并行度,在代码中没有指定在,上面配置的时候也没有指定,那么这个时候,他就去用,我们
配置文件中,配置的default这里指定的parallelism:是1 了.
然后我们再看这个keyed aggregation这里是我们自己指定的2对吧,然后sink print to std out 1这里也是我们指定的对吧,
所以就变成3 了


好,右上角并行度我们不填写,然后
savepoint path可以看到,这里是指定保存点的,位置,这个其实跟checkpoint那个检查点是一样的,这里保存了
然后到时候就可以恢复到这个,保存点的样子,只不过这里的savepoint是手动的,我们可以自己指定一个保存点,
然后checkpoint是自动的,他自动给我保存的对吧.
然后我们点击提交


然后我们再点overview去看可以看到,上面这些是这个计划的信息.


下面有他的状态可以看到现在这个计划是刚刚创建,也就是CREATED的状态对吧


然后我们再去,本地的centos环境,然后,我们用netcat开启的这个socket 流服务
然后输入:
hello flink等测试一下


可以看到没有反应对吧.
状态也没有变,还是CREATED
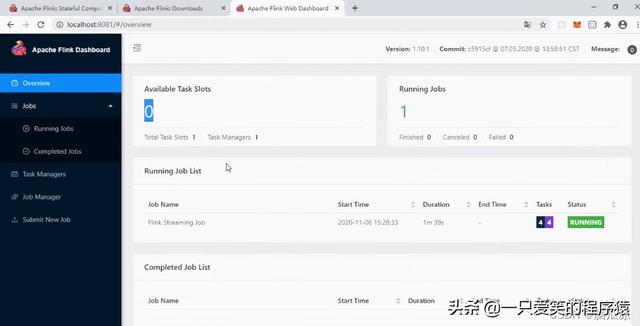

然后我们再看下面这个Available task slots 这个jobmanager可以看到已经分出去了对吧,已经分给他了,但是
还是没有执行起来对吧.
可以看到running jobs 也是1对吧


可以看到bytes received可以看到也是在转圈对吧,那是怎么回事呢?
因为,我们可以看到,上面图中,parallelism:1 2 1 需要4个并行度对吧,那现在呢?
可以看到我们只有1个对吧,1个jobmanager,1个线程对吧,所以说什么啊?
不能满足这个任务的需求,所以他就开始在等待了....等待给他足够的资源然后他开始执行对吧.
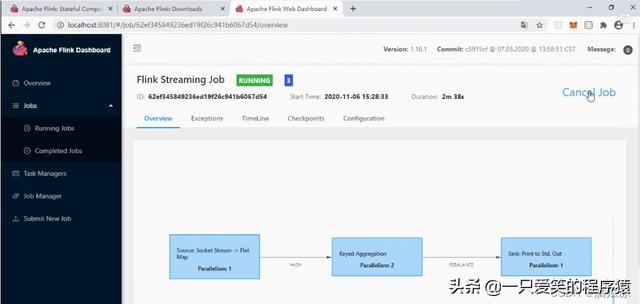

所以现在知道他为什么不能执行,我们直接点击cancle job把这个任务终止掉.


可以看到这里,状态已经是canceled了对吧


然后running jobs里面是空的了没有内容了


然后completed jobs这里完成的任务这里,可以看到完成的任务这里,显示已经canceled了对吧
然后我们canceled掉了任务以后,然后我们再去看这里
available task slots 这里可以看到可用的jobmanager又变成1了对吧.
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






