微软虚拟现实更新(在所有事情上打败所有人)
梦晨 羿阁 发自 凹非寺
量子位 | 公众号 QbitAI
仅靠19亿参数,只用公共数据集,在12个任务上狂刷SOTA。
微软这篇多模态论文刚挂上arXiv不久,就在业内引发强烈关注。
有网友将之总结成“在所有事情上打败了所有人”。
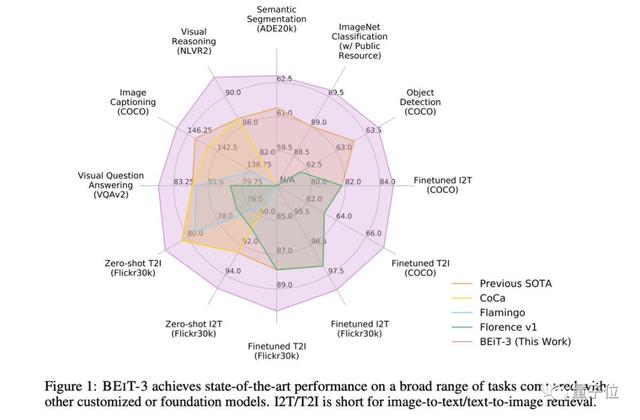
怎么回事?先来看这张雷达图:
橙色内圈,是各大任务之前的SOTA。
紫色外圈,就是这篇BEiT-3的结果,不仅超越,而且是全面超越。
具体一圈看下来,BEiT-3这个多模态模型不光刷遍多模态任务,连右上角的纯视觉三大经典任务也都刷到SOTA,简直是六边形战士。
知乎上一位同样做多模态研究的选手直呼“杀死了比赛”。
其实说起来,微软BEiT这个系列最开始做的是视觉自监督学习。
其核心思想与何恺明的MAE一致,甚至比MAE提出的还早一段时间,不过当时性能惜败于MAE。
如今在多模态方向上绕了一圈后,没想到能以方式横扫视觉与多模态榜单。
取得这种成果的,一般来说还不得是上百亿上千亿参数的大大大模型?
但BEiT-3总参数不过19亿,甚至训练数据上也没什么秘密武器,全都用的公开资源。
那么,这一切是如何做到的?
把图像当成一种外语最关键的一点,论文标题和摘要就已经指明:
把图像当成一种外语。
这样一来,文本数据是English,图像数据作者开了个小玩笑命名为Imglish,那么图文对数据就相当于平行语料。
那么多模态也好纯视觉也罢,都能用同一个预训练任务来处理。
在这个基础上,论文中把所做突破总结成一个词,大一统 (Big Convergence) 。
首先,大一统表现在网络架构上。
通过统一多模态表示方式,对于不同任务可以共享一部分参数,采用Multiway(多路)Transformer架构作为骨干网络。
具体来说就是共享多头自注意力层,输出时再根据具体任务选择专用的FFN层。
第二,大一统又表现在预训练方法上。
既然所有数据都能当成文本数据,那就可以全都按照BERT的方法,用掩码-预测来做预训练,称为Masked Data Modeling。
与基于对比学习的训练方法相比,新方法可以选用更小的Batch Size,又能额外降低显存消耗。
第三,大一统还表现在规模效应上。
统一的预训练任务让模型参数扩大到10亿数量级后,对下游任务的泛化能力增强。
另外不同模态的数据集在此方法下也产生规模效应。
团队特意只用公开数据的条件下增加训练数据集规模,结果超越了一些使用高质量私有数据的模型。
BEiT-v的训练数据来自5个公开数据集中的约500万张图像和2100万图像-文本对;单模态数据则使用来自ImageNet-21K的1400万张图像和160GB的文本语料库。
除此之外,在规模上也远小于其它的多模态预训练模型,例如ALIGN(18亿图文对)、CLIP(4亿图文对)、SimVLM(18亿图文对,800GB文本)等。
所有这些优势叠加在一起,BEiT-3就以更少的训练数据、更小的模型参数取得更好的性能。
在纯视觉任务(图像分类、目标检测、语义分割)以及多模态任务(视觉推理、视觉问答、图像描述、微调的跨模态检索、零样本跨模态检索)总共8类任务下超越各自之前的SOTA。
BEiT-3 这篇论文很简短,不算参考文献只有9页。
但熟悉微软BEiT系列历史的话就会知道,这项研究取得成功的意义不仅在于其自身,也不仅是多模态学习的一项突破——
还给视觉大规模预训练这个兴起不久的领域,带来新的可能性。
BEiT与MAE,视觉自监督的路线之争关于微软的BEiT系列,全称为Bidirectional Encoder representation from Image Transformers,比大家熟悉的语言模型BERT多了个“Image”。
其主要思想就是借鉴BERT,把掩码建模方法用到视觉任务上,做视觉的自监督学习,解决高质量标注数据难以获得的难题。
初代BEiT论文于去年6月发表,比同类工作何恺明的MAE还要早一些,也是MAE论文中的主要比较对象之一。
初代BEiT,惜败MAE
两项研究都是用“先掩码再预测”来做预训练任务,最大的区别在于BEiT会把视觉token离散化、最后模型预测的是token,而MAE则是直接预测原始像素。
△初代BEiT的架构
在三大视觉任务上,MAE比当时的BEiT略胜一筹。并且因方法更简单直接,MAE运行起来也要快上不少(3.5倍)。
为了证明在MAE中token化这一步并无必要,何恺明团队在论文中还特意做了消融试验。
结果表明,两种方法统计上并无显著差异,对于MAE来说预测原始像素就足够了。
不过BEiT团队并没有放弃离散化token这个方法,而是沿着这个思路继续探索下去。
VL-BEiT,初探多模态一年之后,团队发表了多模态模型VL-BEiT,可以算作是现在这篇BEiT-3的雏形。
VL-BEiT已经用上了共享Attenion层、再对不同任务连接不同FFN层的架构。
这一思想其实来自同一团队更早之前一篇论文VLMo,对每个模态设置一个专家层的方法称为MoME(Mixture-of-Modality-Experts)。
不过,VL-BEiT在预训练任务上还比较复杂,会对文本数据和图像数据分别做掩码建模,至于多模态图文对数据也是分开处理的。
最后结果,VL-BEiT在多模态任务和纯视觉任务上表现都不错,但还不像现在的BEiT-3这样大杀四方。
不过别急,突破口很快就被找到。
BEiT v2,把token提升到语义级BEiT-3发表仅一周之前,微软与国科大团队合作发表了一篇BEiT v2。
两者命名方式有细微差别,因为BEiT v2确实代表是BEiT的升级版。
而BEiT-3的3论文中虽未明说,但说的大概不是“第三代”,而是另有所指(稍后揭秘)。
说回到BEiT v2,这篇论文重新专注于纯视觉,在初代BEiT基础上提出了新的语义级tokenizer。
具体来说,BEiT v2引入了矢量量化(Vector-Quantized)和知识蒸馏(Knowledge Distillation)来训练tokenizer。
同样是做离散化token,新方法能重建知识蒸馏中教师模型的语义特征,大大提高token中携带的语义信息,从而提高模型性能。
接下来,教师模型用谁就很关键了。
在对比了FAIR的DINO模型和OpenAI的CLIP模型之后,团队发现还是CLIP更香。
最终结果上,BEiTv2性能反超MAE和这段时间出现的其他方法,重回SOTA。
BEiT-3,集大成者
了解了整个BEiT系列的发展历程,最后再来看一下BEiT-3。
论文共同一作董力,点出了模型命名中“3”的含义:
多模态统一的预训练方式 共享Attention的多路Transformer 扩大规模的大一统(Big Convergence)。
如此一来,BEiT-3能在多模态任务和视觉任务中都取得SOTA也就不奇怪了。
这样一篇论文,自然吸引了行业内很多目光。
鲁汶大学一位教授认为,这代表微软在AI科研方面赶上谷歌/DeepMind、Meta和OpenAI,“重新坐上了牌桌”。
随着讨论热度升级,对论文更严格的审视目光也多了起来。
谷歌一位研究员指出,论文结果看起来简洁又令人印象深刻,就是这雷达图的坐标取值有点不太严谨。
知乎上也有网友提问,如果用了CLIP作为教师模型的话,那么来自CLIP高质量配对数据的贡献有多少,直接改改CLIP就用又会如何?
作者团队
最后再来介绍一下作者团队,BEiT-3相关研究论文的作者都来自微软。
三位共同一作分别是Wenhui Wang,Hangbo Bao(鲍航波)和Li Dong(董力)。
其中,鲍航波和董力都是从初代BEiT就参与了研究,一直贯穿VL-BEiT和BEiT v2的发展,鲍航波更是BEiT和VL-BEiT论文的一作。另一位Wenhui Wang之前也曾参与过VL-BEiT的研究。
通讯作者是微软亚洲研究院NLP小组的Partner研究经理Furu Wei(韦福如)。
BEiT-3论文:https://arxiv.org/abs/2208.10442
参考链接:[1]BEiT:https://arxiv.org/abs/2208.10442[2]VL-BEiT:https://arxiv.org/abs/2206.01127[3]VLMo:https://arxiv.org/abs/2111.02358[4]BEiT v2:https://arxiv.org/abs/2208.06366[5]MAE:https://arxiv.org/abs/2111.06377[6]https://twitter.com/_akhaliq/status/1561883261160259584[7]https://www.zhihu.com/question/549621097
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
,
























免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






