aws云计算讲解(就看懂了真正的云计算)

图表1 云计算构成
然而, 笔者认为这不是“什么是云计算”的答案,而是“云计算是什么样子”的答案。通俗一点,这个回答方式类似,问“中华武学是什么”,答“中华武学是咏春拳”。
那云计算的“神”是什么,笔者会以当前云计算的领头羊AWS的成功实践为依据,尝试回答这个问题。
1
数据中心与网络设计
在1999年HighPerformance Transaction Systems Hybrid Systems conference “Fault Avoidance vs. Fault Tolerance: TestingDoesn’t Scale”软件设计应该可以容错,而不是努力的通过大量测试而避免错误。因为软件的复杂度越来越高,代码量越来越大,会导致软件质量下降。而模块化设计不能减少复杂度,同时测试也覆盖不到所有复杂的,相互关联的特性。
在2009年 SIGCOMComputer Communications Review “The Cost of a Cloud: Research Problems in DataCenter Networks” 一种是建设10万台 的超大规模数据中心,有更好的性价比,但会有资源碎片等副作用。另外一种是围绕着最终用户建立一系列小型数据中心,会有好的访问延时,但数据中心之间的互联会十分昂贵。
接下来我们看AWS是怎么做的……
AWS数据中心的设计实践
图表 2 AWS数据中心概览
从图表2中的黄色标记可以看出,其围绕着客户在全球建立了16个资源隔离的Region,每个Region包含2~3个Availability Zone(可用区)。Availability Zone为一个数据中心群,包含1~6个6万 规模的超大数据中心。Availability Zone间距离通常为30~100公里,以保证风火水电的隔离。
图表 3 AWS实例规格统计
结合图表3,AWS的金牌合作伙伴RightScale发布的,关于其代维的AWS云主机规格统计饼图,我们可以看到1核~2核规格的云主机是主流,占据了近70%的比例。按照常规AWS物理主机的2个Intel Xeon E5 12 core的配置来看,平均每个物理机上应该承载12个左右的云主机数量。而6万台的数据中心应该包含72万台云主机。按照每Availability Zone平均包含3个数据中心算,AWS在每个Region拥有可高质量互通的7.5个6万 的数据中心群,其中可部署45万 的物理机,承载540万 的云主机,这是个非常巨型的解决方案。
AWS数据中心间的网络设计实践
先从图表4看其Region间互联设计,其通过各个Region自有的BGP AS域构建了一个100Gb带宽的环球互联网络,以支撑其全球级服务管理面互通,和AWS BGP AS内的公网IP之间互通流量。相对于公共互联网,有低延时高可用的优势。但对于每个Region内近540万 云主机来说,每个云主机的平均带宽不到24bps。
图表 4 Region间骨干网(单击放大)
再从图表5看其Region内网络互联设计。Region内的各个数据中心,通过两个独立的transit节点接入上面讲的Region间骨干网,以保证链路冗余性。Region内的2~3个AZ间保证全互连,互联链路带宽达到25Tbps。按照之前推论的AZ内包含180万 个云主机计算,每个云主机平均有14Mbps的带宽。每个AZ内的1~6个数据中心之间保证全互联,互联链路达到102Tbps,平均每个云主机拥有178Mbps的链路带宽。
图表 5 AZ内网络连接
从AWS的数据中心以及网络设计实践看,与前面两篇论文的理论是一致的。在Fault Avoidance上,AWS提出了Region与AvailabilityZone的概念,帮助客户构建高可用应用。Region为完全隔离的两个资源池,而Availability Zone是可互通的、但风火水电隔离的资源池。客户将服务部署到不同的Region与Availability Zone中,使用负载分担实现Active-Active高可用,以避免可能的单点故障。Availability Zone在其悉尼Region故障中经过了检验,在1个AZ完全停止服务时,另外一个AZ可以提供完整的服务,避免客户应用完全不可服务。
在数据中心设计上 ,AWS选择了两种方案的结合。按照地理位置建立独立的、45万 物理机的超大规模数据中心集群,既保证了规模效应的高性价比,又实现了最终客户良好的网络体验。独立的数据中心集群间只保持较小的互联带宽,避免大范围网络互联的高投资。数据中心集群内,在数据中心间、以及数据中心内设计了很高的互联带宽,实现资源池的统一SLA体验。
2
云主机设计
在2008年的 InternationalConference on Data Engineeringcloud computing imperatives” 大型的数据中心比中型数据中心可以提供7.1倍的网络性价比、5.7倍的存储性价比、以及高达15.7倍的管理成本性价比。同时在计算能力成本日益下降的背景下,发展大型的数据中心,才能解决数据传输高延时与能耗不足的基础设施瓶颈。
AWS云主机网络设计实践
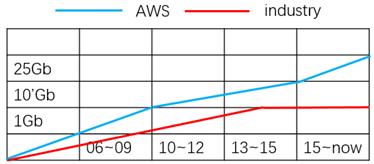
图表 6数据中心内网络演进
从图表6看,AWS的数据中心内网络带宽选择领先业界近3年。在2010年的cg1实例上明确使用10Gb网络,到2015年的x1实例上明确使用25Gb的网络。更高的数据中心内网络带宽,不仅给每个云主机提供更多的带宽资源,最重要的会降低路径上所有网络设备的队列深度,从而得到更低的东西向流量网络延时。
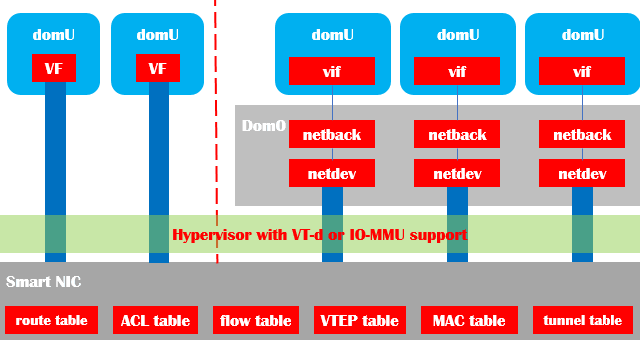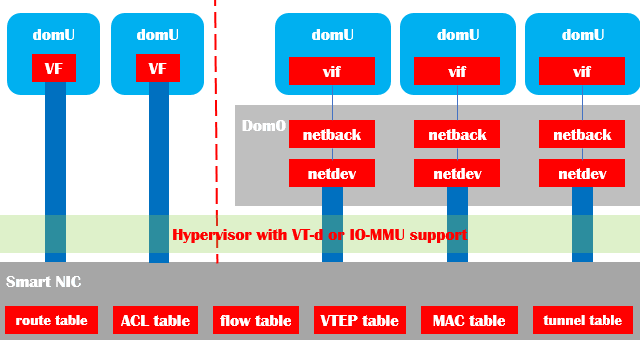
AWS在2011年左右引入了10Gb的智能网卡(驱动兼容Intel的ixgbevf,生产厂商不详),并对所有规格的云主机规格开放,提供普通vif与SRIOV VF两种接口(如图表7)。随后在2015年随x1机型推出了25Gb的智能网卡(使用自有ENA驱动,收购的annapurna设计)。
图表 7智能网卡
智能网卡承担了原本物理机内虚拟交换机的路由、contrack匹配、ACL过滤、VTEP查表、MAC代答、tunnel建立等工作负载,大幅度降低了网络延时,提高了网络吞吐量。同时硬件实现了虚拟机粒度的、严格的带宽以及五元组流的QoS,保证基本所有类型以及规格的云主机都有稳定可预测的网络性能。
AWS的云主机存储设计实践
图表 8云主机存储演进
从图表8看,AWS使用存储介质的策略也相对比业界激进,从2007年开始的c1实例使用了SATA口的SSD,2015年在x1实例上使用了PCIE SSD(在2007年~2015年之间也在少量机型上使用了PCIE SSD,应该是维护困难放弃了,x1实例因为SATA SSD的IOPS能力不够),在2016年底的p2实例上正式推出了NVMe SSD。比业界的选择整体快1~4年。当前NVMe SSD的使用上时间点接近,这个是因为存储技术发展比网络慢很多。
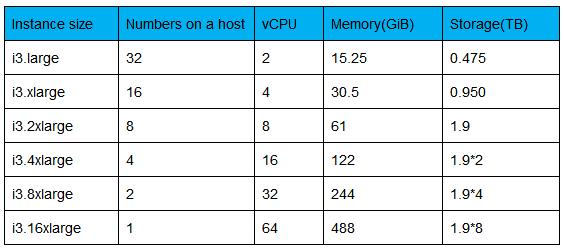
虽然大家都使用NVMe SSD作为存储介质,但从下表可以看出,AWS最新推出的i3实例的物理机挂载8个1.9T的NVMe盘,可以同时承载32个i3.large规格的实例,并且可以保证这些实例的存储SLA。笔者推测推测其在i3实例物理机上使用了类似JBOF中的NVMe controller,将云主机的最多32个NVMe SSD盘的后端卸载到该controller卡上。同时NVMe controller需要对挂载的8个NVMe SSD进行了条带化,从而实现1个NVMe盘同时提供给两个云主机使用,而且有严格的SLA保证。
图表 9 AWS I3实例设计
从AWS在云主机设计的实践看,其完全遵守了前面论文的理论,通过大型数据中心的规模效应来提高资源池的品质。通过全网使用更高带宽的网络技术,以及主机端的智能网卡,实现了比业界大大降低的云主机网络时延。比业界更早的使用更高性能的存储介质,并且通过新的存储卸载技术,大幅度的降低了存储时延,并且提高了存储密度。
从前面图表3中RightScale的统计图我们可以看出,AWS环境中80%以上的实例是小规格的。越来越多的客户倾向与开发微服务架构的应用,通过简单的高扩展的应用架构代替以往复杂的应用架构。AWS的云主机设计策略很明显,在保证整个资源池的计算、网络、存储性能优势以外,还要保证有能力提供足够小的资源颗粒粒度,同时保证这些颗粒有SLA的保证。(AWS曾经有过cc1、cc2等大颗粒实例,但均淘汰了)
从通过智能网卡实现了高密度虚拟网卡,以及精确的QoS控制,保证云主机的网络质量可预测。到使用新的存储卸载技术来提供高密度的虚拟NVMe设备,以及精确的QoS控制,保证云主机的存储质量可预测。我们看到了其为客户提供细粒度资源的思路。
图表 10 AWS实例设计目标(左右滑动)
3
云服务设计
在2002年的IEEEInternational Conference on Data Engineering“Key Challenges inInformation Processing”软件和人为因素是故障的最大原因,而不是硬件设备本身的故障。安全开销只有0.0025%,但经常会发生数据丢失、应用被病毒感染、以及不安全的系统配置。开发者更热衷于优化应用局部性能,而不是提高应用的扩展性,但扩展性好的其实简单架构的应用,运行在不需要人员运维的大型集群上效果会更好。
在2009年的StanfordClean Slate CTO Summit Invited Talk“Data CenterNetworks Are in my Way”传统的网络设备没有像x86服务器架构一样有开放的、标准的架构。运营商无法使用一套OSS系统,对局点内的各类设备进行管理,需要管理员手工进行维护。
AWS云主机服务设计实践
AWS提供了通用云主机、高性能云主机、GPU加速云主机、FPGA加速云主机、存储优化云主机、内存优化云主机等多种云主机规格。用户可以通过其运行一套包含接入、计算、数据落地的完整的应用堆栈,同时适应普通计算、HPC、DNN等各种场景。所有的云主机服务均通过线上console或者API开通,客户选择好相应的云主机规格后,即买即用,用完即走。不需要关心资源集群的运维、安全加固、设备优化等。当然这个在今天很容易理解,但其在2006年,机房托管才是主流商业模式的时候,选择这种超前的商业模式,是需要足够的决策勇气。
图表 11 AWS云主机服务(单击放大)
AWS在虚拟私有网络的设计实践
VPC在前一段时间炒的火热,各个大厂均出来讲自己的实现以及优势。由于热点起源于租户云主机隔离,所以VPC的讨论也局限到隔离的特性。就笔者对AWS的理解,其提出VPC的概念主要目的是为了租户自助管理自己云网络中的各个网元,完成东西、南北向网络流量的配置。
租户通过统一的console或者API自助配置自己网络中的L3交换机,控制流量的路由;
配置网络中的虚拟防火墙,以及交换机ACL,实现流量的安全隔离;
自助选择SNAT网关、公网网关、VPN网关、专线网关等流量流出VPC的方式。
这些特性,极大的简化了租户的运维负担。
图表 12 AWS VPC服务设计(单击放大)
从AWS的云服务设计实践上看,其使用API对客户提供资源服务的思路与这两篇论文思路一致。其修建大规模的数据中心,并优化数据中心的运维质量与成本、提高资源使用效率、提高整体的安全性、实现数据中心的高扩展性。最终通过统一的API与console作为界面,使用自助的云服务屏蔽底层硬件差异,最终将数据中心能力提供给客户。
4
云计算到底是什么
首先来一段 Twilio CEO Jeff Lawson 的定义,笔者认为非常有道理。
Jeff认为在计算领域曾经有两个浪潮,第一个浪潮是以Oracle为代表的公司统治。在这个阶段,是企业的IT部门负责购买软件然后部署管理,以供企业的员工使用。第二个浪潮是以Saleforce为代表的公司统治,企业的销售、营销或者财务部门自己决定购买软件服务,由IT部门帮助管理。目前进入了第三个浪潮时代,这个浪潮是由AWS所统治的。软件企业可以跳过IT部门和业务部门,把他们的技术直接卖给在企业中负责构建应用程序的程序员。
图表 13 研发模式演进
Jeff从软件开发者的角度生动的描述了软件行业的演进历程,在功能交付要求越来越快的背景下,由于软件功能的堆积,软件的体积越来越大,复杂度越来越高,同时软件的质量也越来越难以保证。如图表13,软件开发模式开始从传统的瀑布流模式转化为今天的微服务模式。复杂的单体式软件,拆解为一组简单但高扩展服务。大规模的开发团队,拆解为灵活独立的开发小组。长达半年到1年的交付周期,分解为以周为单位的快速迭代。彻底的D/O分离的协助模式,由于软件的微服务化,软件的业务运维与开发团队融合,形成了新的DevOps模式。
开发模式的演进,对基础设施的要求也在变化。从使用几台高配的服务器部署业务,变化为需要1个,甚至数个低配集群部署,实现各个模块的资源隔离,以及整个业务的高可用。对于有自建数据中心的大型公司来说,可能不是问题,但对于中小型公司来说,这可能是不可能的任务。尤其是对于一些to C的业务,增长曲线无法估计,提前3~5年来规划基础设施的建设,在业务前景还不明朗的时候可能是个笑话。
返回主线,AWS是如何站在第三次计算领域的浪潮之巅呢?
▶AWS在最终客户的周边修建了大型数据中心群,并保证之间的互联质量以及高可用。
▶通过其数据中心的巨型体量,使用各种最新的技术提高了资源的网络、存储效率,解决了功耗问题,同时降低了运维、安全等运营成本。
▶为满足客户的不同计算负载,引入高性能计算、GPU、FPGA等技术,并通过小颗粒的资源粒度,通过统一、可编程的云服务模式提供给客户。
▶最后为了完成客户迁移的工作,提供了一系列搬迁工具、垂直解决方案、服务部署工具、适应新基础设施架构的中间件。
当然这些到现在,也许是每个云计算工程师的常识,但在2006年AWS开始提供云计算服务的时间点,仅有学术界的理论,工程上仍然是无人区。AWS在云计算的巨额投入,这是一场有革命性的、勇敢的赌博。最终在2015年,才最终证明了这次技术革命是成功的。
就此笔者曾向AWS的传奇修车工、卓越工程师、副总裁James Hamilton求证,James的回答:We are both lucky。
图表 14 James的评论
云计算到底是什么呢?
笔者认为云计算是一种新的软件开发模式,所有的租户,也就是软件开发者,以及基础设施提供者都是参与者。软件开发者开发、运营原生的云应用,并对基础设施提出新的需求。基础设施提供者不断的提高资源池整体的扩展性、效率,并降低其成本。同时保证单个资源的小颗粒,以及管理可编程性。
如同芯片平台Intel将芯片技术同等的提交给硬件集成商、通信管道平台华为将通信技术同等的提交给电信运营商、手机软件平台苹果appstore将客户无差别提交给软件开发者、即时通讯平台腾讯将连接提交给广大最终用户。云计算基础设施平台将资源池效率/成本比,无差别的提交给云计算应用开发者,应用开发者的投资最终从基础设施变更到应用开发本身,使云计算分工更明确,决策链条实现闭环迭代式发展。
参考文献
https://en.wikipedia.org/wiki/Cloud_computing 云计算定义
http://docs.aws.amazon.com/general/latest/gr/rande.html AWS Regions and AZs
https://www.youtube.com/watch?v=JIQETrFC_SQ James Hamilton,AWS Innovation at Scale
https://aws.amazon.com/cn/blogs/aws/now-available-i3-instances-for-demanding-io-intensive-applications/ AWS i3 instance specification
https://aws.amazon.com/cn/answers/networking/aws-multiple-Region-multi-vpc-connectivity/
https://aws.amazon.com/ec2/instance-types/?nc1=f_ls
本文作者巩小东,扫码关注他的公众号
你不会想到,他竟来自于AWS的友商
,











免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






