mbl最长的连胜纪录(他们创造了横扫NLP的XLNet)
机器之心原创
作者:李泽南、思源
Transformer XL 和 XLNet 是最近自然语言处理(NLP)领域里最热的话题之一,而它们都是 CMU 博士生 戴自航、杨植麟等人的工作。今年 6 月,CMU 与谷歌大脑提出的 XLNet 在 20 个任务上超过 BERT,并在 18 个任务上取得当前最佳效果的表现。作为这些研究的核心作者,来自卡耐基梅隆大学(CMU)的杨植麟刚刚进行完博士论文的毕业答辩。在进入 CMU 之前,杨植麟本科毕业于清华大学计算机科学与技术系,满分通过了所有程序设计课程,还曾创立摇滚乐队 Splay,担任鼓手和创作者之一。
杨植麟师从苹果 AI 负责人 Ruslan Salakhutdinov,并曾经效力于谷歌大脑研究院和 Facebook 人工智能研究院,与多位图灵奖得主合作发表论文。他博士四年期间的研究曾在 30 多个数据集上取得历史最好结果 (state-of-the-art),包括自然语言推理、问答、文本分类、半监督学习、文档排序等,产生了较广泛的影响力。
近日,机器之心与杨植麟进行了对话,内容有关 Transfomer XL、XLNet 的产生过程和技术思考,以及他共同创办的科技公司 Recurrent AI。
鲜为人知的是,XLNet 的提出竟然是源于一次拒稿。「我们当时把 Transformer XL 的论文提交到了 ICLR 2019 大会,论文却被拒了,」杨植麟表示。「其实模型的效果非常好——在所有主流语言预训练模型的数据集上都是 state of the art,而且提升非常大。但当时被拒的理由其中很重要的一点是:论文评审觉得,做语言模型没有意义。」
随着 Transformer-XL 越来越受到关注,由它衍生的 XLNet 效果惊人,这让我们重新思考对语言模型研究的「意义」到底如何评价。
最强语言模型是如何诞生的
语言模型研究的重新思考
「审稿人认为 Transformer-XL 提升了语言建模的效果,但是没有证明在任何应用上有提升——当时自航和我处于一个比较矛盾的时刻」,杨植麟介绍到,「一方面语言建模是一个古老的问题,有大量的研究和进展;另一方面除了做无条件文本生成之外没有太多直接的应用。原本预训练是一个很好的应用场景,但是因为标准语言模型没办法对双向上下文进行建模,人们转而集中于自编码思想的研究。」
换句话说,Transformer-XL 的审稿意见引出了这样的矛盾:一个大家做了很长时间的问题,其价值突然遭到质疑。
杨植麟表示,XLNet 的初衷是复兴语言建模,证明更好的语言模型能在下游任务上带来更好的效果。「我们希望能提出一个框架,连接语言建模方法和预训练方法,这样语言建模方法的提升就可以通过预训练直接提升下游任务。」
「研究中很有意思的一点是要根据不完整的信息选择研究方向,而选择的结果往往难以预测。Hinton 等人对深度学习的坚持就是一个成功的例子,因为在那之前很少人相信深度学习会有效果。」
「具体到 XLNet,我们就是在不完整信息的情况下,判断语言建模是一个正确的方向。这样判断的原因有两个,一是如果衡量序列中被建模的依赖关系的数量,基于自回归思想的语言建模目标函数可以达到上界,因为不依赖于任何独立假设;二是语言建模任务的提升意味着模型的提升,所以很有可能在预训练上表现更好。最后 XLNet 的结果证明我们的判断是对的。」
这就是 XLNet 提出背后的心路历程。
算力和算法的关系
不过事情也有另一面:对于研究人员来说,训练 XLNet 时耗费多少算力从来不成问题。杨植麟表示,因为与谷歌合作,其实在研究过程中他们是感知不到算力问题的。「我们没有使用谷歌云,而是使用了谷歌内部的计算集群,」杨植麟介绍道。「在这里,没有人会关心算力的价格,基本可以忽略不计。其实像 XLNet 这种量级的工作,在谷歌内部还挺多的,还有很多项目用到的算力比 XLNet 大。」
花费数万美元成本训练最强大模型是近年来 NLP 领域里经常发生的事情。杨植麟认为,依靠算力解决问题是当前研究 AI 的王道:让计算机去做它的强项——计算;如果算力解决不了的问题,再用算法去做。
「我读过人工智能先驱 Richard Sutton 几个月前的文章《苦涩的教训》,它的大意是说:你如果纵观 70 年的 AI 发展历程,就会发现以算力为杠杆的通用方法是最有效的,」杨植麟说道。「从深蓝、AlphaGo 到 NLP 最近的进展都遵循了这个思路。所以我们要做的事情就是:一方面把算力推到极致,另一方面发明和提升通用算法,解决更难的问题。XLNet 可以理解成这两方面的一个结合。」
「把算力推到极致的好处是知晓当前算法的边界,避免在算力可以解决的问题上做一些不必要的算法创新,让大家关注最重要的研究问题。但同时大算力带来的弊端是提升了研究门槛,比如一般的学校和实验室可能没有资源做预训练。这个问题我觉得短时间内要通过不同的分工来解决,资源多的研究者利用资源做大算力研究,资源少的研究者做基于小算力的研究。」
此外,最近 Facebook 提出来的 RoBERTa 也体现了这一点,杨植麟说:「现在预训练的提升主要来自两个方面,一个是算法和模型,一个是训练细节、数据和算力。RoBERTa 表明了第二个方面的重要性,而 XLNet 一方面证明了在训练细节、数据和算力都差不多的情况下算法可以提升效果,一方面探索了增加训练数据的重要性。这两个方向是互补的,而且未来的发展还会持续在两个方向上提升。」
「很多历史上优秀的工作比如 GAN 和 Transformer 都不需要特别大的算力;刘寒骁等人的可导网络结构搜索影响力很大,但就只用了三四个 GPU;我们的 Transformer-XL 最开始也是用一两个 GPU 就在中等数据集上验证了效果会比 RNN 好接近十个点。」
XLNet 的思考与做法
那么从 Transformer-XL 到 XLNet 最核心的思想到底是什么样的,语言模型未来又该如何发展?杨植麟向机器之心介绍了构建 XLNet 的核心思考与做法,整篇论文最精华的地方也就在这里。
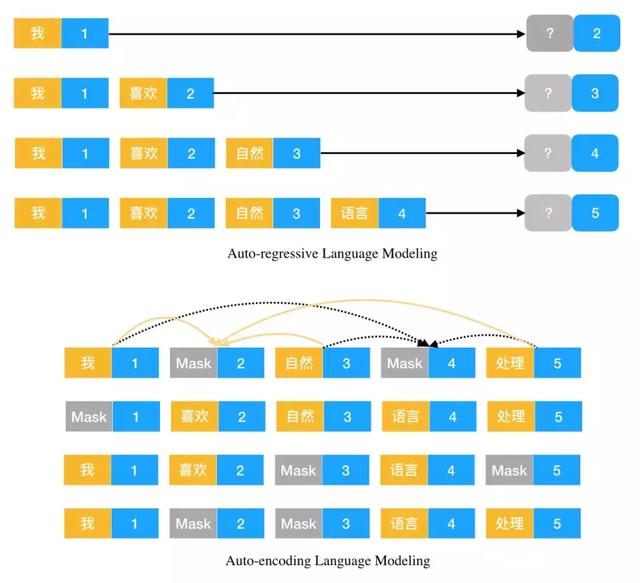
我们希望从三个方面出发介绍 XLNet,即 XLNet 是怎样想的、怎样做的,它又该如何提升。在这之前我们希望读者能先了解自回归和自编码两种模式的语言模型:
如上所示分别为自回归模型与自编码模型,其中黄色块为输入字符,蓝色块为字符的位置。对于自回归语言模型,它希望通过已知的前半句预测后面的词或字。对于自编码语言模型,它希望通过一句话预测被 Mask 掉的字或词,如上所示第 2 个位置的词希望通过第 1、3、5 个词进行预测。
我们需要更好的语言建模任务
以前,最常见的语言模型就是自回归式的了,它的计算效率比较高,且明确地建模了概率密度。但是自回归语言模型有一个缺陷,它只能编码单向语义,不论是从左到右还是从右到左都只是单向语义。这对于下游 NLP 任务来说是致命的,因此也就有了 BERT 那种自编码语言模型。
BERT 通过预测被 Mask 掉的字或词,从而学习到双向语义信息。但这种任务又带来了新问题,它只是建模了近似的概率密度,因为 BERT 假设要预测的词之间是相互独立的,即 Mask 之间相互不影响。此外,自编码语言模型在预训练过程中会使用 MASK 符号,但在下游 NLP 任务中并不会使用,因此这也会造成一定的误差。
为此,杨植麟表示我们需要一种更好的预训练语言任务,从而将上面两类模型的优点结合起来。XLNet 采用了一种新型语言建模任务,它通过随机排列自然语言而预测某个位置可能出现的词。如下图所示为排列语言模型的预测方式:
如上排列语言示例,因为随机排列是带有位置信息的,所以扰乱顺序并不影响建模效果。随机排列语言后,模型就开始依次预测不同位置的词。
如果我们知道所有词的内容及位置,那么是不是顺序地分解句子并不太重要。相反这种随机的分解顺序还能构建双向语义,因为如上利用「语言」和「喜欢」预测「处理」就利用了上下文的词。如下原论文展示了不同分解顺序预测同一词的差别,如果第一个分解的词的「3」,那么它就只能利用之前的隐藏状态 mem 进行预测。
这理解起来其实也非常直观,如果我们知道某些词及词的位置,那么完形填空式地猜某个位置可能出现哪些词也是没问题的。此外,我们可以发现,这种排列语言模型就是传统自回归语言模型的推广,它将自然语言的顺序拆解推广到随机拆解。当然这种随机拆解要保留每个词的原始位置信息,不然就和词袋模型没什么差别了。
我们需要更好的结构
前面我们为预训练语言模型构建了新的任务目标,这里就需要调整 Transformer 以适应任务。如果读者了解一些 Transformer,那么就会知道某个 Token 的内容和位置向量在输入到模型前就已经加在一起了,后续的隐向量同时具有内容和位置的信息。但杨植麟说:「新任务希望在预测下一个词时只能提供位置信息,不能提供内容相关的信息。因此模型希望同时做两件事,首先它希望预测自己到底是哪个字符,其次还要能预测后面的字符是哪个。」
这两件事是有冲突的,如果模型需要预测位置 2 的「喜欢」,那么肯定不能用该位置的内容向量。但与此同时,位置 2 的完整向量还需要参与位置 5 的预测,且同时不能使用位置 5 的内容向量。
这类似于条件句:如果模型预测当前词,则只能使用位置向量;如果模型预测后续的词,那么使用位置加内容向量。因此这就像我们既需要标准 Transformer 提供内容向量,又要另一个网络提供对应的位置向量。
针对这种特性,研究者提出了 Two-Stream Self-Attention,它通过构建两条路径解决这个条件句。如下所示为 Two-Stream 的结构,其中左上角的 a 为 Content 流,左下角的 b 为 Query 流,右边的 c 为排列语言模型的整体建模过程。
在 Content 流中,它和标准的 Transformer 是一样的,第 1 个位置的隐藏向量 h_1 同时编码了内容与位置。在 Query 流中,第 1 个位置的隐向量 g_1 只编码了位置信息,但它同时还需要利用其它 Token 的内容隐向量 h_2、h_3 和 h_4,它们都通过 Content 流计算得出。因此,我们可以直观理解为,Query 流就是为了预测当前词,而 Content 流主要为 Query 流提供其它词的内容向量。
上图 c 展示了 XLNet 的完整计算过程,e 和 w 分别是初始化的词向量的 Query 向量。注意排列语言模型的分解顺序是 3、2、4、1,因此 Content 流的 Mask 第一行全都是红色、第二行中间两个是红色,这表明 h_1 需要用所有词信息、h_2 需要用第 2 和 3 个词的信息。此外,Query 流的对角线都是空的,表示它们不能使用自己的内容向量 h。
预训练语言模型的未来
除了 XLNet 最核心的思考与做法,杨植麟还从少样本学习、数据、模型架构和结构一体化四大方面谈论了预训练语言模型更多的可能性。
1.少样本学习
目前预训练方法在下游任务上依然需要相对多的样本来取得比较好的结果,未来一个重要的研究方向是如果在更少数据的下游任务上也能取得好效果。这需要借鉴一些 few-shot learning 的思想,不仅仅对从输入到输出的映射进行建模,还要对「这个任务是什么」进行建模,这也就意味着需要在预训练的时候引入标注数据,而不仅仅是无标注数据。
2.数据哪能越多越好
早几天 XLNet 团队公平地对比了 BERT-Large 和 XLNet-Large 两个模型,他们表示尽管 XLNet 的数据是 BERT 的 10 倍,但算法带来的提升相比于数据带来的提升更大。杨植麟说:「我认为并不是数据越多越好,我们的 XLNet 基本上将手头有的数据都加上去了,但我们需要做更仔细的分析,因为很可能数据质量和数量之间会有一个权衡关系。」
具体而言,杨植麟表示:「BERT 所采用的 BooksCorpus 和 English Wikipedia 数据集质量都非常高,它们都是专业作者书写的文本。但是后面增加的 Common Crawl 或 ClueWeb 数据集都是网页,虽然它们的数据量非常大,但质量会相对比较低。所以它们的影响值得进一步探索,如何在数据数量和质量之间取得一个好的平衡是一个重要的课题。另外,细分领域的训练数据是十分有限的,如何在预训练的框架下做 domain adaptation 也是一个重要问题。」
3.模型还是挺有潜力的
在预训练语言模型上,杨植麟表示还有 3 个非常有潜力的方向。首先即怎样在 Transformer 架构基础上构建更强的长距离建模方式,例如这个月 Facebook 提出的 Adaptive Attention Span 和杨植麟之前提出的 Transformer-XL 都在积极探索。
其次在于怎样加强最优化的稳定性,因为研究者发现在训练 Transformer 时,Adam 等最优化器不是太稳定。例如目前在训练过程中,一定要加上 Warm up 机制,即学习率从 0 开始逐渐上升到想要的值,如果不加的话 Transformer 甚至都不会收敛。这表明最优化器是有一些问题的,warm up 之类的技巧可能没有解决根本问题。
最后模型可提升的地方在于训练效率,怎样用更高效的架构、训练方式来提升预训练效果。例如最近天津大学提出的 Tensorized Transformer,他们通过张量分解大大降低 Muti-head Attention 的参数量,从而提高 Transformer 的参数效率。
4.编码器-解码器的一体化
杨植麟表示,XLNet 的另一大好处在于它相当于结合了编码器和解码器。因此理论上 XLNet 可以做一些 Seq2Seq 相关的任务,例如机器翻译和问答系统等。
首先对于 Encoder 部分,XLNet 和 BERT 是一样的,它们都在抽取数据特征并用于后续的 NLP 任务。其次对于 Decoder,因为 XLNet 直接做自回归建模,所以它对任何序列都能直接输出一个概率。这种 Decoder 的性质是 BERT 所不具有的,因为 BERT 所输出的概率具有独立性假设,会有很多偏差。
杨植麟说:「如果我们用 XLNet 来做机器翻译,那么一种简单做法即将 Source 和 Target 语言输入到 XLNet。然后将 Target 那边的 Attention Mask 改成自回归的 Attention Mask,将 Source 那一部分的 AttentionMask 改成只能关注 Source 本身。这样我们就能完成 Seq2Seq 的任务。」
Recurrent AI:用最强技术赋能人类沟通
博士毕业的杨植麟目前正在北京全职创业,他是一家 AI 创业公司的联合创始人。他共同创立的睿科伦智能(Recurrent AI)致力于使用最先进的自然语言处理和语音识别技术解决人类沟通的痛点。具体而言,公司目前专注于提供企业服务,提升销售渠道的效率和销售转化率。
这家公司推出了 DealTape(交易磁带)智能销售系统,希望能够从统计分析的角度帮助人们进行分析:在不同的商业背景下,哪些语言对于销售产生了积极的影响,哪些产生了消极的影响。这些产品目前在教育金融和互联网行业都已有了最标杆的客户。
「针对教育机构,我们可以通过全渠道的沟通数据评估哪些线索更容易转化,从而帮助销售顾问去及时触达,」杨植麟介绍道。「我们可以精准地、结构化地抽取用户画像,帮助客服人员选择更好的表达方式,获得更高的转化率。更进一步地,我们可以分析客户需求占比,帮助管理者进行产品迭代。」
Recurrent AI 希望打造一种 AI 销售中台,收集全渠道的语义文字沟通数据,然后输出整套销售解决方案和销售能力。在这家公司的愿景中,「使用 State-of-the-art 的黑科技赋能人类沟通」是其中重要的一环,杨植麟表示,现在公司的整套语音识别系统以及 NLP 模型,现在都已用上了 Transfomer XL。
,





免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






