r语言数据分析常用函数(R语言34)
在许多应用中,数据可能分散在许多文件或数据库中,存储的形式也不利于分析;通过数据规整聚,可以实现数据的聚合、合并、重塑及分组。
在R语言中进行数据分析处理的二维表格的经典数据结构:
data.frame:最基本,大多函数的设计基于此种结构;读写速度一般
data.table:在data.frame上的改进,读写速度最快;加入了索引操作,结合索引数据处理更方便
tibble:主要在dplyr和tibble包中有效,主要关注于列list,支持整洁格式;数据进行懒加载
涉及到的相关包:
- dplyr 数据处理:dplyr包定义了tbl类型,作为实际数据源的包装类型。它封装数据源病提供了一组统一的方法操作数据,该包当前支持的数据源包括:标准数据框(以tibbles的形式)、几个数据库管理系统以及其他数据源。
- tidyr 数据清理
- purrr 函数化编程
- tibble 数据类型定义:tibble包括定义tibble为特定的数据框,它改变了标准数据框的一些行为;两者主要差异主要包括三点:
- tibble 不会像数据框一样默认改变字符串列为因子类型;
- tibble 对列的命名要求更宽松;
- tibble 的打印方法对大数据集特别方便。
tibble对data.frame做了重新的设定:
- 不关心输入类型,可存储任意类型,包括list类型
- 没有行名设置 row.names
- 支持任意的列名
- 会自动添加列名
- 类型只能回收长度为1的输入
- 会懒加载参数,并按顺序运行
- 是tbl_df类型
Tidyverse之dplyr
Tidyverse是R语言的一个程序包;Tidy的意思是干净、整洁,Verse的意思是诗歌、歌曲,Tidyverse的意思就是干净整洁的语句。而dplyr包可以看作是plyr包的一个扩展,主要是针对数据框的数据操作;在使用dplyr包中的函数对数据框进行操作之间,最好将其转换为tbl对象。
dplyr用于数据规整,堪比瑞士军刀;dplyr有许多方便的函数,非常建议将它用于数据分析:
- select() 提取列并返回一个tibble。
- arrange() 更改行的顺序。
- filter() 根据其值选择行。
- mutate() 添加作为现有变量函数的新变量。
- rename() 轻松更改列的名称
- summarise() 将多个值减少到单个摘要。
- pull() 提取单个列作为向量。
- _join()的两个数据帧合并到一起的函数组,包括(inner_join(),left_join(),right_join(),和full_join())。
dplyr提供了很多函数可以很容易处理tbl数据对象;如何查询数据?可以利用select() 和 filter() 函数实现,前者过滤列,后者过滤行。
Tidyverse 之Tidyr
Tidyr的目的是拥有组织良好或整洁的数据,Tidyverse将tidydata其定义为:
- 每个变量作为一列
- 每个观测作为一行
- 每个值占一个单元格
Tidyr有两个主要函数,gather()和spread()。这些函数允许在长数据格式和宽数据格式之间进行转换。
gather()函数将宽数据格式更改为长数据格式。
spread()函数与gather()函数相反。key列的类别将成为单独的新列,value列中的值将根据关联的key列进行拆分。

「链接」
reshape2也可以实现数据的“长、宽”转换reshape2包是由Hadley Wickham开发的一个R包,从其命名不难看出,reshape2包可以对数据重塑,就像炼铁一样,先融化数据,再重新整合数据,它的主要功能函数为cast()和 melt(),实现了长数据格式与宽数据格式之间的相互转换。
melt.list()函数能够递归地拆分列表元素。
ccc<-c(1:10,c(NA,2,3,4))
ccclist<-as.list(ccc)
melt(ccclist)
cast()函数具有两种形式:
- dcast() :输出为数据框
- acast() :输出为向量、矩阵、数组
#产生一个df
#省略四个变量的输入
a<-data.frame(name,gender,age,height)
b <- aggregate(a[,3:4], by=list(gender=gender), FUN=mean)
a;b

ACF(自相关系数)和pacf(偏自相关系数)
acf的全称是AutoCorrelation Function,即自相关函数。但这个函数不仅可以计算自相关,也可以计算自协方差。
1、画图,acf(ts)、pacf(ts)
举例:
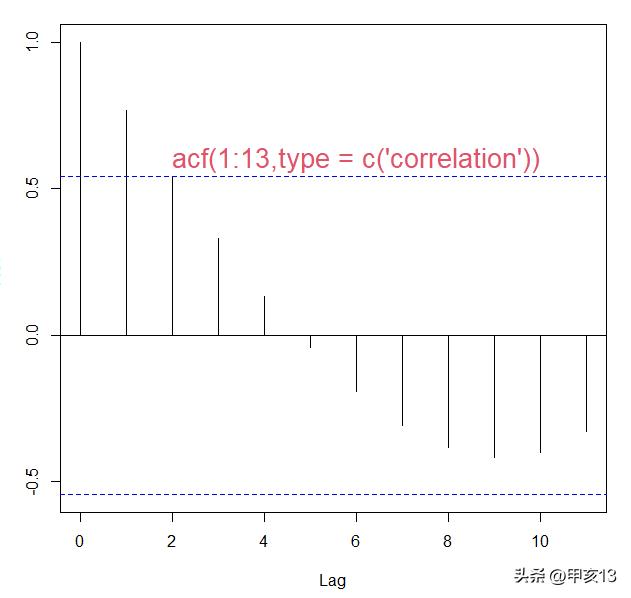
2、数值,acf(ts)$acf、pacf(ts)$acf
#举例
> acf(1:13,type = c("correlation"))$acf
, , 1
[,1]
[1,] 1.00000000
[2,] 0.76923077
[3,] 0.54395604
[4,] 0.32967033
[5,] 0.13186813
[6,] -0.04395604
[7,] -0.19230769
[8,] -0.30769231
[9,] -0.38461538
[10,] -0.41758242
[11,] -0.40109890
[12,] -0.32967033
> summary(acf(1:13,type = c("covariance")))
Length Class Mode
acf 12 -none- numeric
type 1 -none- character
n.used 1 -none- numeric
lag 12 -none- numeric
series 1 -none- character
snames 0 -none- NULL
>
> summary(pacf(1:13,type = c("correlation")))
Length Class Mode
acf 11 -none- numeric
type 1 -none- character
n.used 1 -none- numeric
lag 11 -none- numeric
series 1 -none- character
snames 0 -none- NULL

3、自相关含义解释:
自己 与 自己的过去 是否具有线性相关?
范围是-1~1;绝对值越靠近1越相关,绝对值越靠近0越不相关。
当纵线落入虚线以内,则认为该数值与0无显著差异,即可认为不相关。
4、深层次用法:
在时间序列分析过程中,一种分析手段是:根据 自相关系数图 和 偏自相关系数图 来猜测时间序列可能属于哪一种时间序列模型。
故需要分析人员大量浏览各种可能的已知时间序列模型,并熟悉他们的自相关系数图(acf函数)、偏自相关图(pacf函数);并结合扩展的自相关函数(eacf函数,Tsay,Tia0,1984 W.S.Chan.1999 )实现模型定阶,注意——eacf的使用,必须先library(TSA)。
|
AR(p) |
MA(q) |
ARMA(p,q) | |
|
ACF |
拖尾 |
q阶截尾 |
拖尾 |
|
PACF |
p阶截尾 |
拖尾 |
拖尾 |
拖尾的话,ar模型或者arma模型;
截尾的话,ma模型;根据超出两倍标准差的阶数,确定移动平均模型的阶数。
或者,可以用auto.arima函数,或者TSA包的eacf函数,确定阶数。
5、关于eacf的补充
计算存储在 z 中的时间序列的样本扩展 acf (ESACF)。ESACF 的矩阵,其 AR 阶最高为 ar.max,MA 阶最高为 ma.max,存储在矩阵 EACFM 中。
eacf(z, ar.max = 7, ma.max = 13)
|
z |
时间序列数据 |
|
ar.max |
最大 AR 订单;默认=7 |
|
ma.max |
最大 MA 订单;默认=13 |
#简单
> data(arma11.s)
> arma11.s
Time Series:
Start = 1
End = 100
Frequency = 1
[1] -0.764596332 1.297195966 0.668426838 -1.607385082 -0.626004808
[6] 1.484327417 1.885497663 -0.009316681 -0.339675938 -0.972070263
[11] -1.867989789 0.894912243 2.638806318 2.946696256 2.877056296
[16] 1.162570774 0.930328598 1.722330050 1.985158627 2.427853650
[21] 1.465286143 3.264971869 3.673337069 4.362467628 3.849652801
[26] 2.203451041 1.766208327 2.045552176 0.510890846 -0.837718447
[31] 1.127791121 0.850939383 -0.587615131 0.040573137 -0.274500005
......
> eacf(arma11.s)
AR/MA
0 1 2 3 4 5 6 7 8 9 10 11 12 13
0 x x x x o o o o o o o o o o
1 x o o o o o o o o o o o o o
2 x o o o o o o o o o o o o o
3 x x o o o o o o o o o o o o
4 x o x o o o o o o o o o o o
5 x o o o o o o o o o o o o o
6 x o o o x o o o o o o o o o
7 x o o o x o o o o o o o o o
左上角为0的模型,为最适合的模型;
EACF在适度大的样本容量,似乎有优良的样本性质;
EACF统计误差,左上0值附近的均可尝试对比。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com