Web渗透测试攻防之浅述信息收集(Web渗透测试攻防之浅述信息收集)
众所周知渗透测试的本质是信息收集,在渗透测试中信息收集的质量直接关系到渗透测试成果的与否。在对系统进行渗透测试前的信息收集是通过各种方式获取所需要的信息,收集的信息越多对目标进行渗透的优势越有利。通过利用获取到的信息对系统进行渗透。只有掌握了足够多的目标信息才能更好的对目标系统进行渗透。正所谓知彼知己百战不殆。
1.信息收集的分类从信息收集方式分类可将信息收集分为两大类:
①主动信息收集②被动信息收集
1.1 主动信息收集通过主动扫描目标主机或网站,对目标进行探测性扫描获取相关信息。这种方式获取到的信息更为准确能获取到的信息更多,但缺点也比较明显。通过主动信息收集容易留下明显的攻击访问痕迹,易发现和被溯源。
1.2 被动信息收集通过搜索引擎等公开渠道进行相关信息的检索收集信息,这种方式不直接与目标建立交互访问连接,避免了留下访问痕迹。被动信息收集的优缺点正好与主动信息收集的优缺点相反,被动信息收集不会留下访问痕迹避免被溯源发现,但收集到的信息依赖于搜索引擎,准确性和质量无法保证。
2.信息收集目标和方法【一一帮助安全学习,所有资源关注我,私信回复“资料”获取一一】①网络安全学习路线②20份渗透测试电子书③安全攻防357页笔记④50份安全攻防面试指南⑤安全红队渗透工具包⑥网络安全必备书籍⑦100个漏洞实战案例⑧安全大厂内部教程
2.1 域名信息2.1.1 Whois
通过whois查询可以获得域名注册者邮箱地址等信息。一般情况下对于中小型网站,域名注册者就是网站管理员。利用搜索引擎对whois查询到的信息进行搜索,获取更多域名注册者的个人信息。通过whois查询获取IP、法人的名字、电话、邮箱、地址等信息对社工攻击具有很大的作用。
相关:
站长之家查询接口:https://whois.chinaz.com/ 阿里云查询接口:https://whois.aliyun.com/ 全球whois查询:https://www.whois.com/cn/2.1.2 搜索引擎查找
搜索引擎通常会记录域名信息,可以通过搜索引擎高级搜索语法进行查询 。
例如使用google高级搜索语法查找baidu的子域名语法为site:baidu.com
利用空间测绘搜索引擎语法进行搜索,目前比较常用的空间测绘搜索引擎入下:
fofa:https://fofa.info/toLogin 鹰图:https://hunter.qianxin.com/ quake:https://quake.360.cn/quake/#/index 钟馗之眼:https://www.ZoomEye.org/ Shodan:https://www.shodan.io/2.1.3 第三方查询
国外有一些第三方应用提供了子域名查询功能,因工具多为国外应用,多数使用对国内查找效果不够好,列举如下:
- DNSDumpster
- Virustotal
- CrtSearch
- threatminer
- Censys
2.1.4 网站信息利用
在网站中可以根据网站本身的功能特点收集网站本身、各项安全策略、设置等可能暴露泄漏出的一些信息。
网站本身的交互通常不囿于单个域名,会和其他子域交互。对于这种情况,可以通过爬取网站,收集站点中的其他子域信息。这些信息通常出现在JavaScript文件、资源文件链接等位置。
网站的安全策略如跨域策略、CSP规则等通常也包含相关域名的信息。有时候多个域名为了方便会使用同一个SSL/TLS证书,因此有时可通过证书来获取相关域名信息。
2.1.5 CDN
可通过验证网站是否使用了CDN进行域名查找,一般使用了CDN的域名的父域或者子域名不一定使用了CDN,可以通过这种方式去查找对应的IP。另外CDN可能是在网站上线一段时间后才使用的,可以通过查找域名解析记录的方式去查找真实IP。
2.1.6 域名枚举
通过工具进行子域名枚举也是一种有效的域名搜集手段,域名枚举采用主动信息收集的方式,这种方式向目标站点发送了大量的请求数据包容易被检测发现。比较常用的域名枚举工具有:
2.2 端口信息
* [Layer子域名挖掘机]http://www.xdowns.com/soft/525081.html * [burp插件domain_hunter_pro]https://Github.com/bit4woo/domain_hunter_pro/releases/download/v1.4/domain_hunter_pro-v1.4-jar-with-dependencies.jar * [dirsearch]https://github.com/maurosoria/dirsearch * [dirb]http://dirb.sourceforge.net/ * [御剑后台扫描]https://www.xiazaiba.com/html/84460.html * [teemo]https://github.com/bit4woo/teemo * [subDomainsBrute]https://github.com/lijiejie/subDomainsBrute2.2.1 常见端口脆弱点
端口
服务
可能存在的风险威胁
21
ftp
是否支持匿名/弱口令
80
web
常见web漏洞/web管理后台弱口令
443
Openssl
心脏滴血以及一些web漏洞测试
873
rsync
是否支持匿名/弱口令
2601/2604
zebra路由
默认口令
3690
svn
svn泄露/未授权访问
6379
redis
一般无认证,可直接访问
7001
weblogic
默认弱口令
8061/8161
ActiveMQ
弱口令/远程命令执行
8080
tomcat
弱口令/默认口令
8089
jboss
未授权访问/弱口令
8649
ganglia
信息泄漏
8888
宝塔
未授权等多个漏洞
11211
memcache
未授权访问
27017
mongodb
未授权访问
2.2.2 常见端口扫描方式
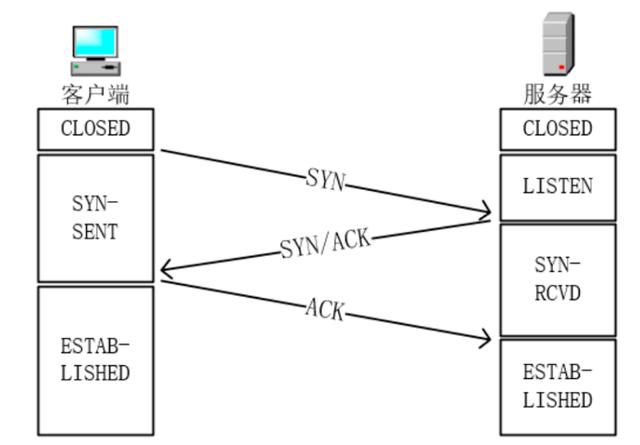
在传输层TCP/IP协议中包含TCP、UDP两种协议,其中TCP面向连接的数据传输协议中通过TCP请求建立“三次握手”连接的原理就是端口扫描技术的基本原理,端口扫描就是根据TCP请求的“三次握手”原理在此基础上进行的。端口扫描并非TCP建立连接的过程,而是通过TCP连接的中不同阶段的状态进行实现的。
TCP连接“三次握手”的过程如上图所示,在TCP建立连接的过程中从图中也可以看出服务端有四种不同的状态:
(1)CLOSED状态:除了收到RST数据包进行丢弃,收到其他数据包一律返回RST。
(2)LISTEN状态:如果收到客户端建立连的接请求SYN数据包则进行第二次握手返回SYN和ACK,然后转入SYN-RCVD状态。如果收到ACK第三次握手包返回RST,收到其他包一律丢弃。
(3)SYN-RCVD状态:如果收到第三次握手ACK数据则转入ESTAB-LISHED状态,此时完成了TCP连接的建立。如果收到的数据包为RST就返回到LISTEN状态。
基于TCP建立连接过程中服务端端口的几种状态,端口扫描技术可分为全连接、半连接、FIN、ACK和NULL四种扫描方式。
全扫描
全连接扫描又叫做TCP connect扫描,通过调用操作系统connect函数与目标建立真实的TCP连接来判断端口是否开放,连接建立成功则说明端口是开放的状态反之则关闭,这种扫描方式对大量的端口测试需要大量的函数调用速度较慢且建立连接的形式已被检测。
半扫描
TCP SYN扫描是半连接的扫描,这种扫描方式通过与目标端口建立TCP连接的过程中仅进行前两次握手,在第三次握手时客户端不发送确认报文,使TCP连接无法建立。这种扫描方式不会再目标主机留下扫描痕迹,但利用条件要求较高需要较高的系统权限。
FIN扫描
TCP FIN扫描是一种更具隐蔽性的扫描方式,FIN数据能够通过防火墙的过滤不为其他过滤器所拦截更具有隐蔽性。在FIN扫描方式中利用了扫描中关闭的端口会对FIN数据进行RST回复,开放的端口会忽略FIN数据包回复。虽然这种扫描方式更加隐蔽但是对于不同的操作系统有些系统并不适用,这种扫描方式容易得到误报。
ACK扫描
ACK扫描技术并不能探测端口开放情况,ACK扫描通过只发送ACK标志位报文,如果目标主机返回RST标记报文则说明目标主机未受到防火墙保护,如果不能够收到响应报文说明发送报文未到达,系统端口可能受防火墙保护。这种方式探测端口开放不准确,适合二层主机扫描探测。
NULL扫描
NULL扫描,将报文中所有标记都置为0进行发送,如果目标返回RST则端口关闭,没有收到响应说明端口开放或被防火墙保护。这种扫描方式扫描的结果准确度也不高。
2.2.3 批量端口搜索
要搜集开放固定端口的系统可以使用资产搜索引擎使用port语法获取互联网上大量的系统,常用的搜索引擎如下。
2.3 站点信息
- Shodan
- ZoomEye
- fofa
- 鹰图
判断网站操作系统
- Linux大小写敏感Windows大小写不敏感
扫描敏感文件
- robots.txtcrossdomain.xmlsitemap.xmlxx.tar.gzxx.bak
确定网站采用的语言
- 如PHP / Java / Python等找后缀,比如php/asp/jsp
判断前/后端框架
- 如jQuery / BootStrap / Vue / React / Angular等查看源代码根据Cookie判断根据CSS / 图片等资源的hash值判断根据URL路由判断,如wp-admin根据网页中的关键字判断根据响应头中的X-Powered-By
确定中间Web容器服务器
- 如 Apache / Nginx / IIS 等查看header中的信息根据报错信息判断根据默认页面判断如Tomcat / Jboss / Weblogic等
CDN信息
- 常见的有Cloudflare、yunjiasu
探测WAF
- 探测是否使用WAF、判断类型
敏感目录
- 扫描敏感目录查看是否存在信息泄漏
- 使用爬虫爬取网站信息
- 通过获取到的信息进一步利用
2.4 搜索引擎利用
- 通过拿到的目录名称,文件名称及文件扩展名了解网站开发人员的命名思路,确定其命名规则,推测出更多的目录及文件名
合理的使用搜索引擎(Google/Bing/Baidu等)可以获取目标站点的较多信息。
2.4.1 高级搜索语法
- site
把搜索范围限定在特定站点中,如site:某某.com。用来搜索某个域名下的所有被搜索引擎收录的文件,适用于所有的搜索引擎。
- domain
查找跟某一网站相关的信息或反向链接,目前此指令只适用于百度,例如:在百度上提交搜索“domain:www.mahaixiang.cn”,所搜索的结果就的关于www.mahaixiang.cn网站的反向链接。
- link
查询网站外链的搜索指令(例如:Link:www.mahaixiang.cn),此搜索指令只适用于Google,在百度上是不起作用。
- inurl
inurl:指令用于搜索查询词出现在url中的页面,百度和Google都支持inurl指令,inurl指令支持中文和英文。
比如搜索:inurl:搜索引擎优化,返回的结果都是网址url中包含“搜索引擎优化”的页面。
- and
利用and表示前后两个关键词是“与”的逻辑关系,例如输入关键词:“渗透测试 and 网络工程”,就会找出同时包含渗透测试和网络工程有关的网站。
- or
利用or(|)表示前后两个词是“或”的逻辑关系,例如输入关键词:“渗透测试 and 网络工程”,会找出将包含渗透测试或者网络工程的网页。or与|等同,使用“A|B”来搜索“或者包含词语A,或者包含词语B”的网页。
- 双引号(””)
把搜索词放在双引号中(英文半角双引号),代表完全匹配搜索一个词,也就是说搜索结果返回的页面包含双引号中出现的所有的词,连顺序也必须完全匹配,目前,百度和Google都支持这个指令,例如:搜索“SEO博客”。
- 减号(-)
减号代表搜索不包含减号后面的词的页面,使用这个指令时减号前面必须是空格,减号后面没有空格,紧跟着需要排除的词。
- 星号(*)
星号是常用的通配符,也可以用在搜索中代表任何文字使用。
- inurl
inurl:xxx的作用是命令搜索引擎查找url中包含xxx的网页,例如:inurl:www.baidu.com。“inurl:xxx 关键词”或“关键词 inurl:xxx”两者意义一样,都是要求搜索引擎查找的结果满足url中包括xxx和网页中含有“关键词”的两个要求。通常情况,任何网站的url都不是随意设置的,都经过一番过虑,有一定用意的,很多地方,url链接和网页的内容有着密切的相关,所以,可以利用这种相关性,来缩小范围,快速准确地找到所需信息。
- intitle
intitle: 指令返回的是页面title中包含关键词的页面,使用intitle指令可以根据网站的标题更准确的找出互联网中的相关站点。
- info
提交info:url,将会显示需要查询网站的一些信息。
- filetype
filetype命令对搜索对象的文件类型做限制,冒号后是文档格式,如PDF、DOC、XLS等。
当我们在查询里边包含filetype:扩展名的时候,Google会限制查询结果仅返回特定文件类型的网页。
用于搜索特定文件格式,目前,Google和百度都支持filetype指令,比如搜索:“密码 filetype:pdf”,搜索返回的就是包含“密码”这个关键词的所有pdf文件,其它可用的特定文件类型格式查询还有doc、txt、ppt、xls、rtf、swf、ps等。
2.4.2 网页快照
搜索引擎的快照中也常包含一些关键信息,如程序报错信息可以会泄漏网站具体路径,或者一些快照中会保存一些测试用的测试信息,比如说某个网站在开发了后台功能模块的时候,还没给所有页面增加权限鉴别,此时被搜索引擎抓取了快照,即使后来网站增加了权限鉴别,但搜索引擎的快照中仍会保留这些信息。
2.5 社会工程学2.5.1 企业信息收集
一些网站如天眼查等,可以提供企业关系挖掘、工商信息、商标专利、企业年报等信息查询,可以提供企业的较为细致的信息。
相关网站:
* [天眼查]https://www.tianyancha.com/ * [爱企查]https://aiqicha.baidu.com/?from=pz * [企查查]https://aiqicha.baidu.com/?from=fc&source=aff--2097005918&bd_vid=55570415878355420322.5.2 人员信息收集
针对人员的信息收集考虑对目标重要人员、组织架构、社会关系的收集和分析。其中重要人员主要指高管、系统管理员、运维、财务、人事、业务人员的个人电脑。
人员信息收集较容易的入口点是网站,网站中可能包含网站的开发、管理维护等人员的信息。从网站联系功能中和代码的注释信息中都可能得到的所有开发及维护人员的姓名和邮件地址及其他联系方式。
还可以使用社工库通过相关手机号、qq、邮箱等个人信息对人员进行信息查询。
在获取这些信息后,可以在Github/Linkedin等网站中进一步查找这些人在互联网上发布的与目标站点有关的一切信息,分析并发现有用的信息。
此外,可以对获取到的邮箱进行密码爆破的操作,获取对应的密码。
,

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






