cortex-m3定义的内核图是怎样的(Cortex-M3内核芯片进阶之启动过程详解)
“ARM 程序”是指在 ARM 系统中正在执行的程序,而非保存在 ROM 中的 bin 映像(image)文件。这一点清注意区别。
一个 ARM 程序包含 3 部分: RO, RW 和 ZI。
- RO 就是只读数据,是程序中指令和常量;
- RW 是可读写的数据,程序中已初始化变量;
- ZI 是程序中未初始化的变量和初始化为 0 的变量。
由以上 3 点说明可以理解为:
- RO 就是 readonly;
- RW 就是 read/write;
- ZI 就是 zero。
1.1 ARM 芯片的启动过程概述

图 3.1 ARM 芯片的启动过程详解
注意,以上的过程并非绝对的,不同的 ARM 架构或是不同的代码以上的执行过程是不同的。
复位处理程序是在汇编器中编写的短模块,系统一启动就立即执行。复位处理程序最少要为应用程序的运行模式初始化堆栈指针。对于具有本地内存系统(如缓存、 TCM、 MMU 和MPU)的处理器,某些配置必须在初始化过程的这一阶段完成。复位处理程序在执行之后,通常跳转到__main 以开始 C 库初始化序列。
__main 负责设置内存,而__rt_entry 负责设置运行时环境。 __main 执行代码和数据复制、解压缩以及 ZI 数据的零初始化。然后,它跳转到__rt_entry,设置堆栈和堆、初始化库函数和静态数据,并调用任何顶级 C 构造函数。然后, __rt_entry 跳转到应用程序的入口 main()。主应用程序结束执行后, __rt_entry 将库关闭,然后把控制权交还给调试器。函数标签 main()具有特殊含义。 main()函数的存在强制链接器链接到__main 和__rt_entry 中的初始化代码。如果没有标记为 main()的函数,则没有链接到初始化序列,因而部分标准 C 库功能得不到支持。
1.2 结合代码来看 ARM 芯片的启动过程
1.2.1 调试环境的搭建及测试代码
使用 Keil for ARM( uVision4)的软件模拟,工程的硬件设定为 LPC1700 系列,不使用microlib。这里不使用 microlib,则系统自动加载标准 C Library,这样我们才能看到标准的 ARM芯片的标准启动过程。随后我们会对 microlib 进行探讨。测试代码如下:
程序清单 3.1 启动过程测试代码#include "LPC17xx.h" /* LPC17xx 外设寄存器 */int main (void){
SystemInit();//系统初始化
while (1) {}
}
我们的测试代码使用的是一段最简单的代码,代码本身只包含 CMSIS 标准的必备文件,即stdint.h、 core_cm3.h、 core_cm3.c、 system_LPC17xx.h、 system_LPC17xx.c、 LPC17xx.h、startup_LPC17xx.s 和 main.c。
1.2.2 跟踪启动代码开始调试之前,须将工程设置的 DEBUG 栏中取消掉 Run to main()的勾选,否则代码会直接运行到 main()函数,我们也就无法看到芯片的启动过程了。然后启动调试,最先进入 Reset_Handler,如下图所示。

图 1.2 Reset_Handler
继续单步运行,程序跳入__main(C Library 的代码,并非用户代码),如下图所示。
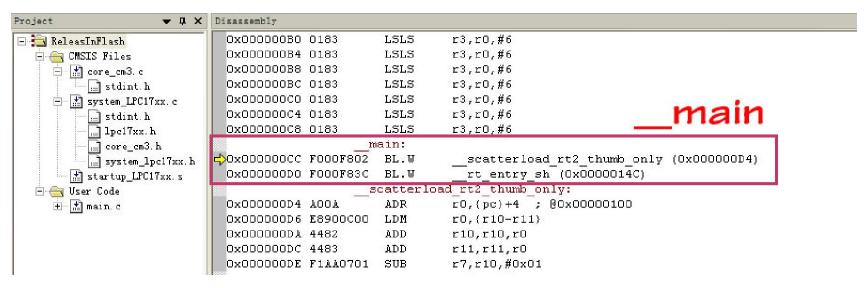
图 1.3 __main
继续单步运行,经过一系列的代码(主要是 scatter load 过程)后,程序进入__rt_entry(同样是由 C Library 管理,并非用户代码)。

图 1.4 __rt_entry
继续单步运行,再次经过一系列的代码之后(主要是堆栈和堆的初始化以及 C Library 的初始化),程序进入 main()。如下图所示。

图 1.5 进入 main 函数
以上是整个测试代码启动过程的跟踪调试的大致过程,这个过程对 ARM 系列的芯片来说都是相同的,不同的是里面具体的细节。
1.2.3 详细的启动过程使用的依然是上面的测试代码,详细启动过程如下图所示。
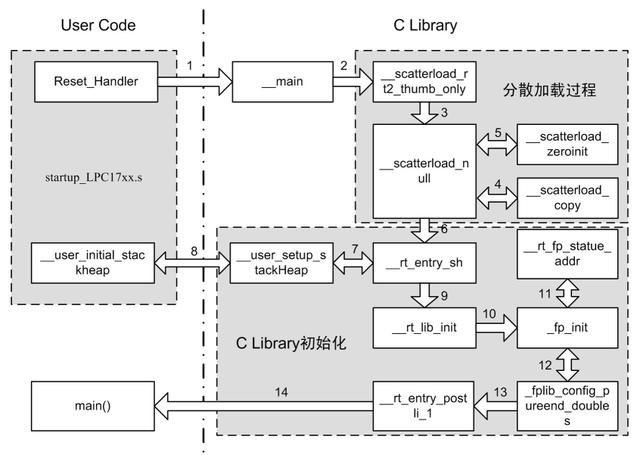
图 1.6 芯片启动的详细过程
上图显示的就是测试代码在 LPC17xx 上启动运行的全过程(详细过程),由此图可见LPC17xx 的启动过程与图 1.1 所示的启动过程是基本一致的,但是还有差别,可以说是图 1.1所示启动过程的简化版。注意:并非所有代码的启动过程全部相同,此启动过程与所使用的链接器、用户代码以及其所集成的 C Library 密切相关。此图为由“armlink”的链接器为程序清单 1.2 所示的测试代码产生的启动过程,其他情况可能会有一些差异(比如有的代码的启动过程就会运行一段 RW段的解压代码等,而本例程中则没有)。
1.2.4 __main
若程序使用的是 C 或 C 语言编写的代码,那么 C/C 程序的入口是在 C Library 中的__main。库代码在此处执行以下操作。
- 1 将非根(RO 和 RW)执行区从其加载地址复制到执行地址(这里的根区指的就是__main 和__rt_entry)。另外,如果压缩了任何数据节,则会将它们从加载地址解压缩到执行地址(此数据压缩及解压缩过程并不是对所有代码都会执行);
- 将 ZI 区清零;
- 跳转到__rt_entry。
1.2.5 __rt_entry
__rt_entry 符号是使用 ARM C 库的程序的起点。将所有分散加载区重定位到其执行地址后,会将控制权传递给__rt_entry。其有如下缺省实现:
- 设置堆和堆栈。
- 调用__rt_lib_init 以初始化 C Library。
- 调用 main()。
- 调用__rt_lib_shutdown 以关闭 C Library。
- 退出。
注意:最后两步是在程序退出 main()函数时才会执行,而嵌入式程序一般都是死循环,所以基本不会执行这两个过程。还有,以上过程是对标准 C Library 而言,不包括使用 microlib的情况。
1.2.6 __rt_lib_init
这是库初始化函数,它与__rt_lib_shutdown()配合使用。
这是库初始化函数。它是紧靠__rt_stackheap_init()后面调用的,并传递一个要用作堆的初始内存块。此函数是标准 ARM 库初始化函数,不能重新实现此函数。
1.3 关于 microlib
microlib 是缺省 C 库的备选库。它旨在与需要装入到极少量内存中的深层嵌入式应用程序配合使用。这些应用程序不在操作系统中运行。 microlib 进行了高度优化以使代码变得很小。它的功能比缺省 C 库少,并且根本不具备某些 ISO C 特性。某些库函数的运行速度也比较慢,例如, memcpy()。microlib 与缺省 C 库之间的主要差异是:
- microlib 不符合 ISO C 库标准。不支持某些 ISO 特性,并且其他特性具有的功能也较少;
- microlib 不符合 IEEE 754 二进制浮点算法标准;
- microlib 进行了高度优化以使代码变得很小;
- 无法对区域设置进行配置。缺省 C 区域设置是唯一可用的区域设置;
- 不能将 main()声明为使用参数,并且不能返回内容;
- 不支持 stdio,但未缓冲的 stdin、 stdout 和 stderr 除外;
- microlib 对 C99 函数提供有限的支持;
- microlib 不支持操作系统函数;
- microlib 不支持与位置无关的代码;
- microlib 不提供互斥锁来防止非线程安全的代码;
- microlib 不支持宽字符或多字节字符串;
- 与 stdlib 不同, microlib 不支持可选择的单或双区内存模型。 microlib 只提供双区内存模型,即单独的堆栈和堆区。
1.4 x.map
想要更好的了解启动代码的运行机制,我们就有必要了解一下由 Keil 的链接器“armlink”生成的描述文件即 x.map 文件。
1.4.1 关于链接器
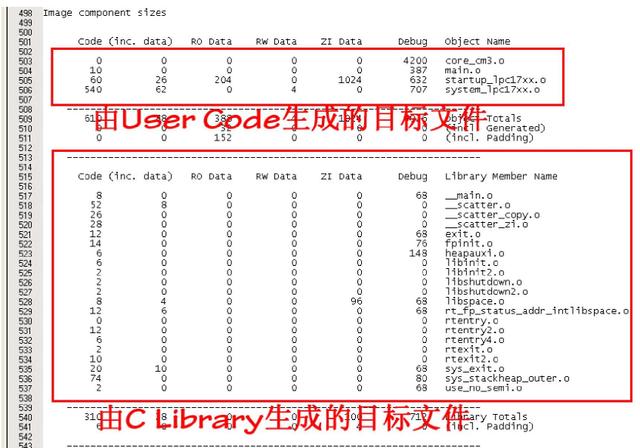
图 1.7 目标文件的组成
上图即是 armlink 的链接器为程序清单 1.1 所示的测试代码生成的.map 文件中的一部分,其描述了镜像文件的组成信息,其中可以明显的看到其由两部分构成:
- 由 User Code 生成的目标文件;
- 由 C Library 生成的目标文件。
可见我们在上文中所描述的启动过程中看到的__main、 __rt_entry、 __scatterload 以及__rt_lib_init 等,就是 C Library 中的代码。同理,我们每次烧录的可执行的 ARM 的 bin 文件中不仅有开发者编写的代码,还有C Library 的代码。
1.4.2 RW 段在 RAM 的存放

图 1.8 由 armlink 生成的 RW 段在 RAM 中存放的描述
1.5 关于 ARM 程序的 Memory 管理
1.5.1 ARM 镜像文件的组成(image)
所谓 ARM 映像文件就是指烧录到 ROM 中的 bin 文件,也成为 image 文件。以下用 Image文件来称呼它。 Image 文件包含了 RO 和 RW 数据(注意:不包含 ZI 数据)。之所以 Image 文件不包含 ZI 数据,是因为 ZI 数据都是 0,没必要包含,只要程序运行之前将 ZI 数据所在的区域(执行区域)一律清零即可。包含进去反而浪费存储空间。
1.5.2 关于 image 文件(镜像文件)
从以上两点可以知道,烧录到 ROM 中的 image 文件与实际运行时的 ARM 程序之间并不是完全一样的。因此就有必要了解 ARM 程序是如何从 ROM 中的 image 到达实际运行状态的。实际上, RO 中的指令(启动程序)至少应该有这样的功能:
- 将 RW 从 ROM 中搬到 RAM 中,因为 RW 是变量,变量不能存在 ROM 中。
- 将 ZI 所在的 RAM 区域全部清零,因为 ZI 区域并不在 Image 中,所以需要程序根据编译器给出的 ZI 地址及大小来将相应得 RAM 区域清零。 ZI 中也是变量,同理:变量不能存在 ROM 中。在程序运行的最初阶段, RO 中的指令(启动程序)完成了这两项工作后(也就是分散加载的过程) C 程序才能正常访问变量。否则只能运行不含变量的代码。说了这么多可能还是有些迷糊, RO, RW 和 ZI 到底是什么,下面我将给出几个例子,最直观的来说明 RO, RW, ZI在 C 语言中的含义。
1.5.3 RO 段
看下面两段程序,它们之间差了一条语句,这条语句就是声明一个字符常量。因此按照之前的内容,它们之间应该只会在 RO 数据中相差一个字节(字符常量为 1 字节)。
Prog1:
#include <stdio.h>
void main(void)
{
;
}
Prog2:
#include <stdio.h>
const char a = 5;
void main(void){
;
}
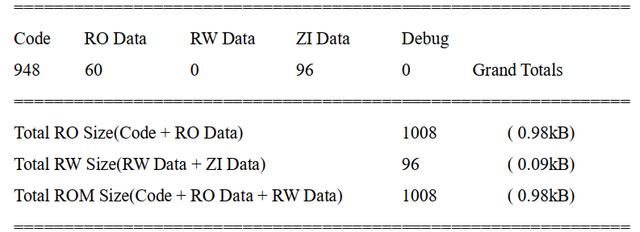
Prog1 编译出来后的信息如下(来自.map 文件):
Prog2 编译出来后的信息如下(来自.map 文件):

以上两个程序编译出来后的信息可以看出: Prog1 和 Prog2 的 RO 包含了 Code 和 RO Data两类数据。他们的唯一区别就是 Prog2 的 RO Data 比 Prog1 多了 1 个字节。这正和之前的推测一致。如果增加的是一条指令而不是一个常量,则结果应该是 Code 数据大小有差别。
1.5.4 RW 段
同样再看两个程序,它们之间只相差一个“已初始化的变量”,按照之前所讲的,已初始化的变量应该是算在 RW 中的,所以两个程序之间应该是 RW 大小有区别。Prog3:
#include <stdio.h>
void main(void)
{;
}
Prog4:
#include <stdio.h>
char a = 5;
void main(void)
{
;
}
Prog3 编译出来后的信息如下(来自.map 文件):

Prog4 编译出来后的信息如下(来自.map 文件):

以上两个程序编译出来后的信息可以看出: Prog1 和 Prog2 的 RO 包含了 Code 和 RO Data两类数据。他们的唯一区别就是 Prog2 的 RO Data 比 Prog1 多了 1 个字节。这正和之前的推测一致。如果增加的是一条指令而不是一个常量,则结果应该是 Code 数据大小有差别。
1.5.5 ZI 段(初始化为 0 或未初始化的变量)
再看两个程序,他们之间的差别是一个未初始化的变量“a”,从之前的了解中,应该可以推测,这两个程序之间应该只有 ZI 大小有差别。
Prog3:
#include <stdio.h>
void main(void)
{
;
}
Prog4:
#include <stdio.h>
char a;
void main(void)
{
;
}
Prog3 编译出来后的信息如下(来自.map 文件):

Prog4 编译出来后的信息如下(来自.map 文件):

编译的结果完全符合推测,只有 ZI 数据相差了 1 个字节。这个字节正是未初始化的一个字符型变量“a”所引起的。
注意: 如果一个变量被初始化为 0,则该变量的处理方法与未初始化华变量一样放在 ZI区域。即: ARM C 程序中,所有的未初始化变量都会被自动初始化为 0。以上代码是再 ADS 下编译的, keil 环境下与之不同,比如在 keil 下生成 ZI 数据段就必须定义一个大于 8 字节的未初始化或初始化位 0 的变量,且必须在源代码中引用此变量才会在链接的描述文件中看到其生成的 ZI 文件。
1.6 缺省内存映射
对于没有描述内存映射的映像,链接器根据缺省内存映射放置代码和数据。如下图所示。

图 1.9 缺省内存映射
- 创建一个可以在其中执行 C 或 C 程序的环境。这包括:
- 创建一个堆栈;
- 创建一个堆(如果需要);
- 初始化程序所用的库的部分组成内容;
- 调用 main()以开始执行程序;
- 支持程序使用 ISO 定义的函数;
- 捕获运行时错误和信号,如果需要,还可以在出现错误或程序退出时终止执行。
注意:这个内存映射并非对所有芯片都有效,不同的芯片的内存映射是不同的。在
Cortex-M3 中的内存映射与上图是一致的。
1.7 内存模型
在 Keil for ARM 下你可以选择以下任意内存模型:
1. 单内存区
堆栈从内存区顶部向下增长。堆从内存区底部向上增长。这是缺省设置。由堆管理的内存从来不会缩减。不能将通过调用 free()释放的堆内存再次用于其他用途。
2. 双内存区
一个内存区用于堆栈,另一个内存区用于堆。堆区大小可以是零。堆栈区可以位于分配的内存中,也可以从执行环境中继承。要使用双区模型而不是缺省的单区模型,请使用以下任一方法:
- 汇编语言中的 IMPORT __use_two_region_memory;
- C 中的#pragma import(__use_two_region_memory)。
例如下图所示,此代码来自 startup_LPC17xx.s。

如果使用双区内存模型,并且未提供任何堆内存,则无法调用 malloc()、使用 stdio 或获取main()的命令行参数。如果将堆区大小设置为 0,并且将__user_heap_extend()定义为可扩展堆的函数,则会在需要时创建堆。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






