js 字母的unicode编码(Javascript中的string类型使用UTF-16编码)
在JavaScript中,所有的string类型(或者被称为DOMString)都是使用UTF-16编码的。
MDN
DOMString 是一个UTF-16字符串。由于JavaScript已经使用了这样的字符串,所以DOMString 直接映射到 一个String。
将 null传递给接受DOMString的方法或参数时通常会把其stringifies为“null”。
引出的Unicode中UTF-8与UTF-16编码的详细了解
Unicode编码Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
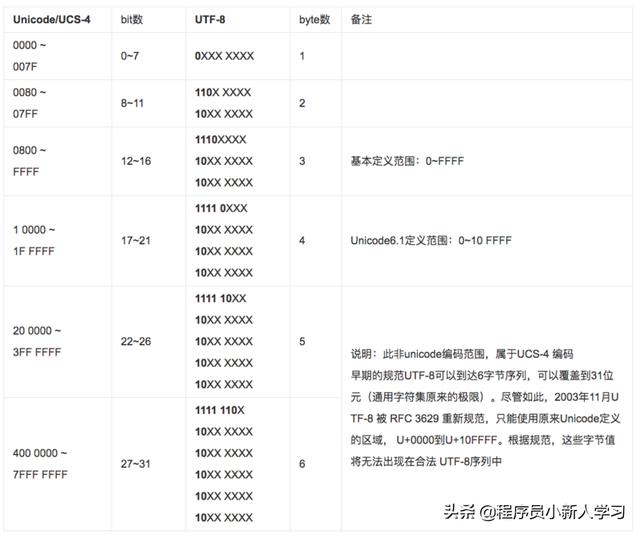
通常Unicode编码是通过2 Byte来表示一个字符的,如U A12B,2 Byte的二进制表示方法结果就是1010(A)0001(1) 0010(2)1011(B)。
需要注意的是:UTF是Unicode TransferFormat的缩写,UTF-8和UTF-16都是把Unicode码转换成程序数据的一种编码方式。
UTF-8UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码Unicode字符(尽管如此,2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U 0000到U 10FFFF,也就是说最多4个字节)。用在网页上可以统一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
UTF-8的来历
UTF-8的规范里充斥着这样神秘的句子:“第一个位元组由110开始,接着的位元组由10开始”,“第一个位元组由1110开始,接着的位元组由10开始”。
那么这到底是什么意思呢?为什么要这么做呢?
我们先从二进制说起。我们都知道,一个字节是由8个二进制位构成的,最小就是0000 0000,最大就是1111 1111。那么一个字节所能表示的最多字符数就是2的8次方,也就是256。对于26个英文字母来说,大小写全算上就是52个,再加上10个阿拉伯数字,62个字符,用可以表达256个不同字符的一个字节来存储是足够了。
但是,我们中国的常用汉字就有3000多个,用一个只能表达256个字符的字节显然是不够存储的。至少也需要有2个字节,1个字节是8个二进制位,2个字节就是16个二进制位,最多可以表达2的16次方,也就是256*256=65536。65536个字符足够容纳所有中国的汉字,外带日语、韩语、阿拉伯语、稀其古怪语等等各种各样的字符。所以这样就产生了Unicode,因为它用2字节表示字符,所以更严格来讲应该叫UCS-2,后来因为怪字符太多,2字节都不够用了,所以又搞出来了一个4字节表示的方法,称作UCS-4。不过现在对绝大多数人来讲UCS-2已经是足够了。
Unicode本来是一个好东西,用2字节表示65536种字符,全人类皆大欢喜的事情。但是偏偏有一帮子西洋人,非要认为这个东西是一种浪费,说我们英文就最多只需要26个字母就够了,1个字节就够了,为什么要浪费2字节呢?比如说字母A就是0100 0001,这一个字节就够了的东西,你弄2字节,非要在前面加8个0,0000 0000 0100 0001,这不是浪费吗?我们就偏要用1字节表示英文。
好吧,我们全人类只好做妥协,规定每个字节,只要看见0打头的,就知道这是英文字母,这肯定不是汉字,只有看见1开头的,才认为这是汉字。
但是我们汉字用1个字节表示不下,那好办,用2个1开头的字符表示1个汉字。这样本来16个二进制位,减去2个开头的1,只剩下14个二进制位了,2的14次方就是16384个字符,对于中文来讲,也是足够用了。但是无奈他们还是想表达65536种字符,那怎么办呢?就需要3个字节才能容纳得下了,于是UTF-8粉墨登场。
首先,首位为0的字符被占了,只要遇到0开头的字符,就知道这是一个1字节的字符,不必再往后数了,直接拿来用就可以,最多表示128种字符,从0000 0000到0111 1111,也就是从0到127。
接下来的事情就比较蹊跷了。我们怎么用1开头的字符既表示2字节,又表示3字节呢?假设我们只判断首位的1,这显然是不行的,没有办法区分,所以我们可以用10或者11开头的字符来表示2字节,但是3字节又该以什么开头?或者可以用10开头表示2字节,用11开头表示3字节?那么4字节的字符将来又该怎么办?也许我们可以用110开头表示3字节,用111开头表示4字节?那么5字节6字节呢?似乎我们看到了一个规律:前面的1越多,代表字节数越多。
这时候,看一下我们的第一种方案:用10开头表示2字节,那么我们的一个字符将是
10xx xxxx 10xx xxxx
用110表示3字节,那么一个3字节的字符将是:
110x xxxx 110x xxxx 110x xxxx
这样无疑是能区分得开的。但是4字节怎么办?
1110 xxxx 1110 xxxx 1110 xxxx 1110 xxxx
吗?这样也能区分开,但似乎有点浪费。因为每个字节的前半扇都被无用的位占满了,真正有意义的只有后面一半。
或者我们干脆这样做得了,我们来设计方案二:为了节省起见,所有后面的字符,我们统统都以10开头,只要遇见10我们就知道它只是整个字符流的一部分,它肯定不是开头,但是10这个开头已经被我们刚刚方案一的2字节字符占用了,怎么办?好办,把2字节字符的开头从10改成110,这样它就肯定不会和10冲突了。于是2字节字符变成
110x xxxx 10xx xxxx
再往后顺推,3字节字符变成
1110 xxxx 10xx xxxx 10xx xxxx
4字节字符变成
1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx
好像比刚才的方案一有所节省呢!并且还带来了额外的好处:如果我没有见到前面的110或者1110开头的字节,而直接见到了10开头的字节,毫无疑问地可以肯定我遇到的不是一个完整字符的开头,我可以直接忽略这个错误的字节,而直接找下一个正确字符的开头。
这个改良之后的方案二就是UTF-8!
UTF-8表示的字符数
现在,我们来算一下在UTF-8方案里,每一种字节可以表示多少种字符。
1字节的字符,以0开头的,0xxx xxxx,后面7个有效位,2的7次方,最多可以表示128种字符。
2字节的字符,110x xxxx 10xx xxxx,数一数,11个x,所以是2的11次方,2的10次方是1024,11次方就是2048,很不幸,只能表示2048种字符,而我们的常用汉字就有3000多个,看来在这一区是放不下了,只好挪到3字节。
3字节的字符,1110 xxxx 10xx xxxx 10xx xxxx,数一数,16个x,2的16次方,最多可以表示65536个字符,所以我们的汉字就放在这一区,所以在UTF-8方案里我们的汉字都是以3个字节表示的。
所以这也就是这一张表的来历:
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为 "storage format")的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元, 长度为2 Byte)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
起初,UTF-16任何字符对应的数字都用两个字节来保。但是,65536显然是不算太多的数字,用它来表示常用的字符是没一点问题,足够了。但如果加上很多特殊的就也不够了。于是,从1996年开始又来了第二个版本,用四个字节表示所有字符。这样就出现了UTF-8,UTF16,UTF-32。UTF-32就是把所有的字符都用32bit也就是4个字节来表示。然后UTF-8,UTF-16就视情况而定了,UTF-16可以选择两字节或四字节。
UTF-16 并不是一个完美的选择,它存在几个方面的问题:
- UTF-16 能表示的字符数有 6 万多,看起来很多,但是实际上目前 Unicode 5.0 收录的字符已经达到 99024 个字符,早已超过 UTF-16 的存储范围;这直接导致 UTF-16 地位颇为尴尬——如果谁还在想着只要使用 UTF-16 就可以高枕无忧的话,恐怕要失望了
- UTF-16 存在大小端字节序问题,这个问题在进行信息交换时特别突出——如果字节序未协商好,将导致乱码;如果协商好,但是双方一个采用大端一个采用小端,则必然有一方要进行大小端转换,性能损失不可避免(大小端问题其实不像看起来那么简单,有时会涉及硬件、操作系统、上层软件多个层次,可能会进行多次转换)
大小端转换?
1、因为utf8是变长编码,而且是单字节为编码单元,不存在谁在高位、谁在低位的问题,所以不存在顺序问题!顺便说一下解码,由于utf8的首字节记 录了总字节数(比如3个),所以读取首字节后,再读取后续字节(2个),然后进行解码,得到完整的字节数,从而保证解码也是正确的。
2、utf16是变长编码,使用1个16-bit编码单元或者2个16-bit编码单元,utf32是定长编码,这里拿utf16举例,在基本平面总是以2个字节为编码单元, 鉴于“第一条”编码单元与编码单元之间的顺序是正确的,问题只能在编码单元内部中字节与字节的顺序,由于硬件cpu的不同,编码单元内部字节 与字节的顺序不确定。假如cpu是大端序那么高位在前,如果cpu是小端序那么低位在前,为了区分,所以有了BOM(byte order mark),然后计 算机才能知道谁是高位,谁是低位,知道了高低位,从而能正确组装,然后才能解码正确。
例如,一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?如果BOM 是大端序,那么代码点就应该是594E,那么就是“奎”,如果BOM是小端序,那么代码点就应该是4E59,就是“乙”了。
综上所述,因为utf8是单字节为编码单元,在网络传输时,不存在字节序列问题。在解码时,由于首字节记录了总字节数,所以能正确解码。
因为utf16是定长编码,总是以2个字节为编码单元,在网络传输时,不存在字节序列问题。在解码时,由于cpu硬件差异,存在字节序问题,所以通 过BOM来标记字节顺序;
另外,容错性低有时候也是一大问题——局部的字节错误,特别是丢失或增加可能导致所有后续字符全部错乱,错乱后要想恢复,可能很简单,也可能会 非常困难。(这一点在日常生活里大家感觉似乎无关紧要,但是在很多特殊环境下却是巨大的缺陷)
目前支撑我们继续使用 UTF-16 的理由主要是考虑到它是双字节的,在计算字符串长度、执行索引操作时速度很快。当然这些优点 UTF-32 都具有,但很多人毕竟还是觉得 UTF-32 太占空间了。
UTF-8 也不完美,也存在一些问题:
- 文化上的不平衡——对于欧美地区一些以英语为母语的国家 UTF-8 简直是太棒了,因为它和 ASCII 一样,一个字符只占一个字节,没有任何额外的存储负担;但是对于中日韩等国家来说,UTF-8 实在是太冗余,一个字符竟然要占用 3 个字节,存储和传输的效率不但没有提升,反而下降了。所以欧美人民常常毫不犹豫的采用 UTF-8,而我们却老是要犹豫一会儿
- 变长字节表示带来的效率问题——大家对 UTF-8 疑虑重重的一个问题就是在于其因为是变长字节表示,因此无论是计算字符数,还是执行索引操作效率都不高。为了解决这个问题,常常会考虑把 UTF-8 先转换为 UTF-16 或者 UTF-32 后再操作,操作完毕后再转换回去。而这显然是一种性能负担。
UTF-8 的优点:
- 字符空间足够大,未来 Unicode 新标准收录更多字符,UTF-8 也能妥妥的兼容,因此不会再出现 UTF-16 那样的尴尬
- 不存在大小端字节序问题,信息交换时非常便捷
- 容错性高,局部的字节错误(丢失、增加、改变)不会导致连锁性的错误,因为 UTF-8 的字符边界很容易检测出来,这是一个巨大的优点(正是为了实现这一点,咱们中日韩人民不得不忍受 3 字节 1 个字符的苦日子)
大神如何选择的呢?
因为无论是 UTF-8 和 UTF-16/32 都各有优缺点,因此选择的时候应当立足于实际的应用场景。例如在大神的习惯中,存储在磁盘上或进行网络交换时都会采用 UTF-8,而在程序内部进行处理时则转换为 UTF-16/32。对于大多数简单的程序来说,这样做既可以保证信息交换时容易实现相互兼容,同时在内部处理时会比较简单,性能也还算不错。(基本上只要你的程序不是 I/O 密集型的都可以这么干,当然这只是大神粗浅的认识范围内的经验,很可能会被无情的反驳)
作者:学霸猫
原文:https://my.oschina.net/wangch5453/blog/3044462
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






