ai训练模型原理 中英文最大AI模型世界纪录产生
边策 发自 凹非寺量子位 报道 | 公众号 QbitAI
超大AI模型训练成本太高hold不住?连市值万亿的公司都开始寻求合作了。
本周,英伟达与微软联合发布了5300亿参数的“威震天-图灵”(Megatron-Turing),成为迄今为止全球最大AI单体模型。
仅仅在半个月前,国内的浪潮发布了2500亿参数的中文AI巨量模型“源1.0”。

不到一个月的时间里,最大英文和中文AI单体模型的纪录分别被刷新。
而值得注意的是:
技术发展如此之快,“威震天-图灵”和“源1.0”还是没有达到指数规律的预期。
要知道,从2018年开始,NLP模型参数近乎以每年一个数量级的速度在增长。
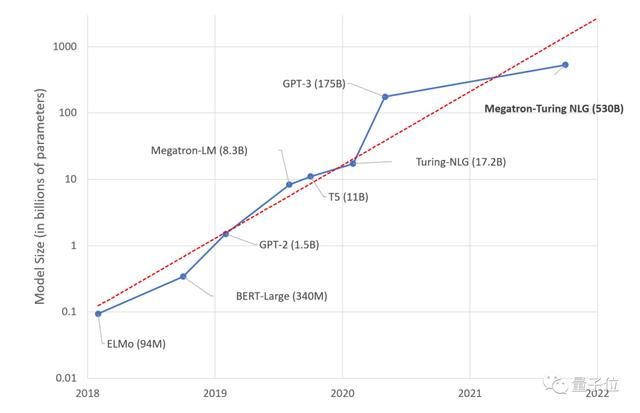
△ 近年来NLP模型参数呈指数级上涨(图片来自微软)
而GPT-3出现后,虽然有Switch Transformer等万亿参数混合模型出现,但单体模型增长速度已经明显放缓。

无论是国外的“威震天-图灵”,还是国内的“源1.0”,其规模和GPT-3没有数量级上的差异。即便“威震天-图灵”和“源1.0”都用上了各自最强大的硬件集群。
单体模型是发展遇到瓶颈了么?
超大模型的三个模式回答这个疑问,首先得梳理一下近年来出现的超大规模NLP模型。
如果从模型的开发者来看,超大规模NLP模型的研发随时间发展逐渐形成了三种模式。
一、以研究机构为主导
无论是开发ELMo的Allen研究所、还是开发GPT-2的OpenAI(当时还未引入微软投资)都不是以盈利为目标。
且这一阶段的超大NLP模型都是开源的,得到了开源社区的各种复现与改进。
ELMo有超过40个非官方实现,GPT-2也被国内开发者引入,用于中文处理。

二、科技企业巨头主导
由于模型越来越大,训练过程中硬件的优化变得尤为重要。
从2019年下半年开始,各家分别开发出大规模并行训练、模型扩展技术,以期开发出更大的NLP模型。英伟达Megatron-LM、谷歌T5、微软Turing-NLG相继出现。

今年国内科技公司也开始了类似研究,中文AI模型“源1.0”便是国内硬件公司的一次突破——
成就中文领域最大NLP模型,更一度刷新参数最多的大模型纪录。
“源1.0”不仅有高达5TB的全球最大中文高质量数据集,在总计算量和训练效率优化上都是空前的。
三、巨头与研究机构或巨头之间相互合作
拥有技术的OpenAI由于难以承受高昂成本,引入了微软10亿美元投资。依靠海量的硬件与数据集资源,1750亿参数的GPT-3于去年问世。
但是,今年万亿参数模型的GPT-4并没有如期出现,反而是微软与英伟达联手,推出了“威震天-图灵”。
我们再把目光放回到国内。
“威震天-图灵”发布之前,国内外涌现了了不少超大AI单体模型,国内就有阿里达摩院PLUG、“源1.0”等。
像英伟达、微软、谷歌、华为、浪潮等公司加入,一方面是为AI研究提供大量的算力支持,另一方面是因为他们在大规模并行计算上具有丰富的经验。
当AI模型参数与日俱增,达到千亿量级,训练模型的可行性面临两大挑战:
1、即使是最强大的GPU,也不再可能将模型参数拟合到单卡的显存中;
2、如果不特别注意优化算法、软件和硬件堆栈,那么超大计算会让训练时长变得不切实际。
而现有的三大并行策略在计算效率方面存在妥协,难以做到鱼与熊掌兼得。
英伟达与微软合体正是为此,同样面对该问题,浪潮在“源1.0”中也用了前沿的技术路径解决训练效率问题。
从“源1.0”的arXiv论文中,我们可以窥见这种提高计算效率的方法。
在对源的大规模分布式训练中,浪潮采用了张量并行、流水线并行和数据并行的三维并行策略。
“威震天-图灵”和“源1.0”一样,在张量并行策略中,模型的层在节点内的设备之间进行划分。

流水线并行将模型的层序列在多个节点之间进行分割,以解决存储空间不足的问题。

另外还有数据并行策略,将全局批次规模按照流水线分组进行分割。

三家公司运用各自的技术,将最先进的GPU与尖端的分布式学习软件堆栈进行融合,实现了前所未有的训练效率,最终分别打造出英文领域和中文领域的最大AI单体模型。
训练超大规模自然语言模型成本升高,技术上殊途同归,形成研究机构与科技巨头协同发展,三种探索模式并驾齐驱的局面。
中英AI模型互有胜负训练成本趋高,技术趋同,为何各家公司还是选择独自研究,不寻求合作?
我们从GPT-3身上或许可见一斑。
去年发布的GPT-3不仅未开源,甚至连API都是限量提供,由于获得微软的投资,今后GPT-3将由微软独享知识产权,其他企业或个人想使用完整功能只能望洋兴叹。
训练成本奇高、道德伦理问题以及为了保证行业领先地位,让微软不敢下放技术。其他科技公司也不可能将自己的命运交给微软,只能选择独自开发。
尤其对于中国用户来说,以上一批超大模型都不是用中文数据集训练,无法使用在中文语境中。
中文语言的训练也比英文更难。英文由单词组成,具有天然的分词属性。
而中文需要对句子首先进行分词处理,如“南京市长江大桥”, 南京市|长江|大桥、南京|市长|江大桥,错误的分词会让AI产生歧义。
相比于英文有空格作为分隔符,中文分词缺乏统一标准,同样一个词汇在不同语境、不同句子中的含义可能会相差甚远,加上各种网络新词汇参差不齐、中英文混合词汇等情况,要打造出一款出色的中文语言模型需要付出更多努力。
所以国内公司更积极研究中文模型也就不难理解了。
即便难度更高,国内公司还一度处于全球领先,比如数据集和训练效率方面。
据浪潮论文透露,“源1.0”硬件上使用了2128块GPU,浪潮共搜集了850TB数据,最终清洗得到5TB高质量中文数据集。

其文字数据体积多于“威震天-图灵”(835GB),而且中文信息熵大大高于英文,信息量其实更大。
在训练效率方面,“源1.0”训练用了16天,“图灵威-震天”用了一个多月,前者数据量是后者3倍有余,耗时却只有后者一半——
其专注中文,关注效率努力也可见一斑。
大模型你来我往间能看出,发展已走入百花齐放互不相让的阶段,这给我们带来新的思考:AI巨量模型既然不“闭门造车”,那如何走向合作?
多方合作可能才是未来表面上“威震天-图灵”(Megatron-Turing NLG)是第一次由两家科技巨头合作推出超大AI模型。
其背后,双方不仅组成了“超豪华”硬件阵容,在算法上也有融合。强强联合成为超大AI模型落地的一种新方式,
国外巨头开启先例,那么国内公司的现状又是如何呢?其实有机构已经迈出合作的第一步。
诸如浪潮的“源1.0”,和当初的“威震天”一样,也是由硬件厂商主导开发的超大规模自然语言模型。
浪潮透露,实际上9月28日的发布会上,他们邀请了国内的学者和数家科技公司共同探讨未来“源1.0”合作的可能性。
在产业界,浪潮早就提出了“元脑计划”的生态联盟,“源1.0”未来将向元脑生态社区内所有开发者开放API,所有加入生态的AI技术公司都可以利用“源1.0”进行二次开发,从而制造出更强大的功能。
国内超大规模自然语言模型合作的时代正在开启。
合作开发巨量模型能带来什么?李飞飞等知名学者已经给出答案:当数据规模和参数规模大到一定程度时,量变最终能产生质变,GPT-3就是先例。
如今大模型越来越多,但未来关键还在于如何纵横捭阖,打造属于一套开放合作体系,让所有技术公司群策群力。
而AI巨量模型在这样的生态体系下会带来怎样的变化,在“源1.0”等一大批模型开放后,应该很快就能看见。
参考链接:[1]https://arxiv.org/abs/2110.04725[2]https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/[3]https://mp.weixin.qq.com/s/0SE3rv3MdDzbqwAVFtSe8Q
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






