batch系统有什么作用(就不要让自己的兄弟用大于32的mini-batch)
编者按:对于现代深度神经网络的训练来说,如果要用随机梯度下降来收敛,我们一般会选用Mini-Batch,这也是工程界最常用的做法。尽管大批量可以为并行计算提供更多算力空间,但小批量已经被证明了通用性更好,占用内存更少,而且收敛速度更快。那么,常见的mini-batch从几十到几百不等,我们又该怎么往哪个方向调试呢?近日,智能芯片创业公司Graphcore的两位工程师就在论文Revisiting Small Batch Training for Deep Neural Networks中给出了建议——2到32之间。
考虑到CPU在结构上就对2的乘方的batch size不友好,因此本文只针对GPU和专用芯片;另外,论文的实验是在CIFAR-10、CIFAR-100和ImageNet上做的,对时间序列回归可能不太适用。
近来,深度神经网络在许多应用中取得了重大进展,包括计算机视觉、语音识别、自然语言处理,以及用于机器人控制和游戏玩法的强化学习。
(1)
M是训练集样本的总数。上式表示代表真实数据生成分布的损失期望值。
批量梯度下降法(BSD)优化的是参数在整个数据集上的梯度累积情况,而随机梯度下降计算的是基于单个训练样本的参数更新值。现在深度学习领域常用的是带Mini-batch的SGD优化方法,它是这两种思想的融合:先从训练集上选择几个小批量的训练样本,利用单个样本进行多次迭代,把迭代得出的几个梯度进行加权平均并求和。这个和就是该mini-batch的下降梯度。
从数学角度看,就是设训练集的mini-batch为B,每个mini-batch包含m个训练样本。通过计算mini-batch的下降梯度,我们要让它拟合期望值L(θ),然后从中获取参数θ的更新情况:
(2)(3)
其中η是学习率。依据这两个等式,SGD权重更新的平均值是E{η ∆θ} = −η E{∇θL(θ)}。由于batch size是m,所以每个样本权重更新的期望值就是:
(4)
这意味着随着训练迭代的进行,对于同一个batch size m,我们要不断线性增加学习率η来保证每个训练样本平均SGD权重更新能始终保持恒定。
学习率的不同选取对于上节的这个计算结果,本文提出的一个设想是batch size和学习率之间的线性关系其实是不存在的,这其实是用SGD计算mini-batch局部梯度平均值导致的一种假象。
Wilson&Martinez之前在论文中指出,现在我们更新参数用的计算方法是等式(3),它计算的是局部梯度平均值,但以前老版本优化方法计算的却是局部梯度的和。如果我们用θk处的梯度总和来更新参数,那它可以被表示为:
(5)
对于这种方法,如果batch size增加了,我们只需保证学习率η˜的固定就可以保持权重更新恒定。这相当于用了线性缩放规则。对比(2)(3)(5),可以发现新旧版本的区别就在于老版本的学习率η˜=η/m。
如果我们继续设batch size=m,计算从θk处开始到第k n处的权重更新情况,那根据等式(5),它就是:
(6)
这时如果batch size=m n,那k 1处的权重就成了这样:
(7)
对比(6)(7)不难发现,在学习率η˜恒定的情况下,大批量训练基本上可以被看成是小批量训练的近似值,它只是在新旧梯度更替时增加了一些并行性。
上一节我们用平均值时,它给出的结论是用更大的batch size可以提供更“准确”的梯度估计并允许使用更大的学习率。但本节尝试使用总和后,我们可以发现从保持每单位计算成本更新权重的期望值来看,这可能并非如此。实际上,使用较小batch size可以用最新权重梯度,这反过来又允许我们使用更高的基本学习速率,因为每次SGD更新的方差都较低。这两个因素都有可能带来更快更稳健的收敛效果。
实验对比结果本节给出了CNN的一些训练性能的数值结果。更详细的实验过程可以参看原文。研究人员用AlexNet和ResNet两个模型在CIFAR-10、CIFAR100和ImageNet上分别做了测试,对照组为:BN/noBN(有无batch归一化)、Aug/noAug(有无数据增强)、WU(gradual warmup)。
不同batch size训练的模型在CIFAR-10上的不同表现
上图展示了各模型在CIFAR-10上的最佳表现。可以发现,当batch size小于等于32时,各模型的性能还维持在较高水平。对于没有BN的模型,m=2时它们的性能最佳,这和“学习率的不同选取”那一节的分析一致,在batch size较小的情况下,模型能基于最新的梯度信息进行更新,效果更快更稳健。而对于做了BN的模型,它们在m=4和m=8时效果更好。
基础学习率η˜=η/m为各模型提供可靠的收敛效果
上图展示了AlexNet和ResNet两个模型的表现。当batch size逐渐增大,为模型提供稳定收敛的基础学习率η˜=η/m会逐渐减小,这也就说明了为什么用较大的batch size会训练出不太好的结果。此外,论文还推导了BN对模型的影响(本文未翻译此部分,请查询原文),指出每个模型都有一个最优基础学习率η˜,但通常它只能和较小的batch size结合才能实现稳定收敛。这也从侧面表明如果batch size过大,我们很可能会优化出一个错误的学习率,从而影响模型性能。
虽然实验的结果是用小批量来提高模型收敛性和准确性更好,但它也会降低可用的计算并行性。所以当硬件受限时,我们也有综合各个条件慎重考虑。
结论本文通过实验证明,在大规模训练中,对于给定的计算资源,使用小批量可以更好地保证模型的通用性和训练稳定性。在大多数情况下,batch size小于等于32时模型的最终性能较优,而当batch size=2或4时,模型性能可能会达到最优。
如果要进行batch归一化处理,或者使用的是大型数据集,这时我们也可以用较大的batch,比如32和64。但要注意一点,为了保证训练效率,这些数据最好是分布式处理的,比如最好的方法是在多个处理器上分别做BN和随机梯度优化,这样做的优势是对于单个处理器而言,这其实还是在做小批量优化。而且根据文章的实验,BN的最优batch size通常比SGD的还要小。
Yann LeCun读完这篇论文后,抑制不住内心的激动,在twitter上写了一句话:
过大的minibatch有害身心
更重要的是
它还会导致训练error
所以是朋友,就不要让自己的朋友用大于32的mini-batch!
,

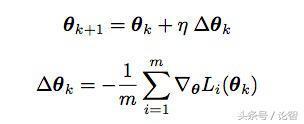






免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






