电音乐谱制作教程(MusiicVAE化身音乐家混合乐谱的调色板)

原文来源:magenta
作者:Adam Roberts、Jesse Engel、Colin Raffel、Lan Simon、Curtis Hawthorne
「雷克世界」编译:嗯~是阿童木呀、KABUDA
一般来说,当画家创作一件艺术品时,在下笔之前,她首先会在调色板上对颜色选项进行混合并探索。这一过程本身就是一种创造性的行为,并且对最终的作品有着深远的影响。
获取音频:https://magenta.tensorflow.org/assets/music_vae/mel_2bar-dumsamp.mp3
潜在空间模型能够学习训练数据集的基本特征,因此可以排除这些非常规的可能性。将这些2节拍旋律的潜在空间中的随机抽样点的与以前的那些进行比较:

获取音频:https://magenta.tensorflow.org/assets/music_vae/mel_2bar-samp.mp3
排除不切实际的样本外,潜在空间能够表示低维空间中真实数据的变化。这意味着它们也可以重建具有高精确度的真实样本。此外,当压缩数据集的空间时,潜在空间模型倾向于基于基本质量对其进行组织,将相似的样本聚集在一起,并根据这些质量所定义的向量列出变化。
潜在空间的理想特性可以总结如下:
1.表达性(Expression):任何真实的样本都可以映射到潜在空间中的某个点并从中进行重构。
2.真实感(Realism):这个空间中的任何一点都代表了一些实际样本,那些不在训练集中的样本也涵盖在内。
3.流畅性(Smoothness):潜在空间附近点的样本具有相似的性质。
这些属性类似于艺术家的调色板,她可以在该调色板上对颜色选项进行探索和混合,从而进行创作,而且更像调色板的一点是,这些属性可以增强创意。例如,由于Expression和Smoothness,一个潜在的空间,比如由SketchRNN学习的笔画序列,使得你能够通过在潜在空间中的点之间的插值以进行重建和融合:

Realism使得你能够通过对潜在空间中随机选取的点进行解码,从而随机抽取一些与你的数据集中样本相类似的样本。我们在上面演示了这种旋律,并在这里用SketchRNN示范一下:

我们还可以使用潜在空间的结构来执行语义上有意义的转换,例如“潜在约束”或“属性向量算术”。后一种技术利用了这一事实,即潜在空间可以“解开”数据集中的重要特征。通过对与共享给定质量的数据点集合相对应的潜在向量进行平均(例如,猫脸的草图),我们获得该属性的属性向量(“猫脸向量”)。通过从潜在代码中加入和减去各种属性向量并使用我们的模型进行解码,我们可以获得添加或删除相关属性的输出。再次,我们用SketchRNN来说明这一点:
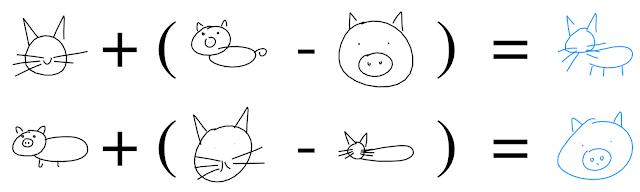
如何学习一个潜在空间
有许多不同的模型能够学习潜在的表示,每种模式都与我们所期望的三种属性有各种各样的折中。
这样的模型的一种被称为自动编码器(AE)。自动编码器通过学习将每个样本压缩(编码)为数字向量(潜在代码或z),然后从该数字向量重新生成(解码)为相同样本,从而构建数据集的潜在空间。AE的一个关键组成部分是通过使向量具有比数据本身更小的维度而引入的瓶颈,这迫使模型区学习一个压缩方案。在这个过程中,自动编码器以理想的形式提取整个数据集中通用的性质。NSynth是一个自动编码器的例子,它在音符的音频中学习了音色的潜在空间:

这种类型的自动编码器的一个局限性在于,它的潜在空间中通常存在“漏洞”。这意味着如果你对一个随机向量进行解码,它可能不会产生任何实际的结果。例如,NSynth能够进行重构和插值,但由于这些漏洞,它缺乏真实性和随机采样能力。
另一种加强瓶颈限制的方式是使用所谓的变分损失(variational loss)。它不是不是限制向量的维度,而是鼓励编码器产生具有预定义结构的潜在代码,例如来自多变量正态分布的样本。然后,通过构造具有这种结构的新代码,我们可以确保解码器产生一些具有实际意义的东西。
SketchRNN是一个变分自动编码器(VAE)的例子,它学习了一个用笔画序列表示的草图的潜在空间。这些笔画由双向循环神经网络(RNN)编码并由单独的RNN自动解码。正如我们上面看到的,这个潜在空间具有我们所需的所有属性,部分归功于变分损失。
循环潜在空间
通过Music VAE,我们开始使用与Sketch RNN非常相似的体系结构以学习包含所有属性在内的旋律片段(循环)的潜在空间。我们在这里用一些例子来展示我们的结果。
首先,我们将展示我们在两个序列间的变形能力,正如我们所做的那样,中和它们的属性。 尽管我们展示了一个混合两首旋律的样本,但我们前期做了一些更有难度的事情,进而将bassline转变为旋律。
Bassline音频连接:The red segment is the first step of the interpolation, and the purple is the final one. Each segment is 4 seconds (2 bars).
Melody音频连接:https://magenta.tensorflow.org/assets/music_vae/mel_2bar-mel.mp3
我们首先尝试在不使用MusicVAE的情况下,通过对两者之间的音符进行采样,类似于音频中的交叉衰减(cross-fading),来流畅地将bassline转化为旋律。你可以在下面听到这个朴素插值的结果。第一部分(黑色)是bassline,后一部分(黑色)是旋律。红色部分是插值的第一步,紫色部分是插值的最后一步,每段为4秒(2节拍)。

获取音频:https://magenta.tensorflow.org/assets/music_vae/mel_2bar-b0m.mp3
尽管开始(红色)和结束(紫色)部分完全匹配原来的序列,但中间那部分是无效的旋律和bassline。附近确实存在类似的音符,但较高阶的音质丢失了。输出空间有表达性,但缺乏真实感和流畅性。另一方面,下面是通过MusicVAE潜在空间的插值进行的变形。

获取音频:https://magenta.tensorflow.org/assets/music_vae/mel_2bar-b2m.mp3
需要注意的是,中间序列现在是有效的,它们之间的转换是流畅的。中间序列也不像像之前那样局限于原文件中的音符,而在端点的上下文中选择音符使得整体更具音乐感。在这一样本中,我们完全满足了表达性、真实感和流畅性的特性。
我们还在鼓循环中训练了这种架构,取得了类似的结果。

长期结构
其中一种位置语言模型(如MelodyRNN和PerformanceRNN)的不足之处在于它们产生的输出通常缺乏连贯的长期结构。正如我们过去用SketchRNN所展示的那样,潜在空间模型可以编码长期结构以生成完整的草图。
然而,要想在长音乐序列中获得类似的结果,通常要有比草图更多的步骤,我们发现不能依靠相同的体系结构。相反,我们开发了一种全新的分层解码器,能够从单个潜在代码生成长期结构。
我们不是使用我们的潜在代码来直接初始化音符RNN(note RNN)解码器,而是先将代码传递给一个“导体”RNN,该RNN为每个输出节拍输出一个新的嵌入。然后,音符RNN基于嵌入而不是潜在代码本身,独立生成16个节拍中的每一个,然后我们从音符解码器中进行自回归采样。
我们发现这种条件独立性是我们体系结构的一个重要特征。由于该模型不能简单地回归到音符解码器中的自回归以优化训练期间的损失,所以它更依赖潜在代码以重建序列。
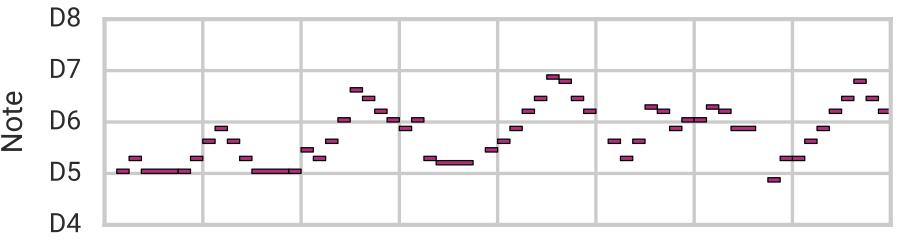
使用这种体系结构,我们可以像以前一样进行重建、采样和平滑插值,但现在需要更长的时间(16节拍)旋律。在本文中,我们将样本旋律A(顶部)与B(底部)混合在一起。

获取音频:https://magenta.tensorflow.org/assets/music_vae/mel_16bar-a.mp3

获取音频:https://magenta.tensorflow.org/assets/music_vae/mel_16bar-2.mp3

获取音频:https://magenta.tensorflow.org/assets/music_vae/mel_16bar-mean.mp3
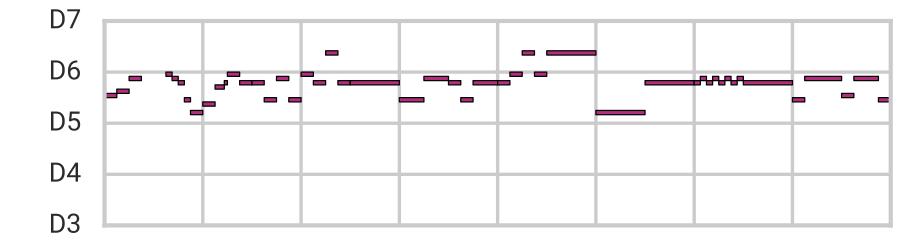
获取音频:https://magenta.tensorflow.org/assets/music_vae/mel_16bar-6.mp3
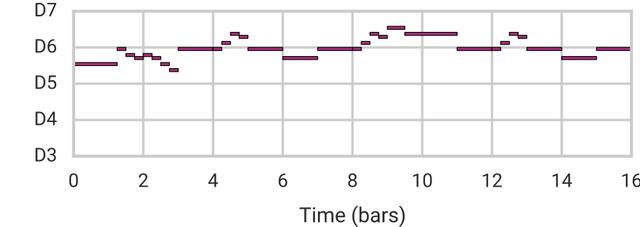
获取音频:https://magenta.tensorflow.org/assets/music_vae/mel_16bar-b.mp3
此外,我们可以使用属性向量算法(上面提到的“猫脸向量”)来控制音乐的特定品质,同时保留音乐的许多原始特征,包括整体结构。在本文中,我们展示了我们通过在潜码中添加或减去一个“音符密度向量”来调整旋律中音符数量的能力。
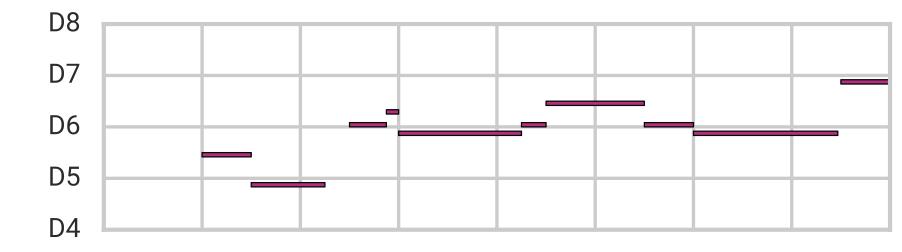
获取音频:https://magenta.tensorflow.org/assets/music_vae/attr-lo.mp3
获取音频:https://magenta.tensorflow.org/assets/music_vae/attr-orig.mp3

获取音频:https://magenta.tensorflow.org/assets/music_vae/attr-hi.mp3
需要注意的是,我们并不是通过简单重复音符来增加它们的密度。相反,Music VAE增加了琵琶和其他与音乐相关的用户体验。
重新组建乐队
我们可以用短期和长期结构来模拟单个乐器,我们调整了我们的分层架构以对不同乐器之间的相互作用进行建模。在这些模型中,我们将嵌入传递给多个解码器、每个乐器或每个轨道,而并非是将嵌入从导管传递至单个音符解码器。
通过在潜在空间中对简短的多乐器配置进行表示,我们可以完成所有与单曲操作相同的操作。例如,对于8种完全不同的乐器,我们可以在两个1度量配置之间进行差值。下面是由模型选择的乐器,在潜在空间中随机点对之间的两个插值合成的音频。每个点代表2秒(1节拍)。
获取音频1:https://magenta.tensorflow.org/assets/music_vae/multi_1bar-slerp0.mp3
获取音频2:https://magenta.tensorflow.org/assets/music_vae/multi_1bar-slerp5.mp3
我们还可以将跨节拍的层次结构,重新添加到模型3的标准乐器(旋律、低音、鼓声)中的16个节拍。我们“trio”模型中的这个样本播放列表(https://www.youtube.com/watch?v=xU1W3c9p2RU&feature=youtu.be&list=PLBUMAYA6kvGVds2N7HIMQnZc0SMFk99Yl)证明,它已经学会了如何在长时间帧内模拟三种乐器之间的交互作用。
音乐家的工具
可以说,我们是刚刚触及对于音乐家、作曲家及音乐制作人来说,由MusicVAE所学习的音乐调色板的可能应用的表面,并且已经开始与开发人员合作,让尽可能多的人访问这些调色板。

第一个样本是由谷歌创意实验室的技术人员制作的旋律混音器,可以让人轻而易举地在短旋律循环之间轻松生成插值。
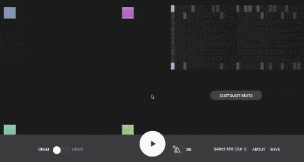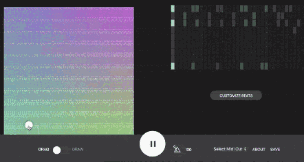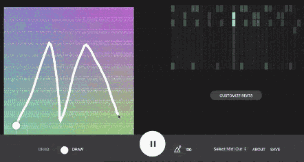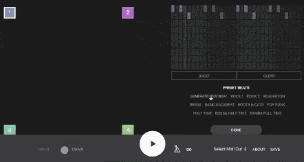
第二个样本是Beat Blender,也是由谷歌创意实验室开发的。你可以使用它来生成鼓点的二维调色板,并通过潜在空间绘制路径,以创建不断变化的节拍。4个角可以手动编辑,替换为预设或从潜在空间采样以重新生成调色板。

第三个样本是谷歌Pie Shop的潜在循环(Latent Loops)。Latent Loops让你可以在调整到不同音阶的矩阵上勾勒旋律,探索生成旋律循环的调色板,并使用它们对更长的乐曲进行排序。
有了这个,音乐家就可以用这个界面创造出完整的旋律线,然后很容易地将它们转移到他们的音频工作站(DAW)上,进行创作。
原文链接:https://magenta.tensorflow.org/music-vae
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com